Die Funktion zur Berechnung linearer Regressionen ist lm() (für “linear model”). Sie folgt der Syntax x erklärt durch y, was durch eine Tilde ~ ausgedrückt wird.
Es ist üblich, Modelle in ein Objekt zu speichern und über die summary()- Funktion aufzurufen. Die Informationen der Modellzusammenfassung sind so detailierter.
# speichere Modell in "fit"fit <-lm(workyear~worknight, data=nw)# schaue mit "summary()" ansummary(fit)
##
## Call:
## lm(formula = workyear ~ worknight, data = nw)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12.889 -5.743 -2.351 3.660 26.427
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 9.91425 0.74088 13.38 <2e-16 ***
## worknight 0.82912 0.05958 13.91 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 7.463 on 274 degrees of freedom
## Multiple R-squared: 0.4141, Adjusted R-squared: 0.4119
## F-statistic: 193.6 on 1 and 274 DF, p-value: < 2.2e-16
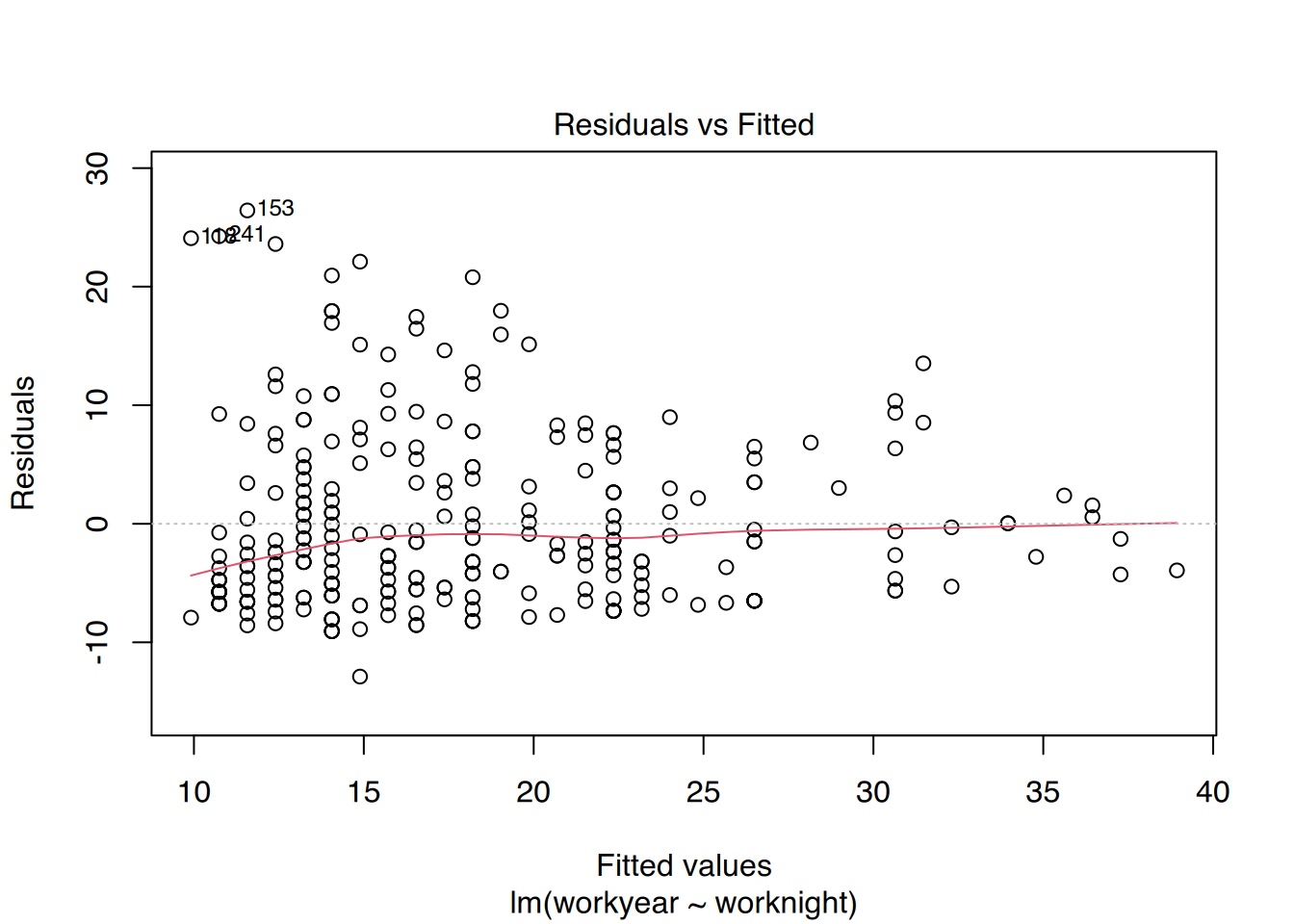
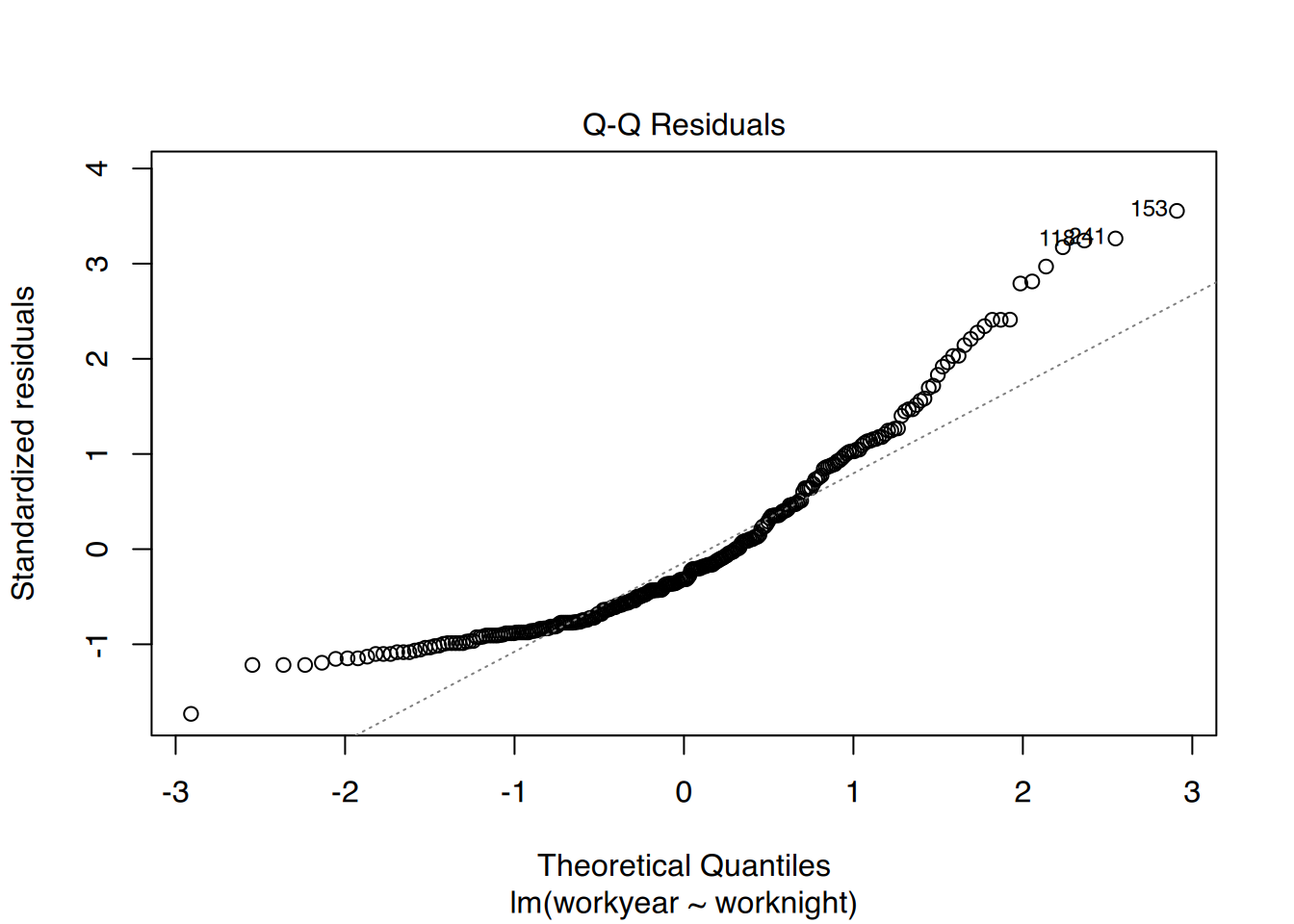
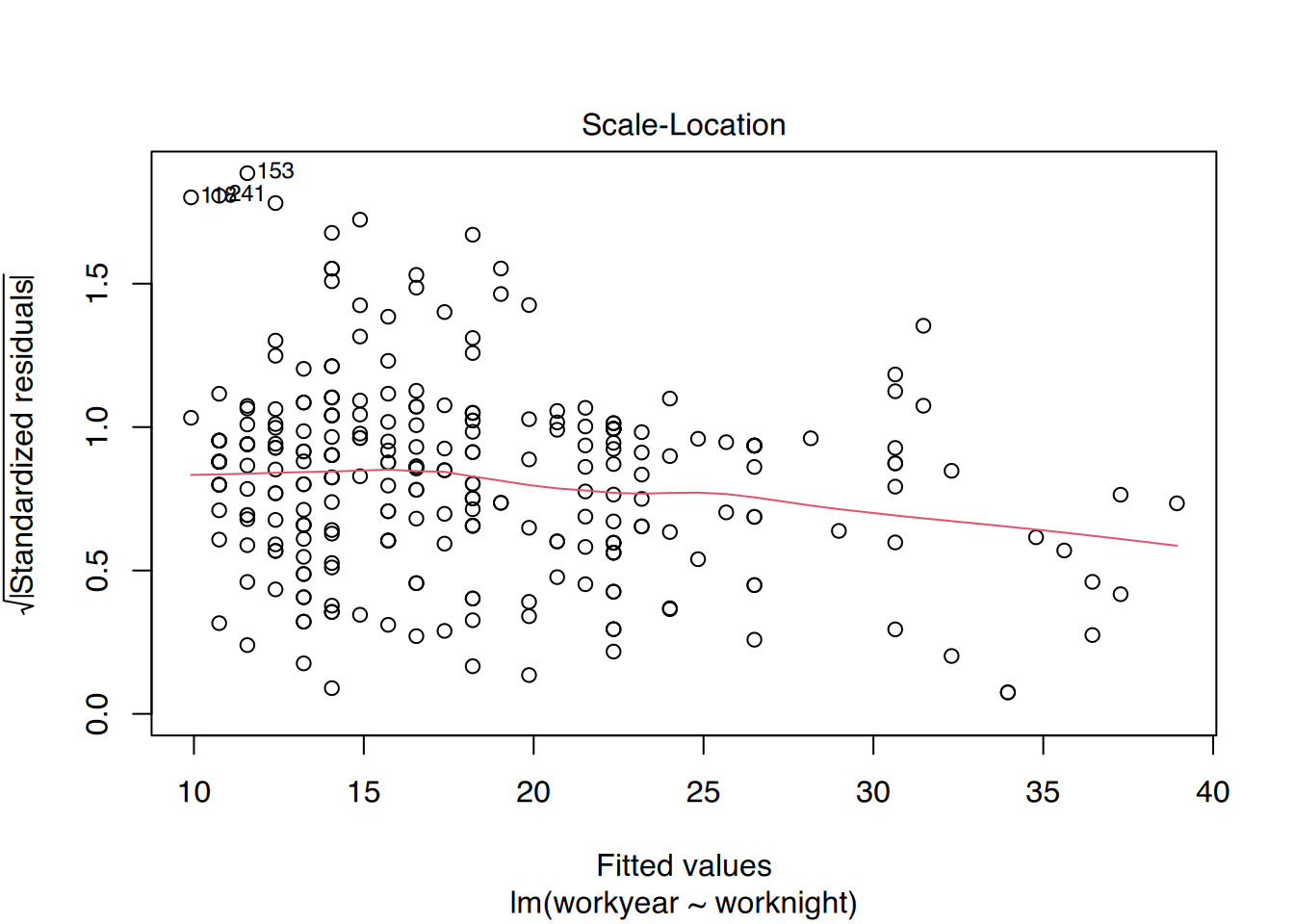
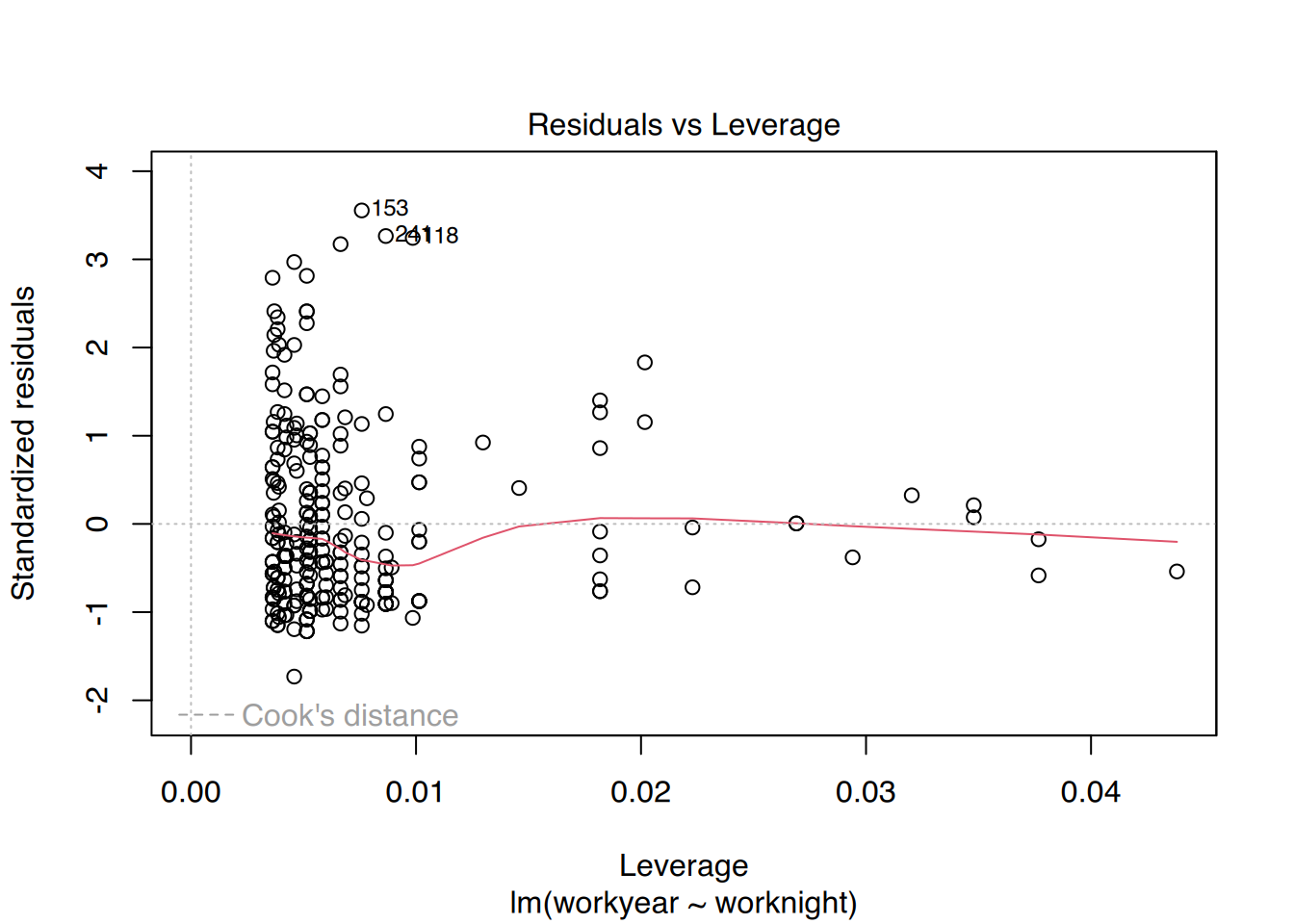
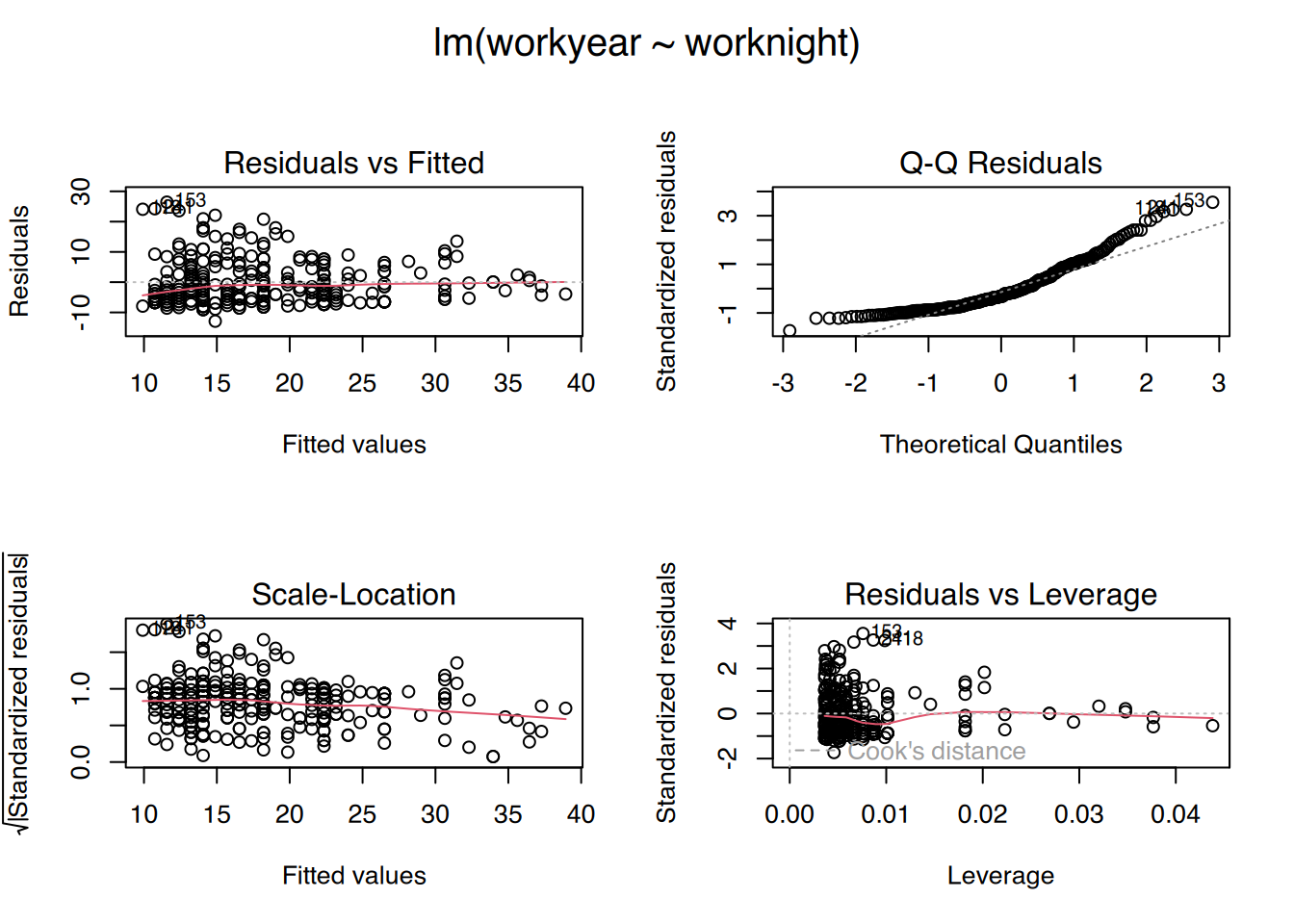
Außerdem lässt sich das Modell so leicht plotten.
plot(fit)
