In R können Daten auf vielfältige Weise importiert werden. Das Grundproblem beim “Tausch” von Daten zwischen verschiedenen Anwendungen (z.B. SPSS oder Statistica) liegt im verwendeten Format. So können native SPSS-Dateien nur mit einem Zusatzpaket importiert werden, für Statistica gibt es ein solches Zusatzpaket (derzeit) nicht. In beiden Fällen ist es aber möglich, die Daten über das CSV-Format zu tauschen. Hierfür speichert man in SPSS den Datensatz als CSV-Datei ab und liest diese in R ein.
Bedenken Sie ebenfalls, dass R Dezimalstellen mit einem Punkt angibt, und nicht mit einem Komma. So kann es zu Fehlern kommen, wenn die zu importierenden Werte nicht ebenfalls die Dezimalstellen mit einem Punkt angeben! Dies ist ein weiterer häufiger Anfängerfehler!
14.1 Import aus Textdateien
In einer Textdatei (mit Dateiendung .txt) liegen unsere Daten wie folgt vor:
m 28 80 170
w 18 55 174
w 25 74 183
m 29 101 190
m 21 84 185
w 19 74 178
w 27 65 169
w 26 56 163
m 31 88 189
m 22 78 184
Angenommen, diese Textdatei hieße Datentabelle.txt, und läge in unserem Arbeitsverzeichnis, dann können wir die Daten mit der Funktion read.table() in R einlesen.
# importiere Daten aus "Datentabelle.txt" MeineTabelle <-read.table("data/Datentabelle.txt", header=TRUE)# ausgeben MeineTabelle
## Geschlecht Alter Gewicht Groesse
## 1 m 28 80 170
## 2 w 18 55 174
## 3 w 25 74 183
## 4 m 29 101 190
## 5 m 21 84 185
## 6 w 19 74 178
## 7 w 27 65 169
## 8 w 26 56 163
## 9 m 31 88 189
## 10 m 22 78 184
Liegt die Datei im Internet, kann die Adresse mit der Funktion url() übergeben werden.
# importiere Daten aus "Datentabelle.txt" MeineTabelle <-read.table(url("https://www.produnis.de/R/data/Datentabelle.txt"), header=TRUE)# ausgeben MeineTabelle
## Geschlecht Alter Gewicht Groesse
## 1 m 28 80 170
## 2 w 18 55 174
## 3 w 25 74 183
## 4 m 29 101 190
## 5 m 21 84 185
## 6 w 19 74 178
## 7 w 27 65 169
## 8 w 26 56 163
## 9 m 31 88 189
## 10 m 22 78 184
Der Parameter header=TRUE gibt an, dass in der ersten Zeile der Textdatei die Spaltennamen (Variablennamen) angegeben sind.
Da wir sonst keine Parameter übergeben haben, geht R davon aus, dass die Werte durch ein Leerzeichen getrennt sind, was in unserem Beispiel auch stimmt. Sollte die Tabelle in diesem Format vorliegen (die Daten sind mit einem Komma getrennt) …
…dann müssen wir mit der Option sep (für Datenseparator) angeben, dass die Daten mit einem Komma getrennt sind.
# importiere Daten aus "Datentabelle.txt" # Daten sind mit Komma getrennt MeineTabelle <-read.table("Datentabelle.txt", sep=",", header=TRUE)
In beiden Fällen wurde die Texttabelle als Datenframe in R importiert. Die Funktion class() bestätigt uns dies.
# welche Datenklasse wurde erzeugt? class(MeineTabelle)
## [1] "data.frame"
Aber welche Datentypen wurden in den Spalten erzeugt?
# welcher Datentyp liegt in Spalte 1 vor? class(MeineTabelle[,1])
## [1] "character"
# welcher Datentyp liegt in Spalte "Alter" vor?class(MeineTabelle$Alter)
## [1] "integer"
Die Spalte Geschlecht wurde als character angelegt, die Variable Alter ist numerisch.
