Das Paket {dplyr} bietet zahlreiche Funktionen, die den Umgang mit Datensätzen erleichtern.
27.1 Daten filtern und sortieren
Mit der Funktion filter() kann der Datensatz nach Kriterien gefiltert werden. Beachten Sie, dass die Funktion mit stats::filter() kollidiert. Rufen Sie sie daher sicherheitshalber mit dplyr::filter() auf.
pf8 %>%# Nur Daten von Personen jünger 40 dplyr::filter(Alter<40) %>%glimpse()
Beachten Sie, dass wir doppelte Gleichheitszeichen (==) verwenden müssen, da mit einem Gleichheitszeichen (=) Variablen zugewiesen werden (so wie mit <-).
Möchte man nach mehreren bestimmten Werte filtern, kann der %in% Operator verwendet werden. Hierdurch übergeben Sie einen Vektor an möglichen Ausprägungen. Angenommen, Sie möchten nur solche Fälle auswählen, in denen das Alter 20 oder 25 oder 40 Jahre beträgt, lautet der Aufruf:
# nach mehreren Werten filtern# Suche Fälle, die 20 oder 25 oder 40 Jahre alt sindpf8 %>% dplyr::filter(Alter %in%c(20, 25, 40)) %>%head(10)
Die Daten werden zunächst aufsteigend nach Alter sortiert. Gibt es Fälle mit dem selben Alter, wird nach dem zweiten Kriterium (in diesem Falle Größe) sortiert. Gibt es Fälle mit der selben Größe und dem selben Alter, wird in- nerhalb dieser Gruppe nach Gewicht sortiert.
Für eine absteigende Sortierung muss die Funktion desc() verwendet werden.
Das Ergebnis ist evtl. anders, als Sie es erwarten. Es werden weiterhin 5 Fälle angezeigt, obwohl n auf 3 gesetzt wurde. Das liegt daran, dass 5 Fälle das kleinste Gewicht haben, und diese werden vollständig angezeigt. Intern ist n dabei auf 5 angewachsen, weshalb keine zweit-kleinsten Gewichte mehr ausgegeben werden.
Lassen wir uns die Älteste Probanden auswählen.
pf8 %>%# zeige die ältesten slice_max(Alter, n=2) %>%glimpse()
Die Tabelle besteht zwar aus 2 Fällen, aber beide Fälle haben das selbe Alter. Die zweit-ältesten werden nicht mit angezeigt, da n intern bereits auf 2 angewachsen ist.
Wir eröhen n auf 3:
pf8 %>%# zeige die ältesten slice_max(Alter, n=3)%>%glimpse()
Jetzt haben wir insgesamt 4 Fälle. Es werden zuerst die ältesten angezeigt. Da es 2 Fälle sind, steigt n intern auf 2 an. Da wir n mit 3 aufgerufen haben, ist noch “Platz” für die zweit-ältesten. Da dies ebenfalls 2 Fälle sind, werden beide ausgegeben. Insgesamt sehen wir also 4 Fälle, obwohl wir n mit 3 aufgerufen haben.
Ähnlich wie head() und tail() zeigen slice_head() und slice_tail() die ersten bzw. letzten Fälle an.
pf8 %>%drop_na() %>%# Gruppiere nach Geschlechtgroup_by(Geschlecht) %>%# sortiere nach Alterarrange(desc(Alter)) %>%# zeige die ersten 3 Fälle pro Gruppeslice(1:3)
Variablen können mit der Funktion bind_cols() hinzugefügt werden. Dabei muss die Länge der enthaltenen Werte mit der Länge des tibble übereinstimmen, ansonsten wiederholt R die Wertereihe so lange, bis sie mit der Länge des tibble übereinstimmt.
pf8 %>%# Fügt eine Variable "test" hinzu, in der alle Werte TRUE sind.bind_cols(test =TRUE) %>%glimpse()
Unsere neue Variable test sehen wir ganz unten. Alle Werte stehen auf TRUE.
27.4 Fälle hinzufügen
Neue Fälle können mit der Funktion bind_rows() hinzugefügt werden. Dies klappt nur, wenn die neuen Fälle als tibble vorliegen, das über die selben Variablen verfügt wie der Originaldatensatz. Die Reihenfolge der Spalten ist egal, da über die Spaltennamen gematcht wird.
Wichtig ist jedoch, dass innerhalb der Variablen auch der selbe Datentyp (numerisch, faktor, logisch) vorliegt, da ansonten die Datentypen auf den kleinsten gemeinsamen Nenner (character) zurückfallen. Wir machen es hier einmal falsch:
# erzeuge neuen Fall# ohne Angabe des Datentypsneu <-tibble("Internet", 44, "weiblich", 166, 70, NA, "Pilot", "verheiratet", 0, "ländlich","ja")# kopiere die Spaltennamencolnames(neu) <-colnames(pf8)# füge zum Datensazu hinzu# Achtung, zerschießt die Datentypen des tibble!pf8 %>%bind_rows( neu ) %>%tail()
## Standort Alter Geschlecht Größe Gewicht Bildung Beruf Familienstand Kinder
## 727 Internet 19 weiblich 158 58 <NA> ledig 0
## 728 Internet 37 weiblich 160 59 <NA> verheiratet 1
## 729 Internet 56 männlich 185 79 <NA> Partnerschaft 0
## 730 Internet 20 weiblich 168 58 <NA> ledig 0
## 731 Internet 40 männlich 183 78 <NA> verheiratet 2
## 732 Internet 44 weiblich 166 70 <NA> Pilot verheiratet 0
## Wohnort Rauchen SportHäufig SportMinuten SportWie SportWarum
## 727 städtisch nein 7.0 10 Allein <NA>
## 728 ländlich nein 3.0 60 Allein <NA>
## 729 ländlich nein 2.0 90 Gruppe <NA>
## 730 städtisch nein 1.0 60 Allein <NA>
## 731 städtisch ja 2.5 120 Gruppe <NA>
## 732 ländlich ja NA NA <NA> <NA>
## LebenZufrieden
## 727 7
## 728 9
## 729 9
## 730 8
## 731 10
## 732 NA
Unsere Zeile ist ganz unten zu sehen. Die fehlenden Werte wurden mit NA aufgefüllt. Alles scheint gut gelaufen zu sein. Wie ein Blick mit glimpse() jedoch zeigt, haben wir die Datentypen unseres tibbles zerschossen, da unsere hinzugefügte Zeile nicht die korrekten Datentypen beinhaltete.
Um Datenframes oder Tibbles miteinander zu verbinden, stehen neben bind_rows() und bind_cols() die join-Funktionen zur Verfügung. Sie kommen dann zur Anwendung, wenn die Zusammenführung anhand von “Übereinstimmungen” erfolgen soll.
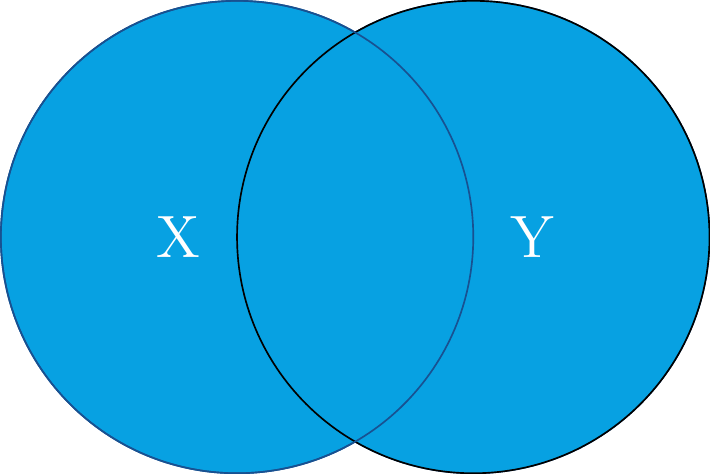
Stellen wir uns die beiden Datenframes X und Y vor.
zwei Datenframes X und Y
Lassen Sie uns nun zwei konkrete Testdatensätze für X und Y erzeugen.