Dies erzeugt insgesamt 4 Plots (Residualplot, Q-Q, Scale-Location und Einfluss). Durch drücken der [Enter]-Taste schalten Sie zum nächsten Plot weiter.
Sie können aber auch alle 4 Plots in einem ausgeben lassen.
# plotte alle 4 auf einer Seitepar(mfrow =c(2, 2), oma =c(0, 0, 2, 0))plot(fit)
Denken Sie aber daran, anschließend die Plotausgabe wieder zurückzusetzen:
par(mfrow =c(1, 1))
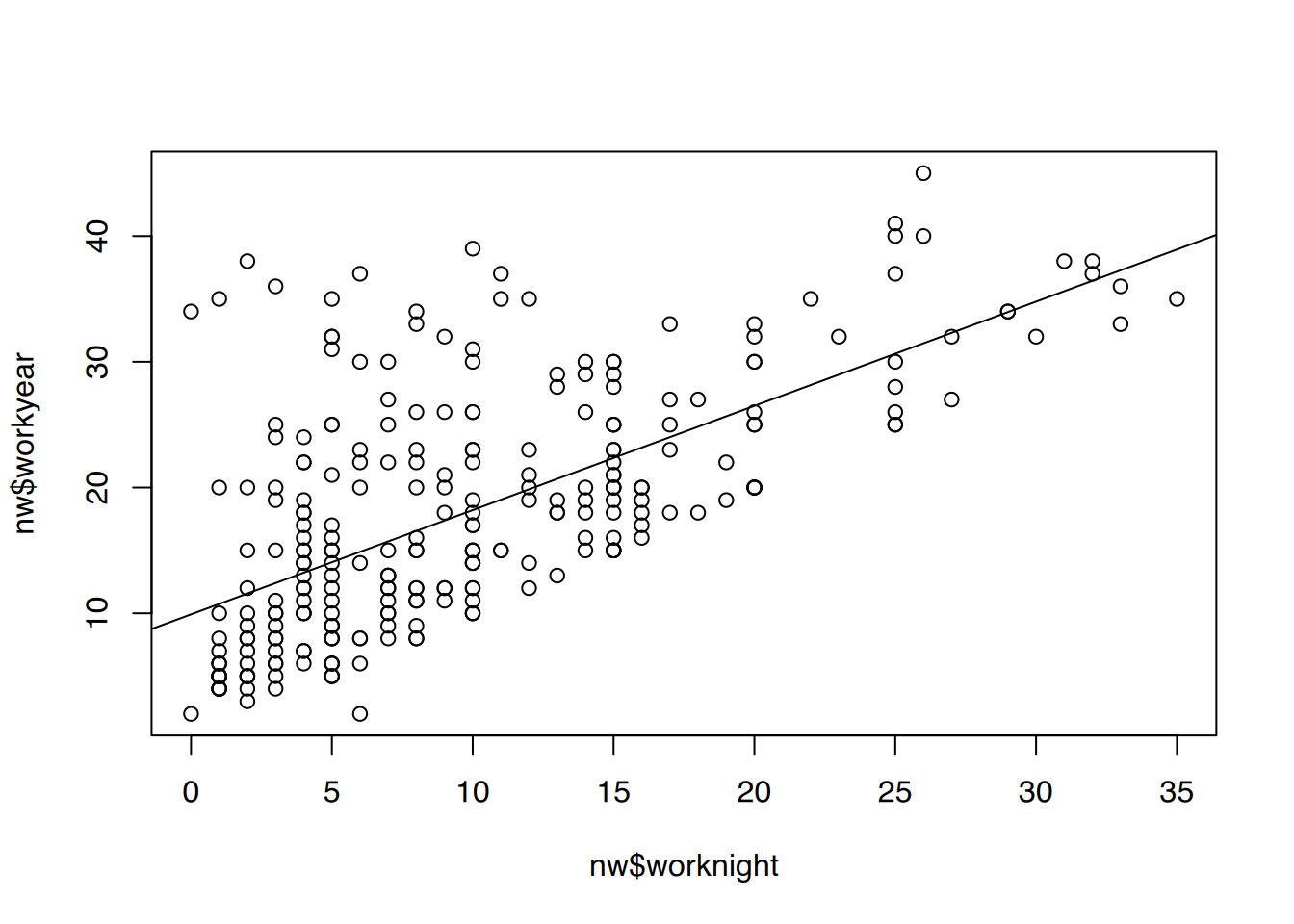
Die Regressionsgerade lässt sich mittels abline() der Punktwolke hinzufügen. Achten Sie dabei auf die jeweils korrekte Zuordnung von x und y. Beim Plotten muss x, y verwendet werden, bei der Regressiongerade ist es y ~ x.