Möchten wir Geschlecht in einen Faktor umwandeln, ``überschreiben’’ wir einfach die Spalte entsprechend:
# "Geschlecht" soll factor werdenMeineTabelle$Geschlecht <-factor(MeineTabelle$Geschlecht)# überprüfen, ob es geklappt hatclass(MeineTabelle$Geschlecht)
## [1] "factor"
14.2 Import aus CSV-Datei
Das CSV-Format (für comma-separated-values) wird von vielen Anwendungen unterstützt. So können auch Tabellen, die in LibreOffice oder Excel angelegt wurden, als CSV-Datei gespeichert werden. Wenn Sie eine Datei im CSV-Format speichern, fragt Sie Ihre Anwendung nach dem gewünschten Datenseparator, also nach dem Zeichen, durch welches die Werte voneinander getrennt sind. Standardmäßig wird hier ein Komma “,” verwendet (wie der Name CSV vermuten lässt, und was zusätzlich sicherstellt, dass die zu importierenden Daten ihre Dezimalstellen mit einem Punkt abbilden, denn sonst würde nach jedem Dezimalkomma ein neuer Wert beginnen!) oder ein Semikolon “;” . Ich persönlich verwende gerne das Semikolon.
Der Import in R erfolgt ebenfalls über die Funktion read.table(). Neben dem Parameter header muss ihr der eingestellte Datenseparator übergeben werden.
Angenommen, die CSV-Datei hieße DieDaten.csv, läge in unserem Arbeitsverzeichnis und hätte den Datenseparator “;”, dann erfolgt der Import per read.table() mit dem Befehl:
# importiere Daten aus "DieDaten.csv" NeueTabelle <-read.table("data/DieDaten.csv", sep=";", header=TRUE)
Liegt die Datei im Internet, kann die Adresse per url() Funktion übergeben werden.
# importiere Daten aus dem Internet NeueTabelle <-read.table(url("http://www.produnis.de/R/data/DieDaten.csv"), sep=";", header=TRUE)# anzeigen NeueTabelle
## Name Geschlecht Lieblingsfarbe Einkommen
## 1 Hans maennlich gruen 1233
## 2 Caro weiblich blau 800
## 3 Lars intersexuell gelb 2400
## 4 Ines weiblich schwarz 4000
## 5 Samira weiblich gelb 899
## 6 Peter maennlich gruen 1100
## 7 Sarah weiblich blau 1900
Sollte die CSV-Datei mit dem Datenseparator TAB (für Tabulator) erstellt worden sein, lautet der Befehl:
# importiere Daten # Daten sind mit TAB separiert! NeueTabelle <-read.table("DieDaten.csv", sep="\t", header=TRUE)
(Separieren Sie Ihre eigenen Daten möglichst niemals mittels Tabulator, da es hier zu ungewollten Effekten kommen kann.)
Sollte read.table() keine brauchbaren Daten erzeugen (z.B. wegen Sonderzeichen in den Daten oder wenn die Daten per TAB separiert wurden), kann auf die Funktion read.csv() zurückgegriffen werden. Letztendlich ruft diese Funktion intern auch “nur” read.table() auf, jedoch mit jeder Menge voreingestellter Parameter.
# importiere Daten mit read.csv() # Daten sind mit TAB separiert!NeueTabelle <-read.csv("DieDaten.csv", sep="\t", header=TRUE)
14.3 Import aus SPSS-Datei
Um native SPSS-Dateien in R zu importieren, müssen zunächste Zusatzpakete installiert werden, siehe hierzu Kapitel 16.
Zum Import von SPSS-Dateien installieren und aktivieren wir das Paket haven.
# installiere das Zusatzpaket "haven" install.packages("haven")
# aktiviere das Paket "haven" library("haven")
Das Paket haven bietet für jeden SPSS-Dateityp die passende Funktion an. Angenommen, die SPSS-Datei hieße “alteDaten.sav” und läge in unserem Arbeitsverzeichnis, dann kann sie mit der Funktion read_sav() in R importiert werden.
Wir sehen, dass die Werte der Spalten gelabelt sind (4=stimme nicht zu, 3=weiß nicht, usw.). Die Labels stehen in eckigen Klammern neben dem eingentlichen Wert der Variable.
Die enthaltenen Labels kann man sich mit der Funktion attr() anzeigen lassen.