Das Tibble patient soll Daten über 10 Testpatienten enthalten.
Es ist erkennbar, dass patient$Diagnose und nanda$Code Daten über das selbe Item beinhalten (in vielen Projekten wird eine eindeutige ID vergeben, über die später referenziert werden kann). Diese Spalten können wir also nutzen, um beim Verschmelzen die jeweiligen Datenreihen der beiden Tibbles einander zuordnen zu können. Dies haben wir schon bei der merge()-Funktion so gemacht, siehe Abschnitt 8.4.3. Im Tidyverse muss diese Information mittels join_by( X$Spalte == Y$Spalte) an die join-Funktionen übergeben werden. In userem Beispiel würde die Übereinstimmung wie folgt festgelegt: join_by(Diagnose==Code).
Die eigentliche Zusammenführung kann dann auf verschiedene Arten erfolgen:
inner_join()
left_join()
right_join()
full_join()
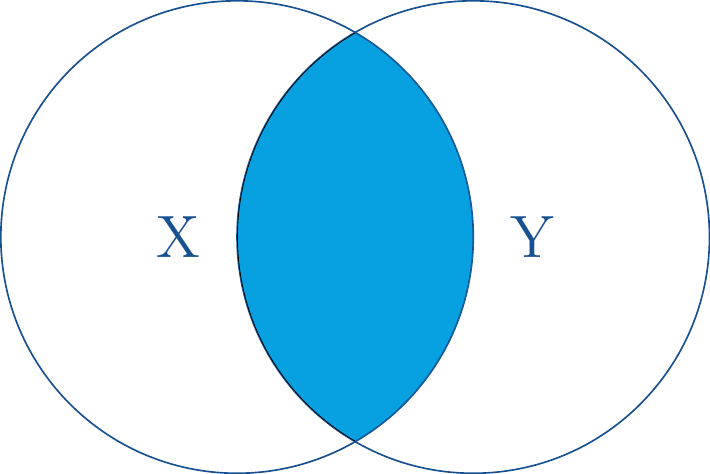
27.5.1inner_join()
Die Funktion inner_join() verschmilzt nur solche Datenreihen aus X und Y, die in den Übereinstimmungsspalten gleiche Werte haben.
inner-join() übernimmt nur übereinstimmende Zeilen
Welcher Datensatz für X oder Y steht entscheidet die Reihenfolge innerhalb des Funktionsaufrufs. Im folgenden Beispiel setzen wir patient als X und nanda als Y.
# behalte nur solche, die matcheninner_join(patient, nanda, join_by(Diagnose == Code))
## # A tibble: 9 × 6
## Patient Alter Geschlecht Diagnose Diagnosetitel Evidenzlevel
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 AB25 51 w 00119 Chronisch geringes Selbstwertg… 3.2
## 2 JA26 61 w 00030 Beeinträchtigter Gasaustausch 3.3
## 3 BG81 44 m 00011 Obstipation 3.1
## 4 ZT42 50 m 00199 Ineffektive Aktivitätenplanung 2.1
## 5 AL63 80 w 00223 Ineffektive Beziehung 2.1
## 6 XV96 88 w 00016 Beeinträchtigte Harnausscheidu… 3.1
## 7 QR49 66 w 00027 Defizitäres Flüssigkeitsvolumen 2.1
## 8 FE31 77 w 00027 Defizitäres Flüssigkeitsvolumen 2.1
## 9 WU53 86 w 00016 Beeinträchtigte Harnausscheidu… 3.1
Das so erzeugte Tibble enthält nur 9 Patientendaten, da der Diagnosecode von Patient PP23 (00098) nicht in der nanda-Liste enthalten ist. Weil aber nur vollständige Matches beibehalten werden, fehlt Patient PP23 in der Ausgabe.
Das Merkmal von inner_join() ist also, dass nur vollständige Datenreihen erhalten bleiben.
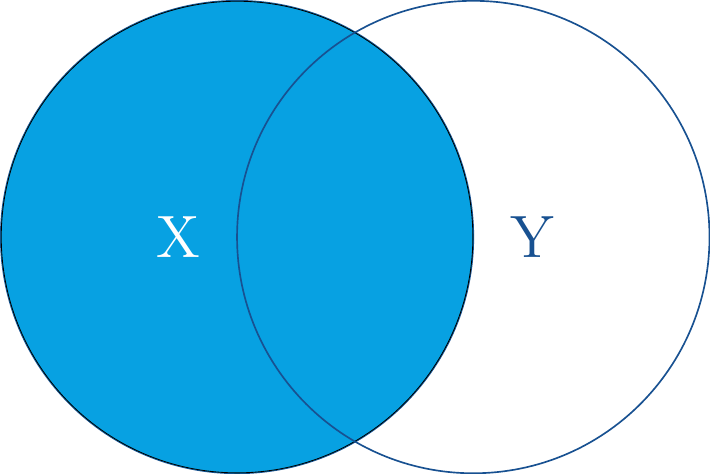
27.5.2left_join()
Die Funktion left_join() behält alle Datenreihen von X, und fügt nur solche Y hinzu, die über die Übereinstimmungsspalte matchen.
left_join() behält alle X und ergänz passende Y
Auch in diesem Beispiel setzen wir patient als X und nanda als Y.
# behalte alle patienten (x), und packe nur# matchende y (NANDA) hinzuleft_join(patient, nanda, join_by(Diagnose == Code))
## # A tibble: 10 × 6
## Patient Alter Geschlecht Diagnose Diagnosetitel Evidenzlevel
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 AB25 51 w 00119 Chronisch geringes Selbstwert… 3.2
## 2 JA26 61 w 00030 Beeinträchtigter Gasaustausch 3.3
## 3 BG81 44 m 00011 Obstipation 3.1
## 4 ZT42 50 m 00199 Ineffektive Aktivitätenplanung 2.1
## 5 AL63 80 w 00223 Ineffektive Beziehung 2.1
## 6 XV96 88 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 7 QR49 66 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 8 FE31 77 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 9 PP23 64 m 00098 <NA> NA
## 10 WU53 86 w 00016 Beeinträchtigte Harnausscheid… 3.1
Alle Patienten (X) sind erhalten geblieben. Da der Diagnosecode von Patient PP23 (00098) nicht in der nanda-Liste (Y) enthalten ist, wurden NAs ergänzt.