# so ist es richtigplot(nw$worknight, nw$workyear)abline(lm(nw$workyear ~ nw$worknight))
# so ist es FALSCHplot(nw$workyear, nw$worknight)abline(lm(nw$workyear ~ nw$worknight), col="red")
Mit der Funktion predict() lassen sich nun für jedes x die entsprechenden y-Werte des Modells bestimmen (vorhersagen). Der Funktion wird das gefittete Objekt übergeben, sowie eine Liste der gewünschten Prädiktorenwerte.
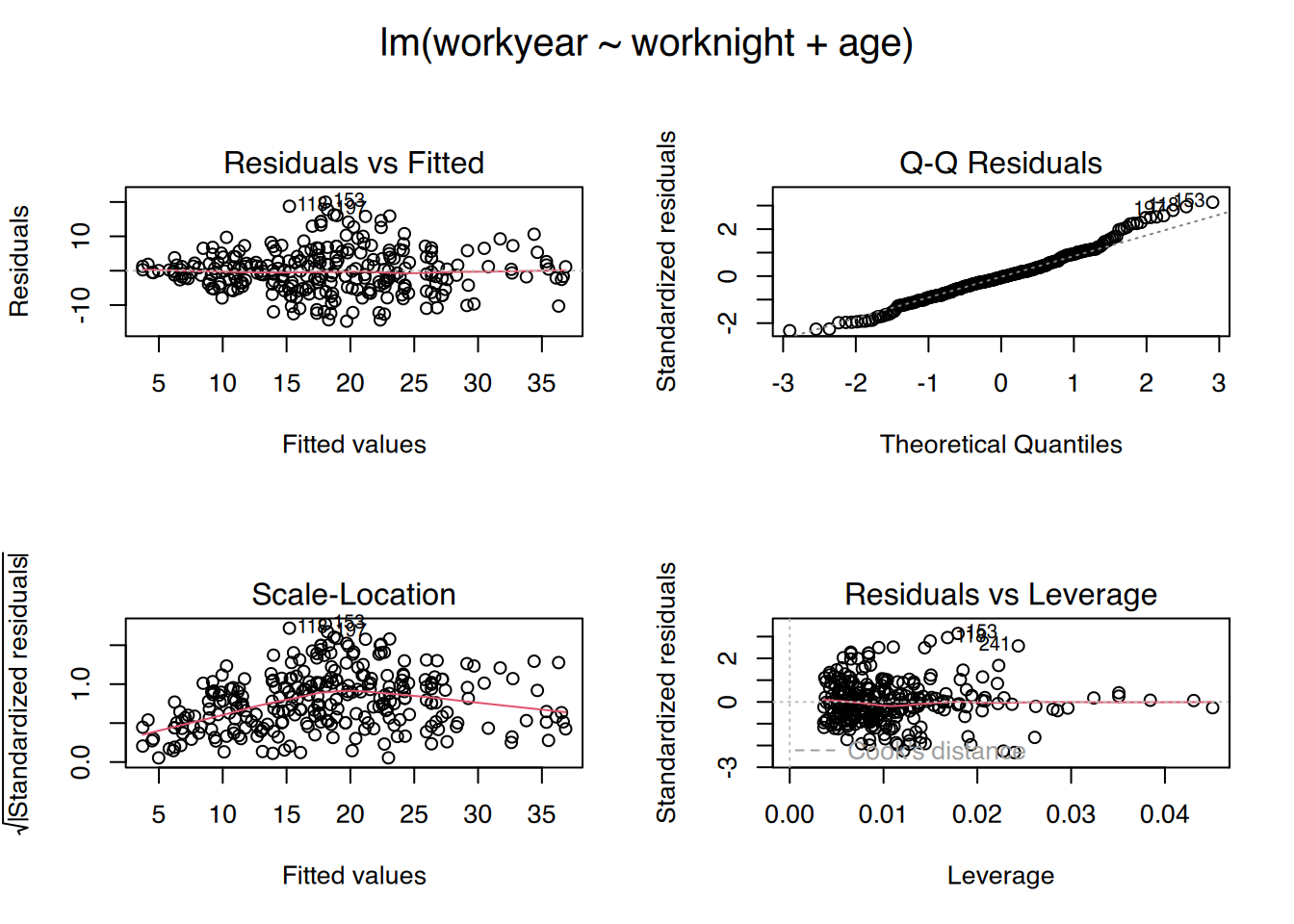
Multiple lineare Regressionen werden ebenfalls mit der Funktion lm() berechnet. Hierbei werden die erklärenden Variablen per + Zeichen aneinandergereiht.
# multiple lineare Regression # "workyear" erklärt durch "worknight" UND "age"fit <-lm(workyear ~ worknight+age, data=nw)summary(fit)#
##
## Call:
## lm(formula = workyear ~ worknight + age, data = nw)
##
## Residuals:
## Min 1Q Median 3Q Max
## -14.7077 -3.9748 -0.3066 3.5936 19.9569
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -5.99856 1.72557 -3.476 0.000591 ***
## worknight 0.57707 0.05714 10.100 < 2e-16 ***
## age 0.41614 0.04195 9.921 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.41 on 273 degrees of freedom
## Multiple R-squared: 0.5693, Adjusted R-squared: 0.5662
## F-statistic: 180.5 on 2 and 273 DF, p-value: < 2.2e-16
Ebenfalls können hier die 4 Plots erzeugt werden.