# Namen der Variablen attr(spss, "names")
## [1] "Frage_1" "Frage_2" "Frage_3" "Frage_4"
Das Label einer Variable wird angezeigt mit
# Label der Variablen attr(spss$Frage_1, "label")
## [1] "Statistik ist mein Lieblingsfach?"
Die Labels innerhalb einer Variable mit
# Label der Variablenwerte für "Frage_1"attr(spss$Frage_1, "labels")
## nicht vorhanden stimme gar nicht zu stimme nicht zu weiß nicht
## 0 1 2 3
## stimme zu stimme voll zu
## 4 5
In R ist die Verwendung von Wertelabels eher untypisch. Es empfiehlt sich, die Ausprägungsstufen so wie sie sind als Werte einzutragen, also z.B. direkt “männlich” - “weiblich” - “divers” anstatt 0 - 1 - 2 und anschließender Labelung. So werden die Ausprägungen auch auf den Grafiken entsprechend “aussagekräftig” angezeigt.
Wir wandeln die Variablen in Faktoren um, welche die Labels als Levelnamen nutzen (die Funktion mutate() wird später im Abschnitt Tidyverse (siehe Kapitel 24) genauer erläutert. Der Punkt innerhalb der as_factor()-Funktion bedeutet, dass der Datenstrom der Pipe verwendet werden soll).
## # A tibble: 1,000 × 4
## Frage_1 Frage_2 Frage_3 Frage_4
## <fct> <fct> <fct> <fct>
## 1 stimme zu stimme zu stimme zu nicht vorhanden
## 2 stimme zu stimme zu stimme zu nicht vorhanden
## 3 stimme zu stimme zu stimme zu nicht vorhanden
## 4 stimme zu weiß nicht weiß nicht stimme zu
## 5 weiß nicht weiß nicht stimme nicht zu stimme nicht zu
## 6 stimme nicht zu weiß nicht weiß nicht stimme nicht zu
## # ℹ 994 more rows
Weitere Informationen zum Umgang mit gelabelten Datensätzen erhalten Sie im Tidyverse-Abschnitt zum Datenimport (siehe Abschnitt 25.1).
14.4 Import aus Excel-Datei
Um xlsx-Dateien in R zu importieren, muss das Zusatzpakete readxl installiert werden. Der Datenimport erfolgt dann mit der Funktion read_excel():
# installiere das Zusatzpaket "readxl" install.packages("readxl")
Soll ein bestimmtes Tabellenblatt der xlsx-Datei importiert werden, kann diese mit dem Parameter sheet übergeben werden.
# importiere Tabelle "Tabelle1" aus Excel-Datei "alteDaten.xlsx"alteDaten <-read_excel("alteDaten.xlsx", sheet="Tabelle1")
Soll nur ein bestimmter Bereich der Tabelle importiert werden, kann diese mit dem Parameter range übergeben werden.
# importiere aus Excel-Datei "alteDaten.xlsx" # Tabellenblatt "Tabelle1" # im Bereich A2 bis D3 alteDaten <-read_excel("alteDaten.xlsx", sheet="Tabelle1", range="A2:D3")
14.5 Import aus .ods-Datei
Um ods-Dateien (z.B. aus Libreoffice oder OpenOffice) in R zu importieren, muss das Zusatzpakete readODS installiert werden. Der Datenimport erfolgt dann mit der Funktion read_ods():
# installiere das Zusatzpaket "readODS"install.packages("readODS")# aktiviere das Paket "readODS" library("readODS")# importiere ods-Datei "tolleDaten.ods" tolleDaten <-read_ods("tolleDaten.ods")
Soll ein bestimmtes Tabellenblatt der ods-Datei importiert werden, kann diese mit dem Parameter sheet übergeben werden.
# importiere Tabelle "Tabelle1" aus ods-Datei "cooleDaten.ods"cooleDaten <-read_ods("cooleDaten.ods", sheet="Tabelle1")
Soll nur ein bestimmter Bereich der Tabelle importiert werden, kann diese mit dem Parameter range übergeben werden.
# importiere aus ods-Datei "cooleDaten.ods" # Tabellenblatt "Tabelle1" # im Bereich A2 bis D3 alteDaten <-read.ods("cooleDaten.ods", sheet="Tabelle1", range="A2:D3")
14.6 Import mit RStudio
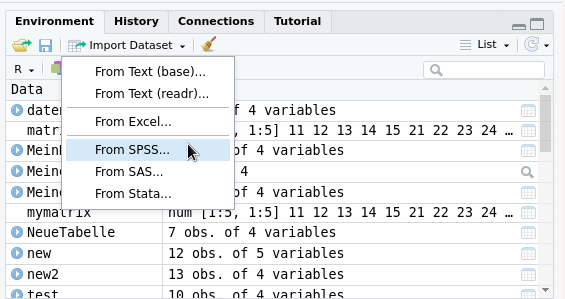
Mit RStudio können Daten sehr leicht importiert werden. Im Datenfenster klicken Sie oben auf Import Dataset.