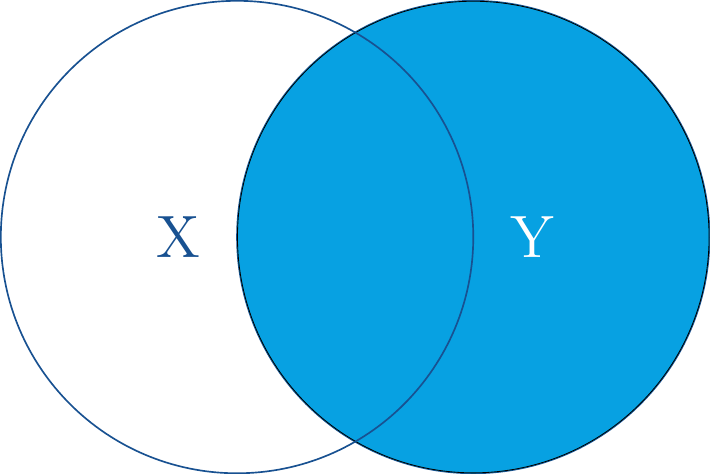
27.5.3right_join()
Die Funktion right_join() ist das spiegelverkehrte Pendant. Sie behält alle Datenreihen von Y, und fügt nur solche X hinzu, die über die Übereinstimmungsspalte matchen.
right_join() behält alle Y und ergänz passende X
# behalte alle NANDA (y) und packe nur# matchende Patienten (x) hinzu# erzeugt doppelte Y, wenn x mehrfach y enthältright_join(patient, nanda, join_by(Diagnose == Code))
## # A tibble: 12 × 6
## Patient Alter Geschlecht Diagnose Diagnosetitel Evidenzlevel
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 AB25 51 w 00119 Chronisch geringes Selbstwert… 3.2
## 2 JA26 61 w 00030 Beeinträchtigter Gasaustausch 3.3
## 3 BG81 44 m 00011 Obstipation 3.1
## 4 ZT42 50 m 00199 Ineffektive Aktivitätenplanung 2.1
## 5 AL63 80 w 00223 Ineffektive Beziehung 2.1
## 6 XV96 88 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 7 QR49 66 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 8 FE31 77 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 9 WU53 86 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 10 <NA> NA <NA> 00110 Selbstversorgungsdefizit Toil… 2.1
## 11 <NA> NA <NA> 00108 Selbstversorgungsdefizit Körp… 2.1
## 12 <NA> NA <NA> 00095 Schlafstörung 3.3
Das neue Tibble ist 12 Reihen lang, da zwei Pflegediagnosen (Y) jeweils 2mal im Datensatz patient (X) vorkommen.
Das Ergebnis von right_join() lässt sich prinzipiell auch erreichen, indem innerhalb von left_join() einfach die Werte umgedreht werden. Die Reihenfolge der Spalten und Zeilen im erzeugten Tibble ist dann aber anders, obwohl insgesamt die selben Daten enthalten sind.
# geht auch mit left_join(),# indem man einfach X und Y vertauscht# join_by() muss ebenfalls vertauscht werdenleft_join(nanda, patient, join_by(Code == Diagnose))
## # A tibble: 12 × 6
## Code Diagnosetitel Evidenzlevel Patient Alter Geschlecht
## <chr> <chr> <dbl> <chr> <dbl> <chr>
## 1 00110 Selbstversorgungsdefizit Toilett… 2.1 <NA> NA <NA>
## 2 00108 Selbstversorgungsdefizit Körperp… 2.1 <NA> NA <NA>
## 3 00027 Defizitäres Flüssigkeitsvolumen 2.1 QR49 66 w
## 4 00027 Defizitäres Flüssigkeitsvolumen 2.1 FE31 77 w
## 5 00011 Obstipation 3.1 BG81 44 m
## 6 00030 Beeinträchtigter Gasaustausch 3.3 JA26 61 w
## 7 00223 Ineffektive Beziehung 2.1 AL63 80 w
## 8 00016 Beeinträchtigte Harnausscheidung 3.1 XV96 88 w
## 9 00016 Beeinträchtigte Harnausscheidung 3.1 WU53 86 w
## 10 00119 Chronisch geringes Selbstwertgef… 3.2 AB25 51 w
## 11 00199 Ineffektive Aktivitätenplanung 2.1 ZT42 50 m
## 12 00095 Schlafstörung 3.3 <NA> NA <NA>
Das neue Tibble ist 12 Reihen lang, da zwei Pflegediagnosen (X) jeweils 2mal im Datensatz patient (Y) vorkommen.
Dieses Verhalten kann über den Parameter multiple bestimmt werden. So lässt sich einstellen, ob aus Y alle (all), nur der erste (first) oder letzte (last), oder irgendein (any) passender Eintrag übernommen werden soll.
# wenn mehrfaches Vorkommen in Y, nimm den letztenleft_join(nanda, patient, join_by(Code == Diagnose),multiple="last")
## # A tibble: 10 × 6
## Code Diagnosetitel Evidenzlevel Patient Alter Geschlecht
## <chr> <chr> <dbl> <chr> <dbl> <chr>
## 1 00110 Selbstversorgungsdefizit Toilett… 2.1 <NA> NA <NA>
## 2 00108 Selbstversorgungsdefizit Körperp… 2.1 <NA> NA <NA>
## 3 00027 Defizitäres Flüssigkeitsvolumen 2.1 FE31 77 w
## 4 00011 Obstipation 3.1 BG81 44 m
## 5 00030 Beeinträchtigter Gasaustausch 3.3 JA26 61 w
## 6 00223 Ineffektive Beziehung 2.1 AL63 80 w
## 7 00016 Beeinträchtigte Harnausscheidung 3.1 WU53 86 w
## 8 00119 Chronisch geringes Selbstwertgef… 3.2 AB25 51 w
## 9 00199 Ineffektive Aktivitätenplanung 2.1 ZT42 50 m
## 10 00095 Schlafstörung 3.3 <NA> NA <NA>
Ausgangspunkt für den Parameter multiple ist immer Datensatz X. Im letzten Beispiel wurde nanda als X angegeben. Da jeder Diagnosecode in nanda genau einmal vorkommt, ist das neue Tibble 10 Reihen lang. Sollte in Y (patient) die Diagnose mehrfach vorkommen, wird (im Beispiel oben) die letzte vorkommende Datenreihen aus Y verwendet.
Kehren wir zum ursprünglichen right_join()-Aufruf zurück und übergeben den Parameter
## # A tibble: 12 × 6
## Patient Alter Geschlecht Diagnose Diagnosetitel Evidenzlevel
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 AB25 51 w 00119 Chronisch geringes Selbstwert… 3.2
## 2 JA26 61 w 00030 Beeinträchtigter Gasaustausch 3.3
## 3 BG81 44 m 00011 Obstipation 3.1
## 4 ZT42 50 m 00199 Ineffektive Aktivitätenplanung 2.1
## 5 AL63 80 w 00223 Ineffektive Beziehung 2.1
## 6 XV96 88 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 7 QR49 66 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 8 FE31 77 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 9 WU53 86 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 10 <NA> NA <NA> 00110 Selbstversorgungsdefizit Toil… 2.1
## 11 <NA> NA <NA> 00108 Selbstversorgungsdefizit Körp… 2.1
## 12 <NA> NA <NA> 00095 Schlafstörung 3.3
so ist das Tibble wieder 12 Reihen lang, denn Ausgangspunkt für multiple ist immer Datensatz X (auch bei right_join()). Im Funktionsaufruf oben steht patient als X. Daher schaut die Funktion für jede Reihe in X, ob ein oder mehrere passende Einträge in Y vorhanden sind. Da in Y (nanda) aber jede Diagnose nur einmal definiert wird, kommen keine multiplen Zeilen vor. Der Parameter multiple findet daher keine Anwendung.