# plotte alle 4 auf einer Seitepar(mfrow =c(2, 2), oma =c(0, 0, 2, 0))plot(fit)
par(mfrow =c(1, 1))
33.1.2 nicht-lineare Regression
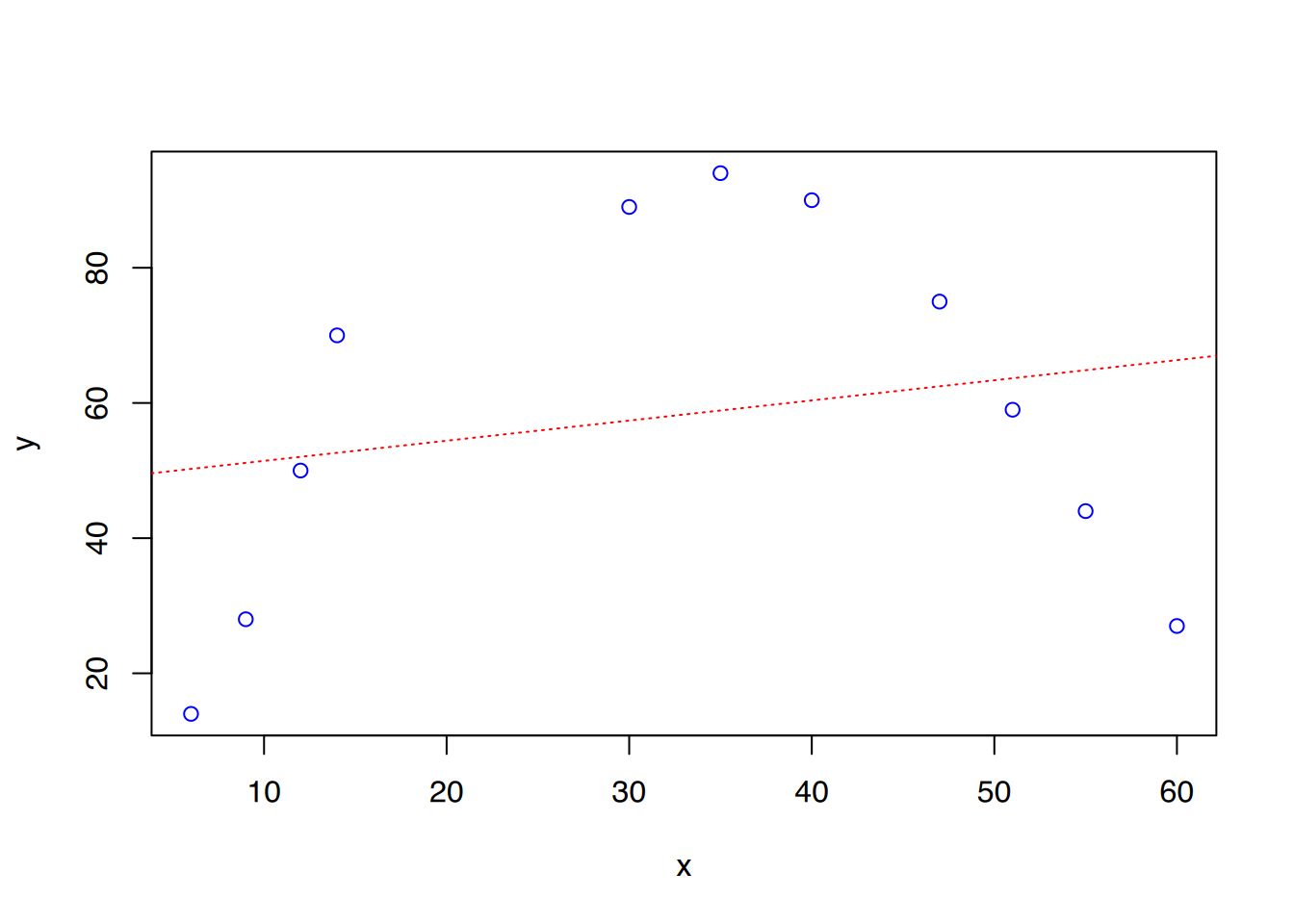
Häufig folgen die vorhandenen Daten keinem linearen Zusammenhang.
Das Aussehen des Plots lässt schon erahnen, dass kein linearer Zusammenhang vorliegt. Wenn wir ein lineares Modell auf die Daten fitten, ist R2 sehr niedrig.
# Modell fittenfit <-lm(y~x)# Modelldaten ausgebensummary(fit)
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -39.34 -21.99 -2.03 23.50 35.11
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 48.4531 17.3288 2.796 0.0208 *
## x 0.2981 0.4599 0.648 0.5331
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 28.72 on 9 degrees of freedom
## Multiple R-squared: 0.0446, Adjusted R-squared: -0.06156
## F-statistic: 0.4201 on 1 and 9 DF, p-value: 0.5331
R2 ist hier 0,0446, was bedeutet, dass nur 4% der Daten durch das Modell erklärt werden können.
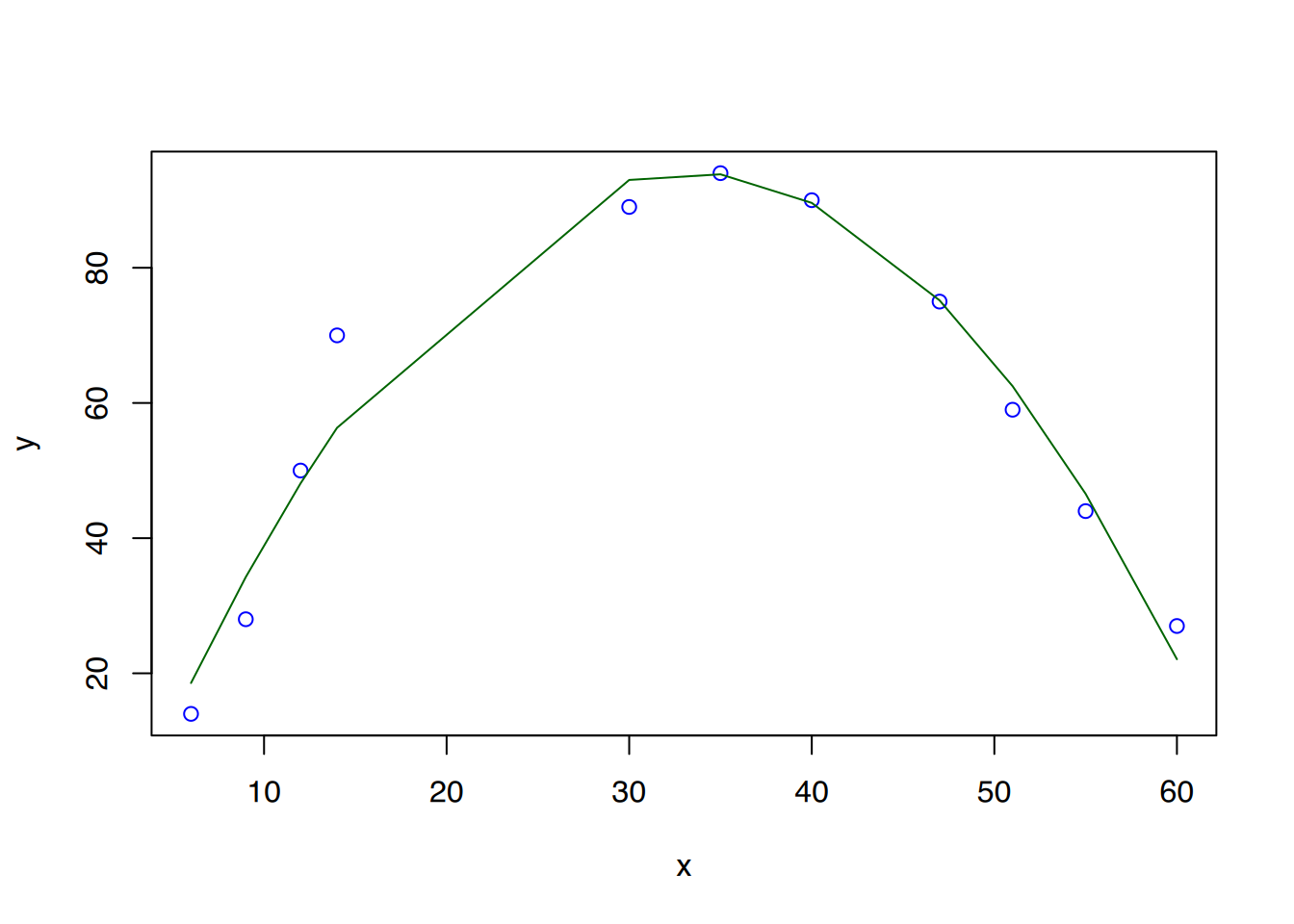
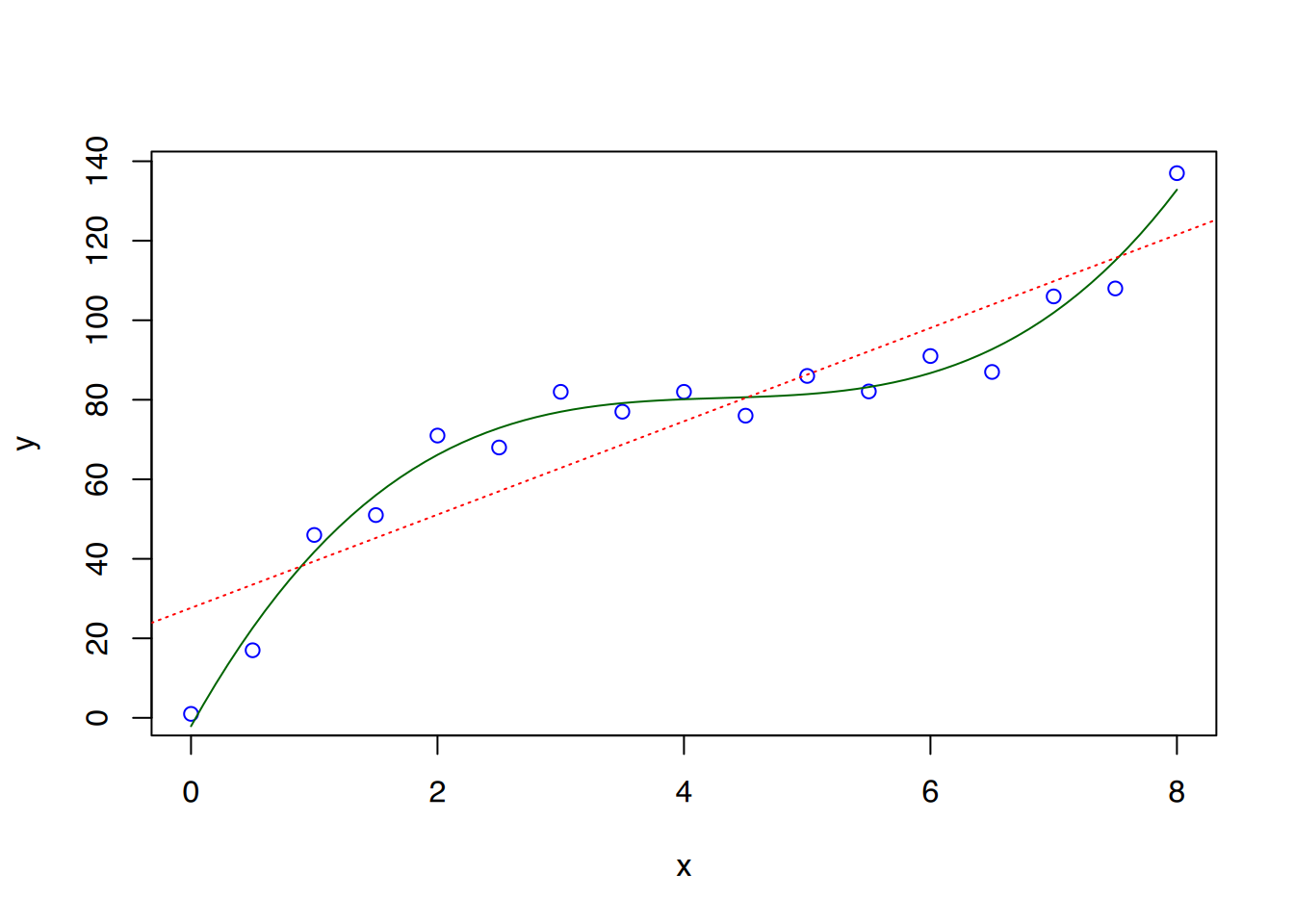