Es öffnet sich ein kleines Fenster, in welchem Sie das gewünschte Import-Format auswählen können (Abbildung 14.1). Wie Sie sehen, werden native Dateien aus Excel, SPSS, SAS und Stata unterstützt.
Abb. 14.1: importiere Daten
Wir nehmen in diesem Beispiel From SPSS.
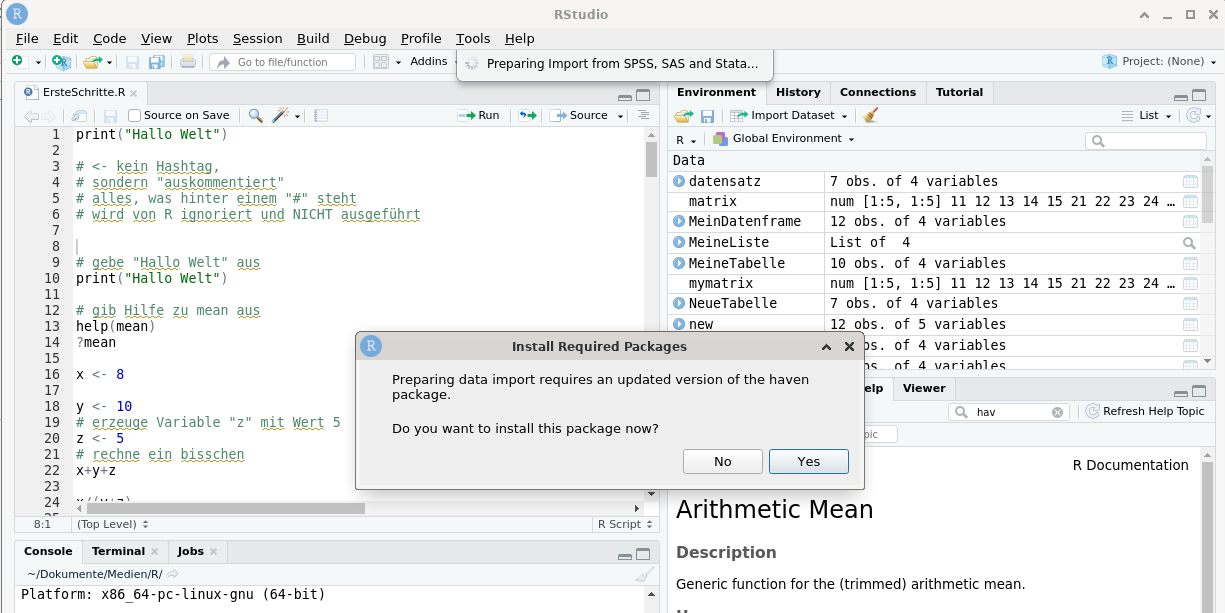
Da der Datenimport das Zusatzpaket haven erfordert, wird es zur Installation vorgeschlagen, sofern es noch nicht installiert ist (Abbildung 14.2). Wir bestätigen in diesem Fall mit Yes.