Nun will right_join() aber alle Y beibehalten und mit allen passenden X (patient) verschmelzen. Da bei zwei Diagnosen in Y jeweils zwei Patienten aus X matchen, ist die Ausgabe 12 Zeilen lang.
27.5.4full_join()
Beim full_join() werden alle Daten von X und Y beibehalten.
full_join() behält alle X und Y
# behält alle x und alle yfull_join(patient, nanda, join_by(Diagnose == Code))
## # A tibble: 13 × 6
## Patient Alter Geschlecht Diagnose Diagnosetitel Evidenzlevel
## <chr> <dbl> <chr> <chr> <chr> <dbl>
## 1 AB25 51 w 00119 Chronisch geringes Selbstwert… 3.2
## 2 JA26 61 w 00030 Beeinträchtigter Gasaustausch 3.3
## 3 BG81 44 m 00011 Obstipation 3.1
## 4 ZT42 50 m 00199 Ineffektive Aktivitätenplanung 2.1
## 5 AL63 80 w 00223 Ineffektive Beziehung 2.1
## 6 XV96 88 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 7 QR49 66 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 8 FE31 77 w 00027 Defizitäres Flüssigkeitsvolum… 2.1
## 9 PP23 64 m 00098 <NA> NA
## 10 WU53 86 w 00016 Beeinträchtigte Harnausscheid… 3.1
## 11 <NA> NA <NA> 00110 Selbstversorgungsdefizit Toil… 2.1
## 12 <NA> NA <NA> 00108 Selbstversorgungsdefizit Körp… 2.1
## 13 <NA> NA <NA> 00095 Schlafstörung 3.3
27.6 Variablen auswählen
Mit der Funktion select() können Variablen (Spalten) des tibble ausgewählt werden.
# wähle Variablen "Alter", "Größe" und "Gewicht"# aus Datensatz pf8 pf8 %>%select(Alter,Größe,Gewicht) %>%head(.)
In Kombination mit der Funktion everything() kann die Reihenfolge der Variablen im Datensatz geändert werden. Die Funktion everything() hängt alle weiteren Variablen an unsere Auswahl an.
Angenommen, wir möchten Größe und Gewicht “als erstes” sehen, und alle anderen Variablen danach, so lautet der Befehl:
# zeige erst "Größe" und "Gewicht"# und danach alles andere.pf8 %>%select(Größe, Gewicht, everything()) %>%as_tibble()
Mit der Funktion pull() werden die Spaltenwerte als Vektor wiedergegeben
# gib Werte von "Alter" als Vektorpf8 %>%pull(Alter) %>%head(10)
## [1] 18 67 60 61 24 21 59 56 82 52
27.7 Variablen erzeugen
Die Funktion mutate() erlaubt es, neue Variablen (Spalten) zu erzeugen, die durch Interaktion mit den anderen Variablen enstanden sind. So können wir im Datensatz pf8 aus den Variablen Größe und Gewicht den Body-Maß-Index errechnen, und diese Werte als neue Variable (Spalte) speichern.
Mit der Funktion summarise() können “zusammenfassenden Statistiken” berechnet werden. Sie fungiert als eine Art “Vermittlungsfunktion”, um Statistikfunktionen (siehe Kapitel 31) in den Tidyverse-Workflow zu integrieren.
Klassische zusammenfassende Kennzahlen sind Mittelwert (über Funktion mean()), Median (über Funktion median()) und Standardabweichung (über Funktion sd()). Es funktioniert aber auch mit allen anderen Statistikfunktionen. Wir beschränken uns im Weiteren auf diese drei, alle anderen werden in Kapitel @ref(Kapitel-StatistikMitR) vorgestellt.
Berechnen wir mit mean() den Mittelwert für Alter.
# Mittelwert von "Alter"pf8 %>%summarise(Mittelwert =mean(Alter))
## Mittelwert
## 1 NA
Wir erhalten ein NA zurück, weil in der Variable Alter fehlende Werte enthalten sind. Fast alle statistischen Funktionen erwarten von uns, dass NAs weggefilter wurden. Nutzen wir die Macht der Pipe und ändern den Befehl in
# Mittelwert von "Alter"pf8 %>%drop_na() %>%summarise(Mittelwert =mean(Alter))
## Mittelwert
## 1 38.25126
Mit der Funktion group_by() können Gruppierungen vorgenommen werden.
# Gruppiere nach Geschlechtpf8 %>% dplyr::group_by(Geschlecht) %>%drop_na() %>%summarise(Mittelwert =mean(Alter))
Mit der Funktion add_acount() werden die Häufigkeitswerte als eigene Variable im Datensatz gespeichert.
pf8 %>%# Speichere die Levelhäufigkeit als eigene Variableadd_count(Geschlecht, name ="AnzahlGeschlecht") %>%# Zeige diese Variablen als erstes, dann den Restselect(Geschlecht, AnzahlGeschlecht, everything()) %>%# Ausgabe als tibble ist "schöner"as_tibble()
## # A tibble: 731 × 16
## Standort Alter Geschlecht Größe Gewicht Bildung Beruf Familienstand Kinder
## <fct> <int> <fct> <int> <dbl> <fct> <fct> <fct> <int>
## 1 Münster 18 eine Frau 172 69 Abitur Insp… Partnerschaft 0
## 2 Münster 67 eine Frau 165 67 mittlere R… Rent… geschieden 0
## 3 Münster 60 eine Frau 175 NA Hochschule Ergo… Partnerschaft 0
## 4 Münster 61 ein Mann 182 90 mittlere R… Beam… ledig 0
## 5 Münster 24 ein Mann 173 68 Abitur Stud… ledig 0
## 6 Münster 21 eine Frau 177 60 Abitur Stud… Partnerschaft 0
## # ℹ 725 more rows
## # ℹ 7 more variables: Wohnort <fct>, Rauchen <fct>, SportHäufig <dbl>,
## # SportMinuten <dbl>, SportWie <fct>, SportWarum <fct>, LebenZufrieden <dbl>
27.9.2 Levelreihenfolge ändern
Bei kategorialen Daten existiert keine geordnete Reihe der Werte. Dennoch kann es hilfreich sein, kategoriale Levels in eine bestimmte Reihenfolge zu bringen. Über die Hausfunktion factor() können über den Parameter levels die Levelreihenfolgen von Hand geändert werden.
x <-factor(c("vielleicht", "ja", "nein"))x
## [1] vielleicht ja nein
## Levels: ja nein vielleicht
## [1] vielleicht ja nein
## Levels: nein vielleicht ja
Für häufige Anwendungsfälle bietet forcats Funktionen, die uns diese Arbeit abnehmen.