Das Plot legt nahe, dass ein quadratischer Zusammenhang besteht, denn die Punkte scheinen einer Parabel zu folgen. Die Formel einer quadratischen Funktion lautet vereinfacht \(y = x^2 + x\). Den rechten Teil der Formel müssen wir innerhalb von lm() verwenden. Wir können die Formel nicht direkt in lm() schreiben, weil innerhalb von lm() nach dem ~-Zeichen keine weiteren Rechenoperationen möglich sind. Das liegt daran, dass die Prädiktoren mittels + und - übergeben werden. Unser Trick besteht nun darin, die Formel in die I()-Funktion einzupacken:
# Modell erstellen mit quadratischer Formelfit <-lm(y ~ x +I(x^2))# Modellwerte ausgebensummary(fit)
##
## Call:
## lm(formula = y ~ x + I(x^2))
##
## Residuals:
## Min 1Q Median 3Q Max
## -6.2484 -3.7429 -0.1812 1.1464 13.6678
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -18.25364 6.18507 -2.951 0.0184 *
## x 6.74436 0.48551 13.891 6.98e-07 ***
## I(x^2) -0.10120 0.00746 -13.565 8.38e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.218 on 8 degrees of freedom
## Multiple R-squared: 0.9602, Adjusted R-squared: 0.9502
## F-statistic: 96.49 on 2 and 8 DF, p-value: 2.51e-06
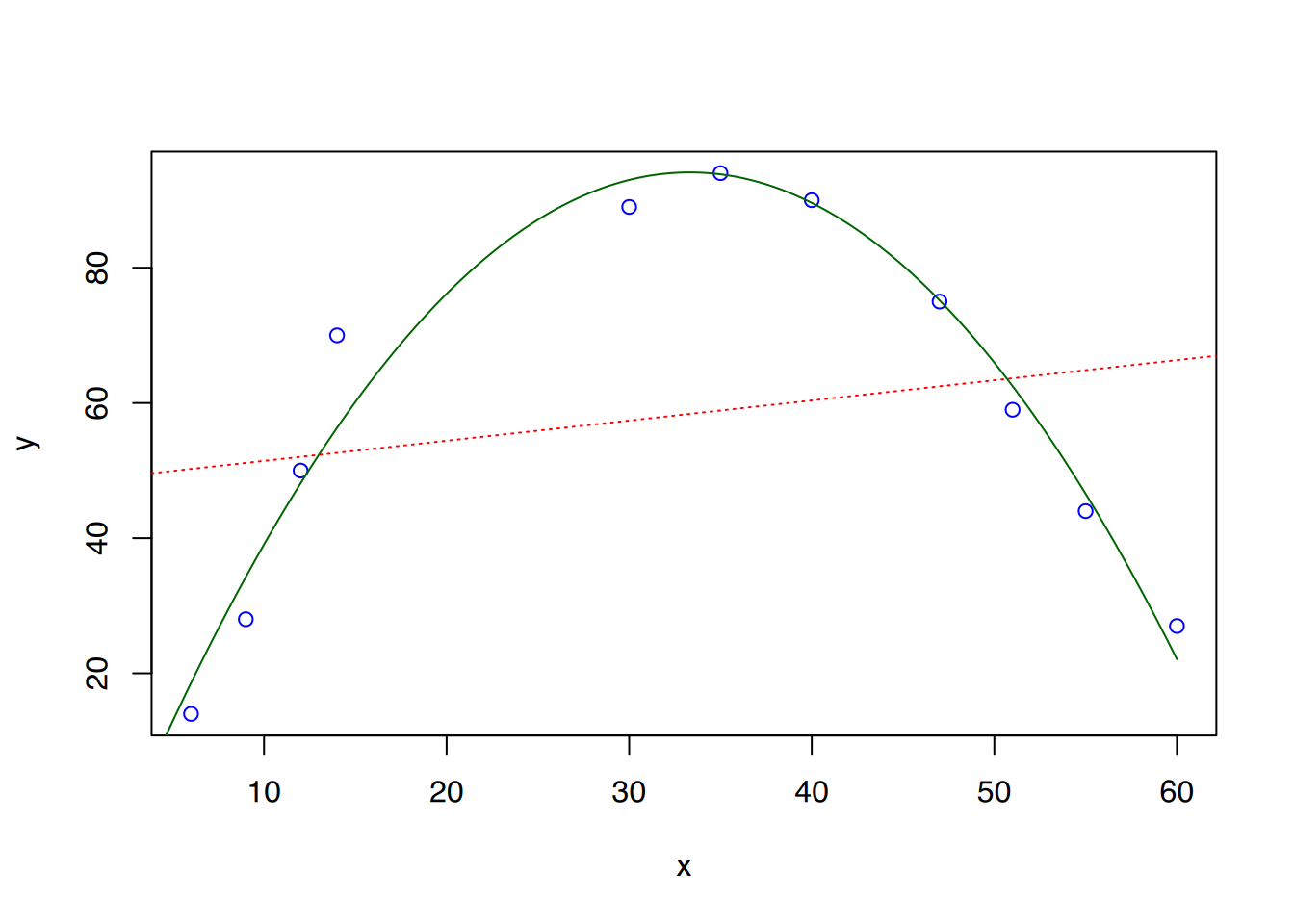
R2 liegt nun bei 0,9602, was bedeutet, dass 96% der Daten durch das Modell erklärt werden können. Die Funktionsformel lautet \(y = -0,10120\cdot x^2 + 6,74436\cdot x - 18,25364\).