Abb. 14.2: Zusatzpakete installieren
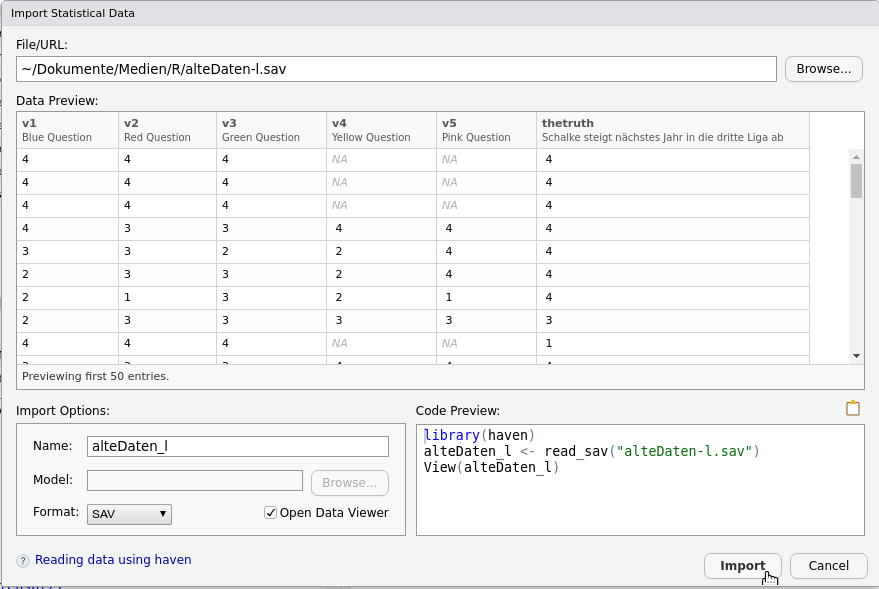
Nun öffnet sich das eigentliche Importierfenster (Abbildung 14.3).
Abb. 14.3: Importfenster
Klicken Sie oben rechts auf den Browse-Knopf und wählen Sie die SPSS-Datei aus, die Sie importieren möchten. Für Abbildung 14.3 habe ich die Datei alteDaten-I.sav in meinem Arbeitsverzeichnis ausgewählt. Sobald Sie eine Datei ausgewählt haben, wird unter Data Preview eine Vorschau des zu importierenden Datensatzes angezeigt. Wie Sie sehen hat mein alter Datensatz die Variablen v1, v2, v3 , usw.
Darunter sehen Sie die Ausprägungen der Variablen.
Unter dem Vorschaufenster können Sie im linken Abschnitt (Import Options) den Objektnamen eintragen, den der Datensatz in R haben soll. Ich habe in Abbildung 14.3 den Namen alteDaten_l gewählt. Das Format ist schon automatisch auf SAV eingestellt (denn der Dateiname endet mit .sav). Der Haken bei Open Data Viewer bewirkt, dass der Datensatz nach dem Import im Scritpfenster angezeigt wird.
Im rechten Abschnitt (Code Preview) sehen Sie die R-Befehle, die in der Konosle ausgeführt werden, um den Import durchzuführen.
Klicken Sie unten rechts auf Import.
14.7 Importierte Daten ins richtige Format bringen
In R werden Dezimalstellen mit einem Punkt angegeben. Dies kann beim Importieren von Daten Probleme bereiten, insbesondere dann, wenn die zu importierenden Daten ihre Dezimalstelle mit einem Komma angeben.
Als Beispiel soll folgende CSV-Tabelle dienen. Sie enthält die beiden Variablen Anwesenheit und Note (mehr Informationen gibt es hier im Blogpost).
Mittels read.table() in Kombination mit url() lesen wir die CSV-Datei in unsere R-Session.
Die Daten sind als chr eingelesen worden. Mit der Funktion as.numeric() können wir solche Daten in numeric umwandlen, eigentlich…
dummy <-c("1", "5", "9", "18")# anzeigendummy
## [1] "1" "5" "9" "18"
# wandle chr in numeric um:as.numeric(dummy)
## [1] 1 5 9 18
Bei den zuvor importierten Daten funktioniert dies aber nicht:
as.numeric(df$Anwesenheit)
## Warning: NAs durch Umwandlung erzeugt
## [1] NA NA 100 NA 0 100 NA NA NA NA NA 100 50 NA NA 100 100 50 NA
## [20] NA NA NA NA NA NA 80 NA
Das liegt an der Dezimaltrennung per Kommata. Wir müssen zunächst alle Kommata in Punkte umwandeln. Dies erfolgt mit der Funktion gsub(), die als Parameter den zu suchenden Wert gefolgt vom zu ersetzenden Wert entgegennimmt.
# ersetze alle Kommata durch Punkte# in df$Notegsub(",", ".", df$Note)
große Schlarmann, J. (2025a). Grundlagen der Statistik. Einführung in die deskriptive und inferentielle Statistik. Hochschule Niederrhein. https://www.produnis.de/manual
große Schlarmann, J. (2025c). trainingslageR. Ein Übungsbuch für R-Einsteiger*innen und Fortgeschrittene. Hochschule Niederrhein. https://www.produnis.de/trainingslager