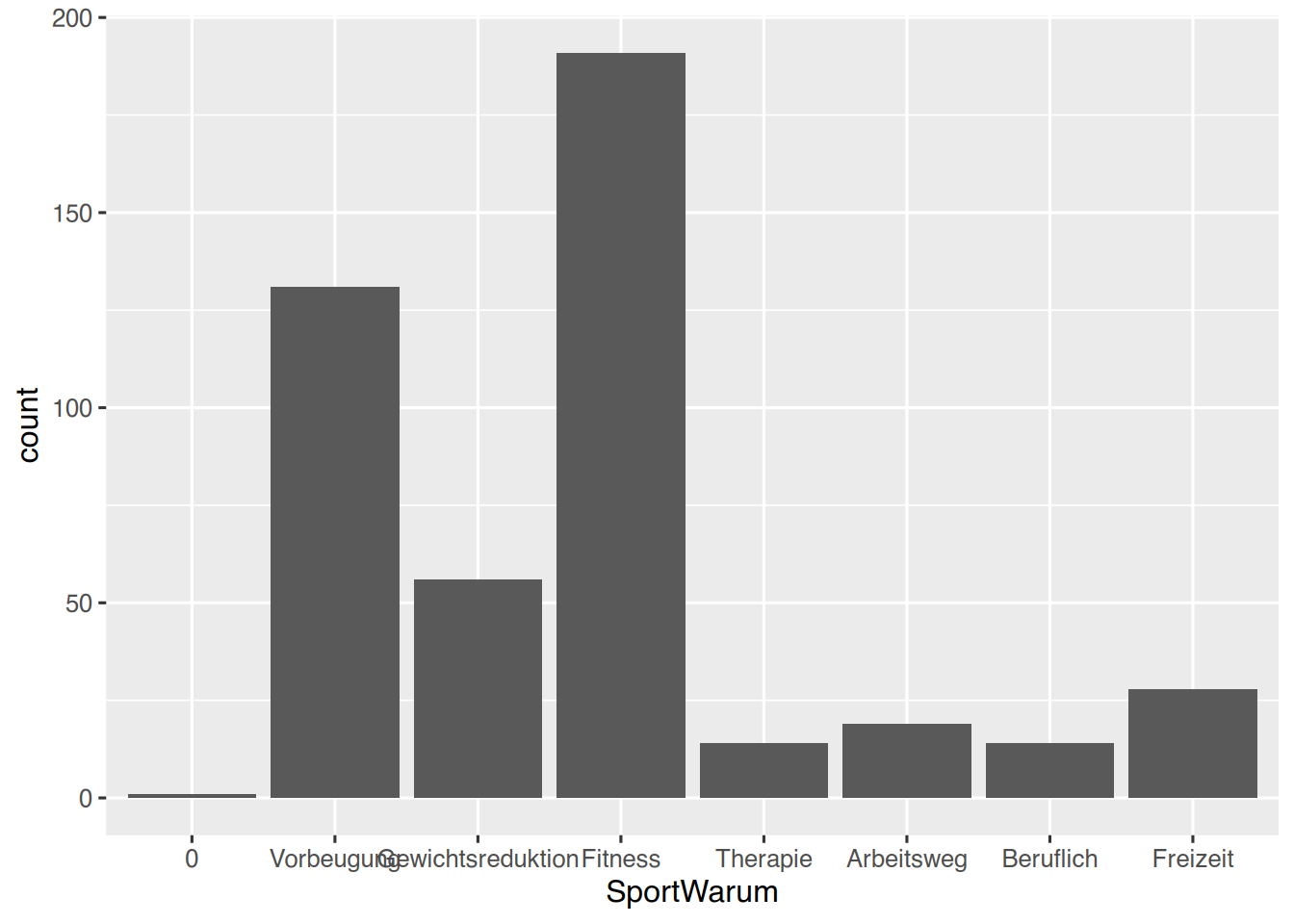
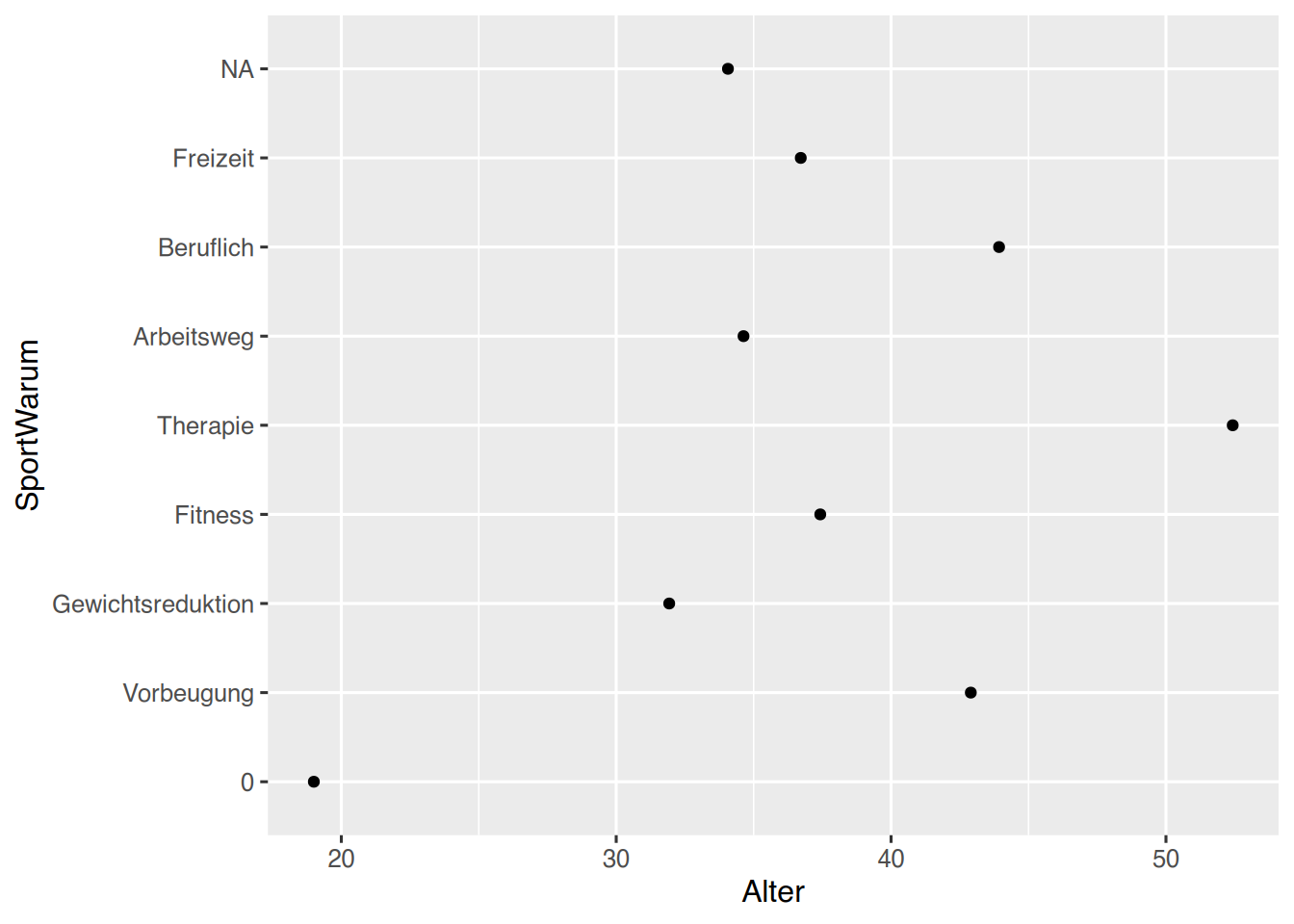
Schauen wir uns im Datensatz pf8 die Anlässe für Sport an. Das Skalenniveau ist nominal. Wenn wir die Daten plotten (zu ggplot siehe Kapitel 35), werden die Daten (die Diagrammsäulen) in der Reihenfolge der Levels angezeigt, und nicht in der Reihenfolge der Häufigkeiten.