Mit der Funktion predict() lassen sich nun für jedes x die entsprechenden y-Werte des Modells bestimmen (vorhersagen). Der Funktion wird das gefittete Objekt übergeben, sowie eine Liste der gewünschten Prädiktorenwerte. Die so erzeugten Modellwerte können dann ins Plot gezeichnet werden.
vorhersage <-predict(fit, list(x=x))plot(x, y, col="blue")lines(x, vorhersage, col='darkgreen')
Um eine schöne Parabel zu zeichnen, haben wir zu wenige x-Werte. Daher erstellen wir einen neuen Vektor, der kontinuierliche Werte für x enthält. Mit diesem können wir dann die entsprechenden (vielen) y-Werte mittels predict() bestimmen und in das Plot einzeichnen. So entsteht - bei genügend Werten - eine schöne Modellparabel.
# Erstelle kontinuierliche Werte# für x von 0 bis 60xref <-seq(0, 60, 0.1)# berechne dazugehörige y-Modellwerteyref <-predict(fit, list(x = xref))# Plottenplot(x, y, col="blue")# Modell-Parabel einzeichnenlines(xref, yref, col='darkgreen')abline(lm(y~x), col="red", lty=3)
33.1.2.1 Funktionen höherer Ordnung
Wird ein Zusammenhang mit einer Funktion höherer Ordnung vermutet, gehen wir analog zur quadratischen Funktion vor. In diesem Beispiel nehmen wir an, der Zusammenhang ließe sich vereinfacht durch die Formel \(y = x^3 + x^2 +x\) beschreiben. Die Daten verhalten sich wie folgt:
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -26.6471 -7.6728 -0.3309 8.2743 19.8794
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 27.647 6.387 4.329 0.000596 ***
## x 11.737 1.362 8.619 3.4e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 13.75 on 15 degrees of freedom
## Multiple R-squared: 0.832, Adjusted R-squared: 0.8208
## F-statistic: 74.29 on 1 and 15 DF, p-value: 3.398e-07
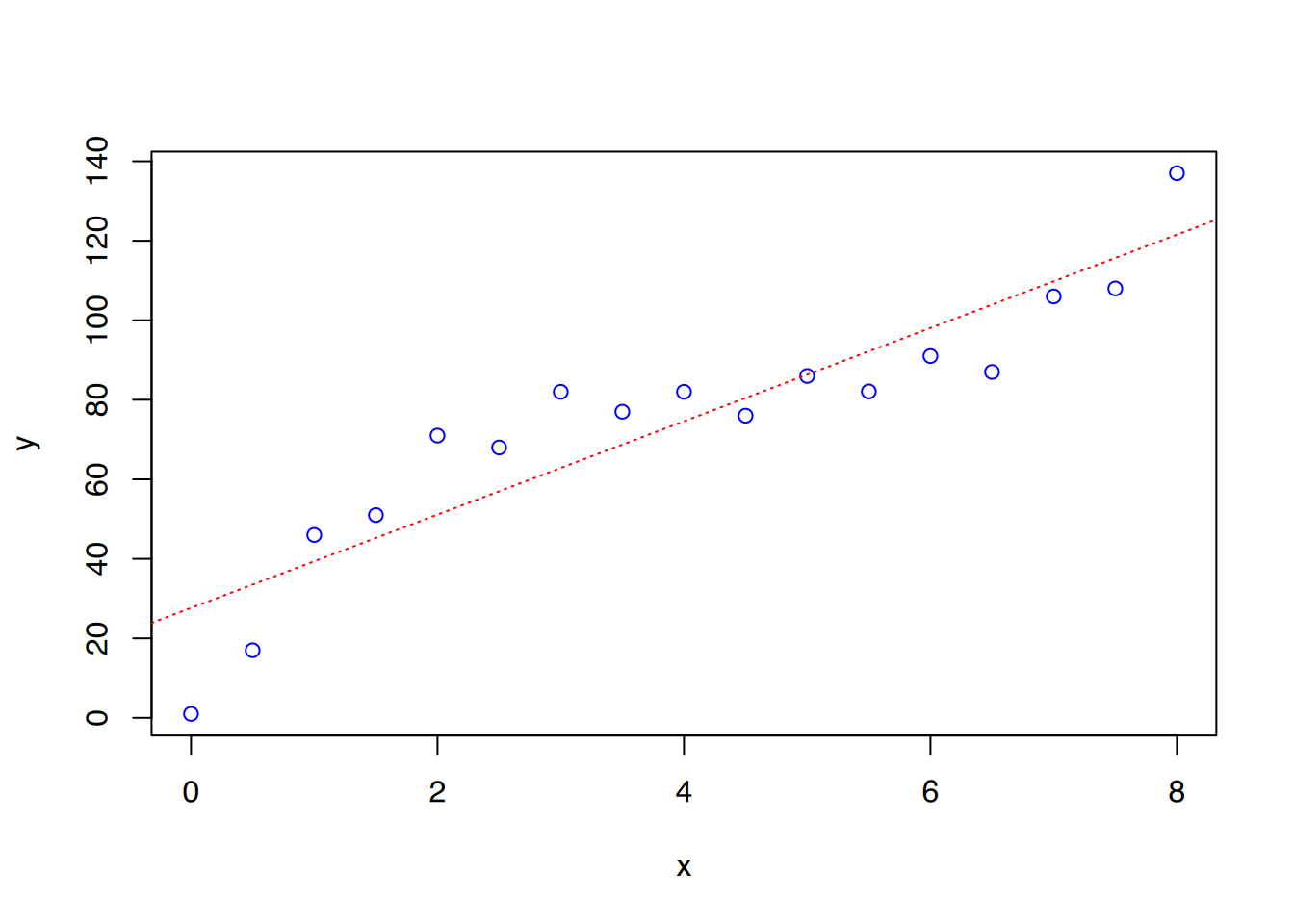
Die Regressionsgerade beschreibt die Daten nicht gut, aber das R2 des linearen Modells ist mit 0,832 recht hoch. Das Modell beschreibt also 83% der vorhandenen Daten.