pf8 %>%select(SportWarum) %>%drop_na() %>%# dies ist der Plotbefehl, den Sie jetzt noch nicht verstehen.# Lesen Sie das Kapitel zu "ggplot".ggplot(aes(x=SportWarum)) +geom_bar()
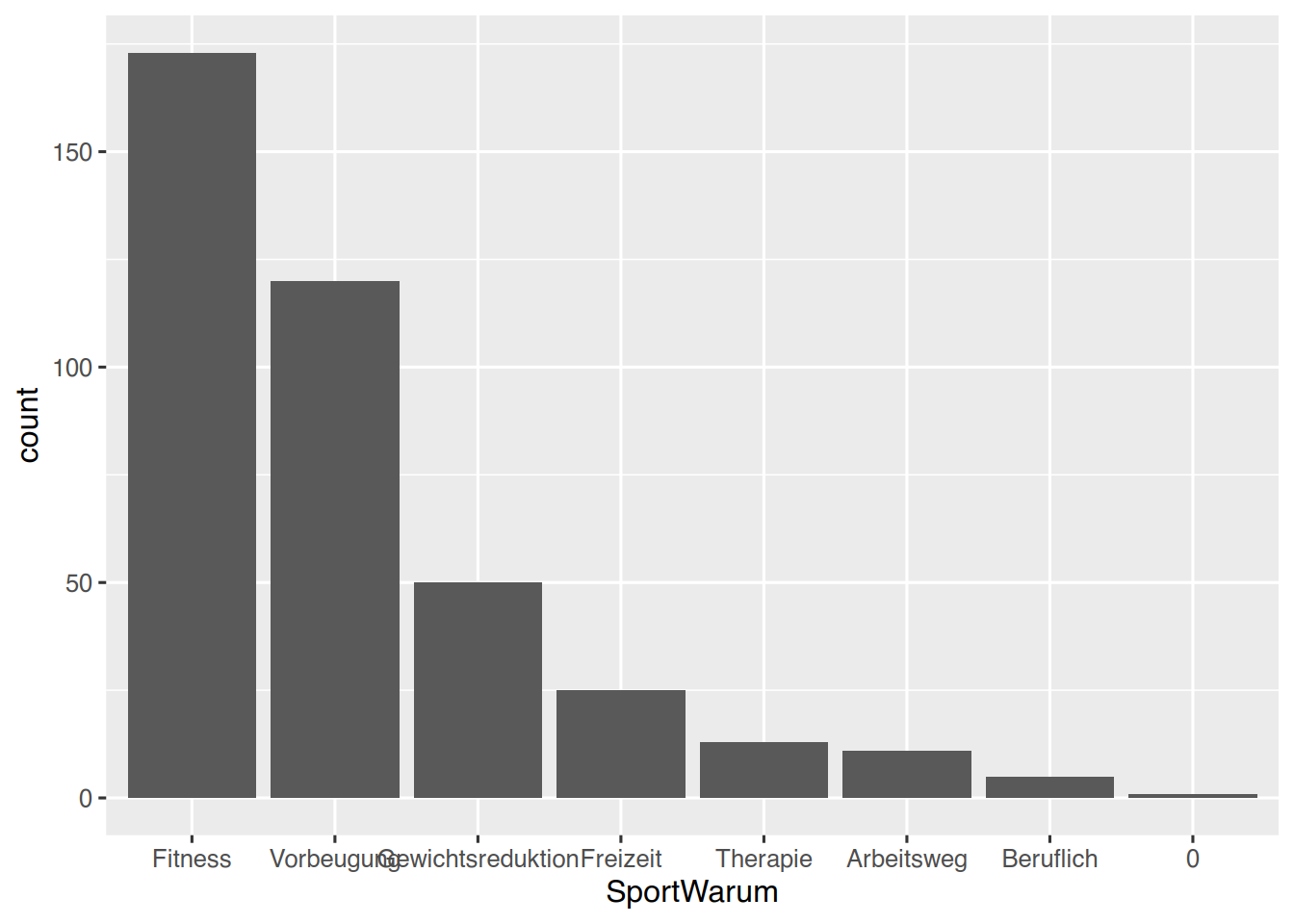
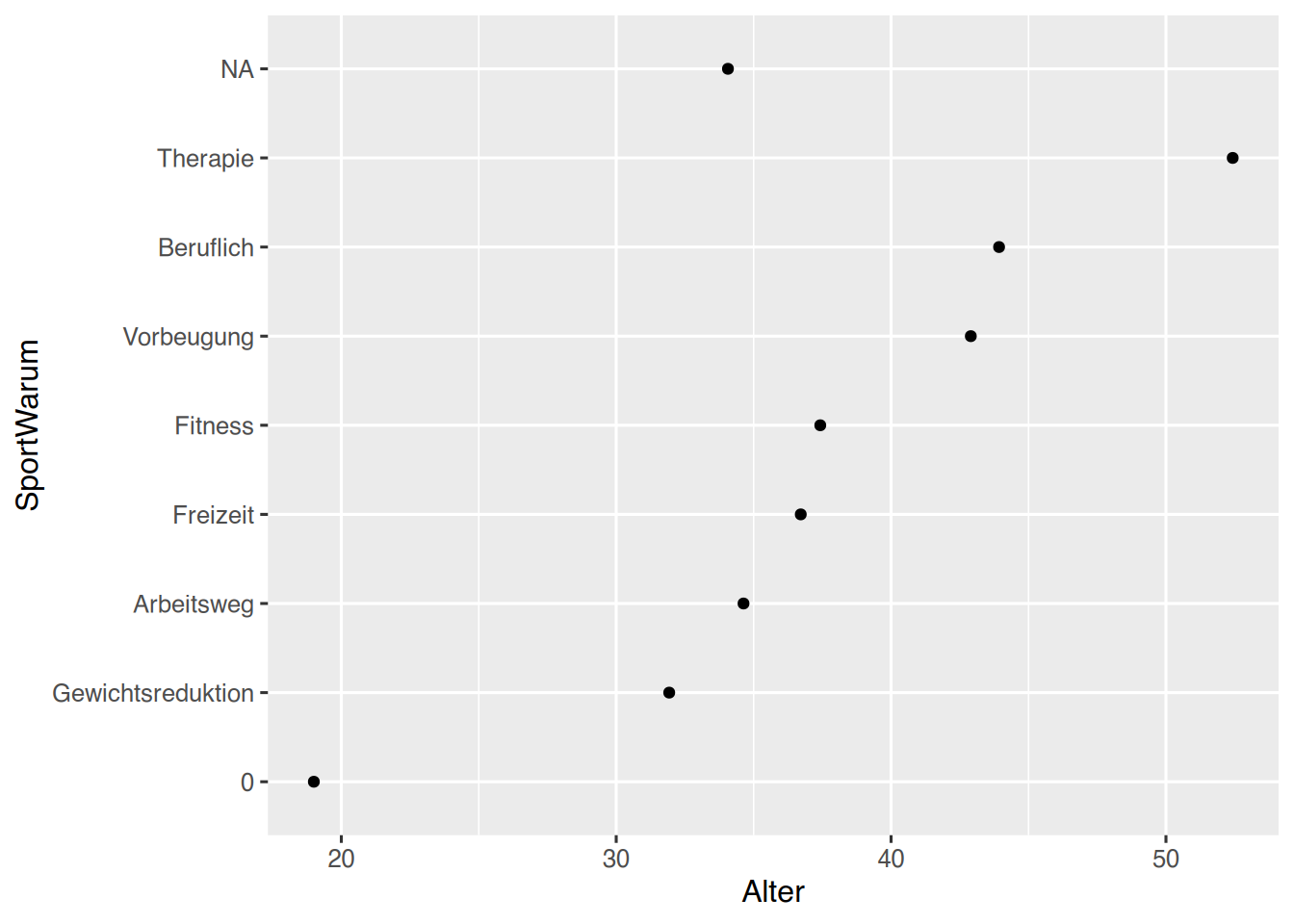
Soll die Reihenfolgde der Levels so verändert werden, dass die mit der höchsten Ausprägung zuerst angezeigt werden, kann die Funktion fct_infreq() verwendet werden.
pf8 %>%drop_na() %>%# Sortiere nach Häufigkeitenmutate(SportWarum =fct_infreq(SportWarum)) %>%# plottenggplot(aes(x=SportWarum)) +geom_bar()
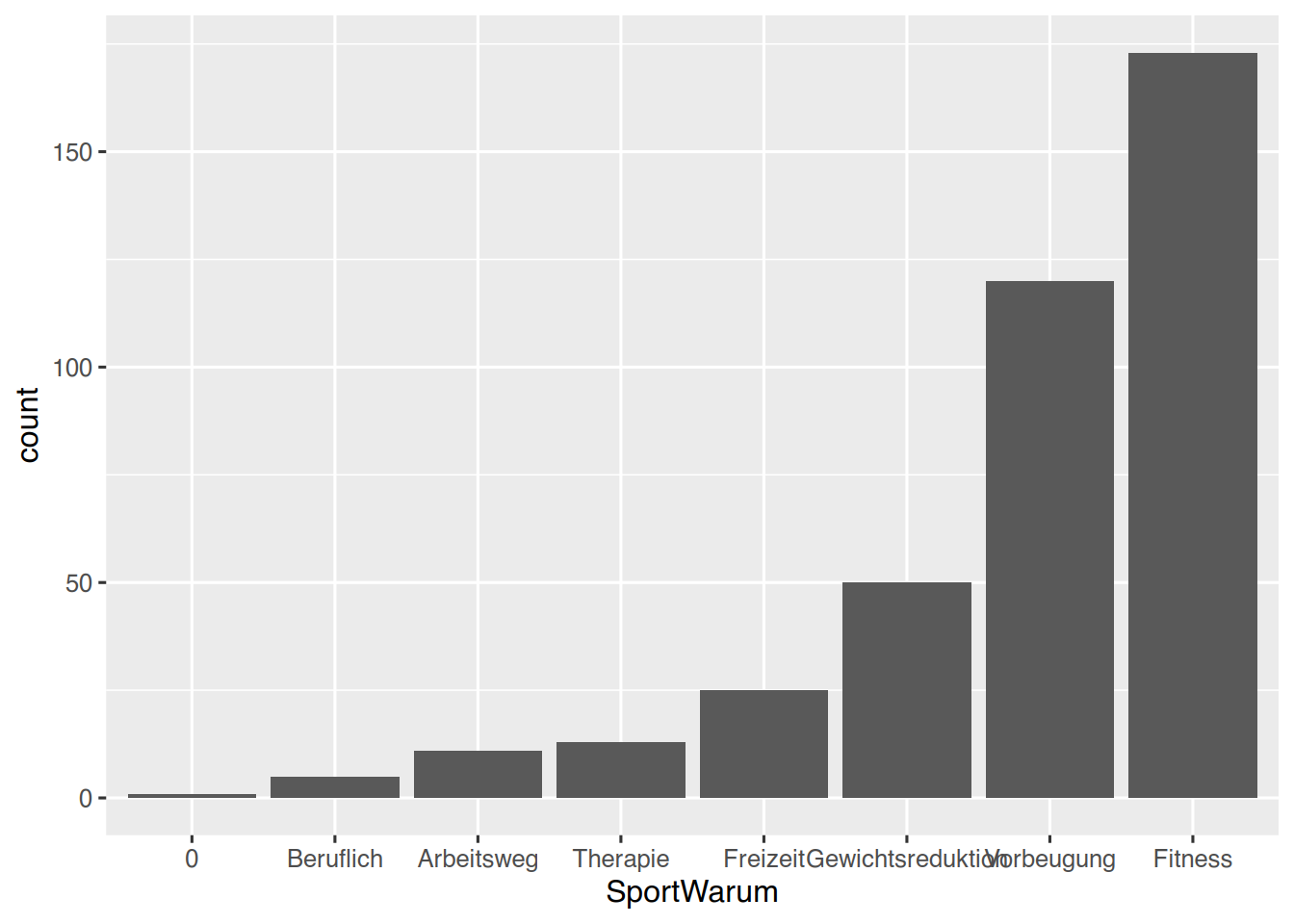
Mit der Funktion fct_rev() wird die Levelreihenfolge umgekehrt.
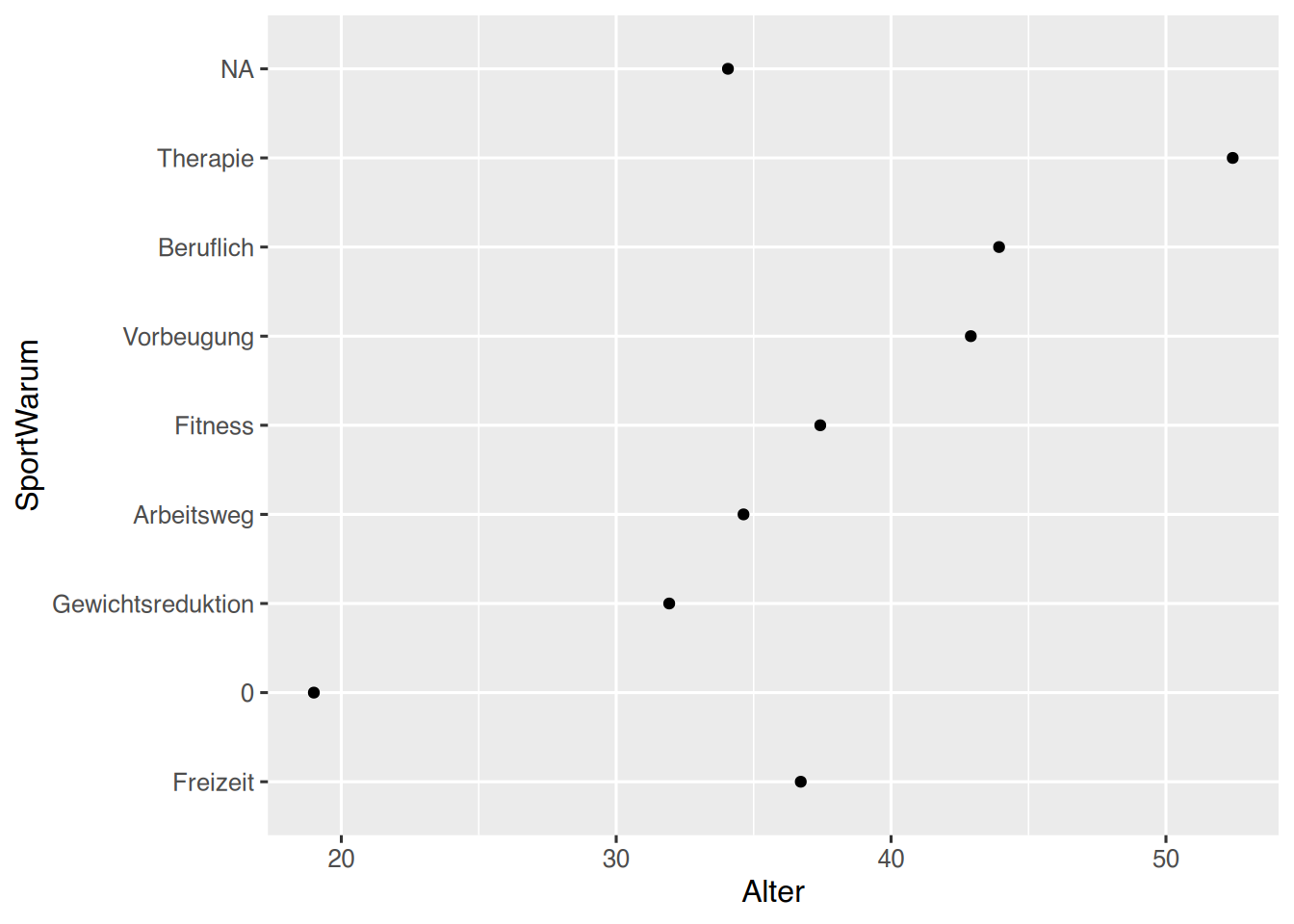
Soll auch hier die Reihenfolge nach Mittelwerten erfolgen, kann die Funktion fct_reorder() verwendet werden.
pf8sub %>%# überschreibe Variable "SportWarum"# ordne die Levels von "SportWarum" nach "Alter"mutate(SportWarum =fct_reorder(SportWarum, Alter)) %>%# plotten ggplot(aes(x=Alter, y=SportWarum)) +geom_point()
Beachten Sie, dass NA weiterhin ganz oben angezeigt werden.
Mit der Funktion fct_relevel() können einzelne Levels “nach vorne” geholt werden. In diesem Beispiel möchten wir, dass der Grund Freizeit als erstes angezeigt wird
pf8sub %>%# überschreibe Variable "SportWarum"# ordne die Levels von "SportWarum" nach "Alter"mutate(SportWarum =fct_reorder(SportWarum, Alter)) %>%# hole Level "Freizeit" nach vornemutate(SportWarum =fct_relevel(SportWarum, "Freizeit")) %>%# plotten ggplot(aes(x=Alter, y=SportWarum)) +geom_point()
Fassen wir nun alle “verpartnerten” und alle “Singles” zu zwei Levels zusammen.
pf8 %>%# fasse Singles und Partner in eigenen Levels zusammenmutate(Partnerschaft =fct_collapse(Familienstand,"Partnerschaft"=c("Partnerschaft", "verheiratet"),"Single"=c("ledig", "geschieden", "verwitwet", "getrennt"))) %>% dplyr::select(Partnerschaft, Familienstand, Alter) %>%as_tibble()
## # A tibble: 731 × 3
## Partnerschaft Familienstand Alter
## <fct> <fct> <int>
## 1 Partnerschaft Partnerschaft 18
## 2 Single geschieden 67
## 3 Partnerschaft Partnerschaft 60
## 4 Single ledig 61
## 5 Single ledig 24
## 6 Partnerschaft Partnerschaft 21
## # ℹ 725 more rows
27.10 Daten klassieren
Angenommen, eine Variable enthält Werte zwischen 0 und 500, und wir möchten diese Werte in die Gruppen “0-70”, “71-200”, “201-400”, “>400” klassieren.
Erstellen wir zunächst zufällige Zahlen zwischen 0 und 500.
# lade tidyverselibrary(tidyverse)# erzeuge 200 Zufallszahlen von 0 bis 500dummy <-sample(0:500, 200)# bzw. direkt als Tibbledummy <-tibble(x =sample(0:500, 200))
27.10.1 mittels ifelse()
Nun erzeugen wir die neue Variable xKAT, in welcher die Klassierung angegeben werden soll. Hierfür nutzen wir innerhalb von mutate() die ifelse()-Funktion. Diese folgte der Logik “WELCHE - WAS -ANSONSTEN”. In einem ersten beispielhaften Schritt wählen wir all “x < 71” aus, speichern für diese Fälle den character-Wert “0-70”, und bei allen anderen Fällen ein “NA”.
dummy %>%# ifelse(WELCHE, WAS, ANSONSTEN)mutate(xKAT =ifelse(x <71 , "0-70", NA))
Es lassen sich mehrere ifelse()-Ausdrücke kombinieren, indem diese vor den NA-Ausdruck geschrieben werden. Dabei sammeln sich die Klammer-Zu Symbole ) an, kommen Sie hier nicht durcheinander!
# Das lässt sich erweitern, indem der ", NA"-Ausdruck nach hinten wandertdummy %>%mutate(xKAT =ifelse(x <71 , "0-70",ifelse(x <201& x >70 , "71-200",NA)))
Der vollständige Befehl zur Klassierung lautet demnach:
# wir bilden Kategorien# "0-70"# "71-200"# "201-400"# "> 400"# und speichern das in die neue Variable xKATdummy %>%mutate(xKAT =ifelse(x <71 , "0-70",ifelse(x <201& x >70 , "71-200",ifelse(x <401& x >200 , "201-400",ifelse(x >400 , "> 400",NA)))))
Wenn - so wie hier - mehrere Konditionen angegeben werden, ist die Funktion case_when() etwas einfacher zu schreiben und zu lesen als die ifelse()-Staffelungen.
# nutze case_when() an Stelle von ifelse()dummy %>%mutate(xKAT =case_when(x <71~"0-70", x <201& x >70~"71-200", x <401& x >200~"201-400", x >400~"größer 400") )
Mit dem Parameter .default kann ein Wert festgelegt werden, der vergeben wird, wenn keine der Bedingungen zutrifft. Standardmäßig werden NAs vergeben.
# nutze case_when() an Stelle von ifelse()dummy %>%mutate(xKAT =case_when(x <71~"0-70", x <201& x >70~"71-200", x <401& x >200~"201-400", x >400~"größer 400",.default="keines davon") )
Anschließend wandeln wir noch die neue Variable in einen ordinalen Faktor mit korrekter Levelreihenfolge.
# die neue Variable als ordinalen Factor mit korrekter# Levelreihenfolge speicherndummy <- dummy %>%mutate(xKAT =case_when(x <71~"0-70", x <201& x >70~"71-200", x <401& x >200~"201-400", x >400~"größer 400",.default="keines davon"),xKAT =factor(xKAT, levels=c("0-70","71-200","201-400","größer 400","keines davon"),ordered=TRUE) )head(dummy$xKAT)
Zum Visualisieren von Daten sind neben Tabellen vor allem Diagramme geeignet. Wie Sie im Tidyverse Diagramme erstellen behandeln wir im Kapitel ggplot, siehe Kapitel 35.
große Schlarmann, J. (2025a). Grundlagen der Statistik. Einführung in die deskriptive und inferentielle Statistik. Hochschule Niederrhein. https://www.produnis.de/manual
große Schlarmann, J. (2025c). trainingslageR. Ein Übungsbuch für R-Einsteiger*innen und Fortgeschrittene. Hochschule Niederrhein. https://www.produnis.de/trainingslager