Versuchen wir nun, die Funktion dritten Grades ins Modell zu übernehmen. Wie bei den quadratischen Funktionen müssen wir die Werte für x3 und x2 in I()-Funktionen einwickeln, die wir dann als Prädiktoren innerhalb von lm() übergeben.
# Modell fittenfit <-lm(y ~ x +I(x^2) +I(x^3))summary(fit)
##
## Call:
## lm(formula = y ~ x + I(x^2) + I(x^3))
##
## Residuals:
## Min 1Q Median 3Q Max
## -7.038 -4.905 1.872 4.254 5.005
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.0945 4.0612 -0.516 0.615
## x 55.5108 4.5344 12.242 1.64e-08 ***
## I(x^2) -12.6470 1.3414 -9.428 3.55e-07 ***
## I(x^3) 0.9771 0.1101 8.876 7.04e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.14 on 13 degrees of freedom
## Multiple R-squared: 0.9797, Adjusted R-squared: 0.975
## F-statistic: 208.8 on 3 and 13 DF, p-value: 3.038e-11
Das R2 liegt bei 0,9797, was bedeutet, dass knapp 98% der Daten durch unser Modell erklärt werden können. Dieses Modell ist also wesentlich besser als das zuvor berechnete lineare Modell. Die Modellformel lautet \(y = 0,9772\cdot x^3 - 12,647\cdot x^2 + 55,5108\cdot x - 2,0945\).
Um die Funktionskurve des Modells in das Plot zu zeichnen, erstellen wir zunächst einen neuen Vektor, der kontinuierliche Werte für x enthält. Über die Funktion predict() können dann die Modellwerte für y berechnet werden.
# Erstelle kontinuierliche Werte# für x von 0 bis 8xref <-seq(0, 8, 0.1)# berechne dazugehörige y-Modellwerteyref <-predict(fit, list(x = xref))# Plottenplot(x, y, col="blue")# Modell-Parabel einzeichnenlines(xref, yref, col='darkgreen')abline(lm(y~x), col="red", lty=3 )
33.1.2.2 Exponentialfunktion
Wird ein exponentieller Zusammenhang vermutet, gehen wir analog zur quadratischen Regression vor.
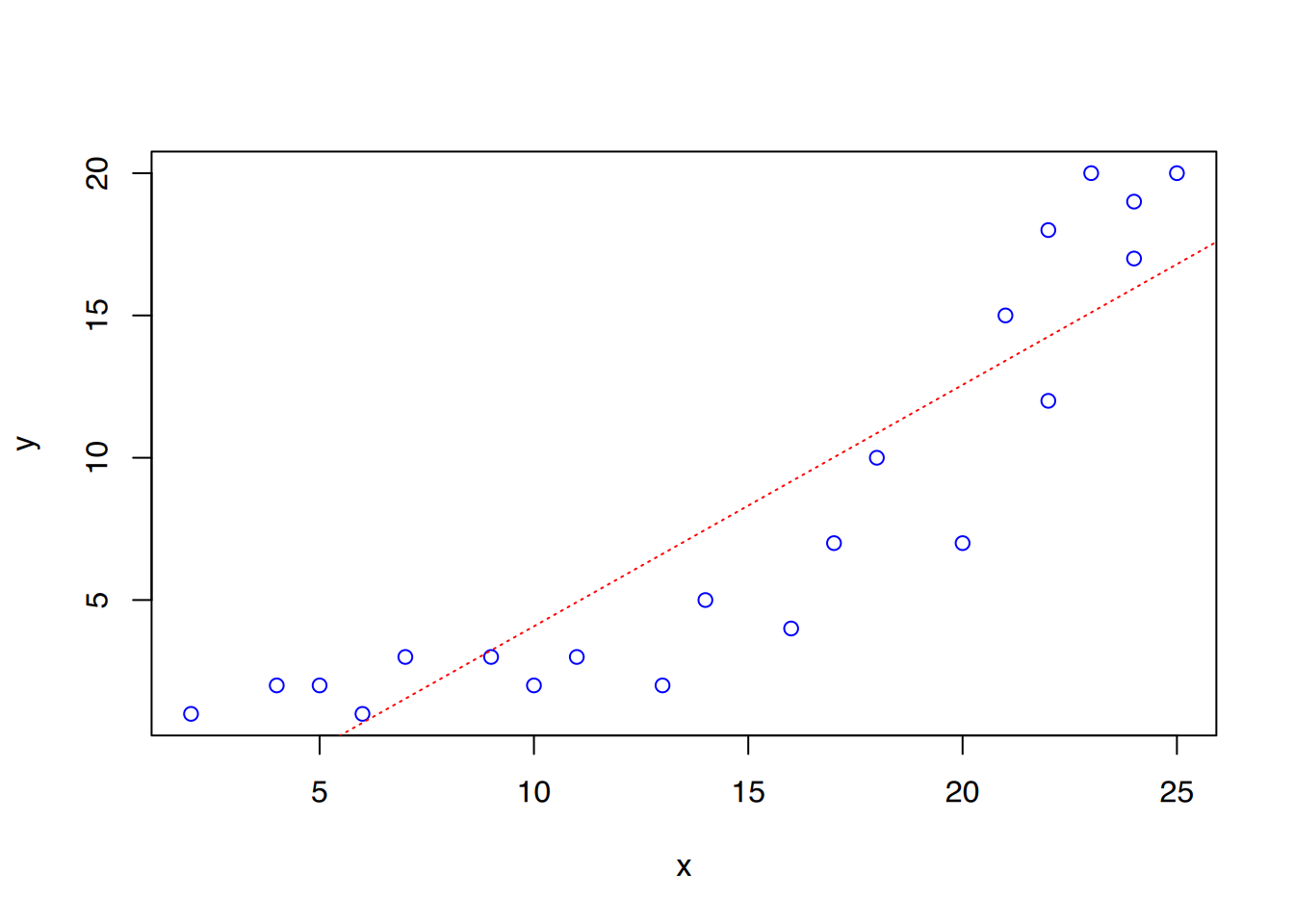
In diesem Beispiel nehmen wir an, der Zusammenhang ließe sich vereinfacht durch die Formel \(y = a^x\) beschreiben. Die Daten verhalten sich wie folgt:
##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.5601 -2.2566 0.3153 3.0118 4.8952
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -4.40475 1.60736 -2.740 0.013 *
## x 0.84824 0.09688 8.756 4.27e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.236 on 19 degrees of freedom
## Multiple R-squared: 0.8014, Adjusted R-squared: 0.7909
## F-statistic: 76.67 on 1 and 19 DF, p-value: 4.275e-08
Die Regressionsgerade beschreibt die Daten nicht gut, aber das R2 des linearen Modells ist mit 0,8014 recht hoch. Das Modell beschreibt also 80% der vorhandenen Daten.
Versuchen wir nun, die Exponentialfunktion ins Modell zu übernehmen. Hierfür fitten wir das Modell nicht auf y, sondern auf den natürlichen Logarithmus yon y.
# Modell fittenfit <-lm(log(y) ~ x)summary(fit)
##
## Call:
## lm(formula = log(y) ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.73254 -0.10440 0.01856 0.24804 0.44867
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.25510 0.16442 -1.551 0.137
## x 0.12929 0.00991 13.047 6.23e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.331 on 19 degrees of freedom
## Multiple R-squared: 0.8996, Adjusted R-squared: 0.8943
## F-statistic: 170.2 on 1 and 19 DF, p-value: 6.232e-11
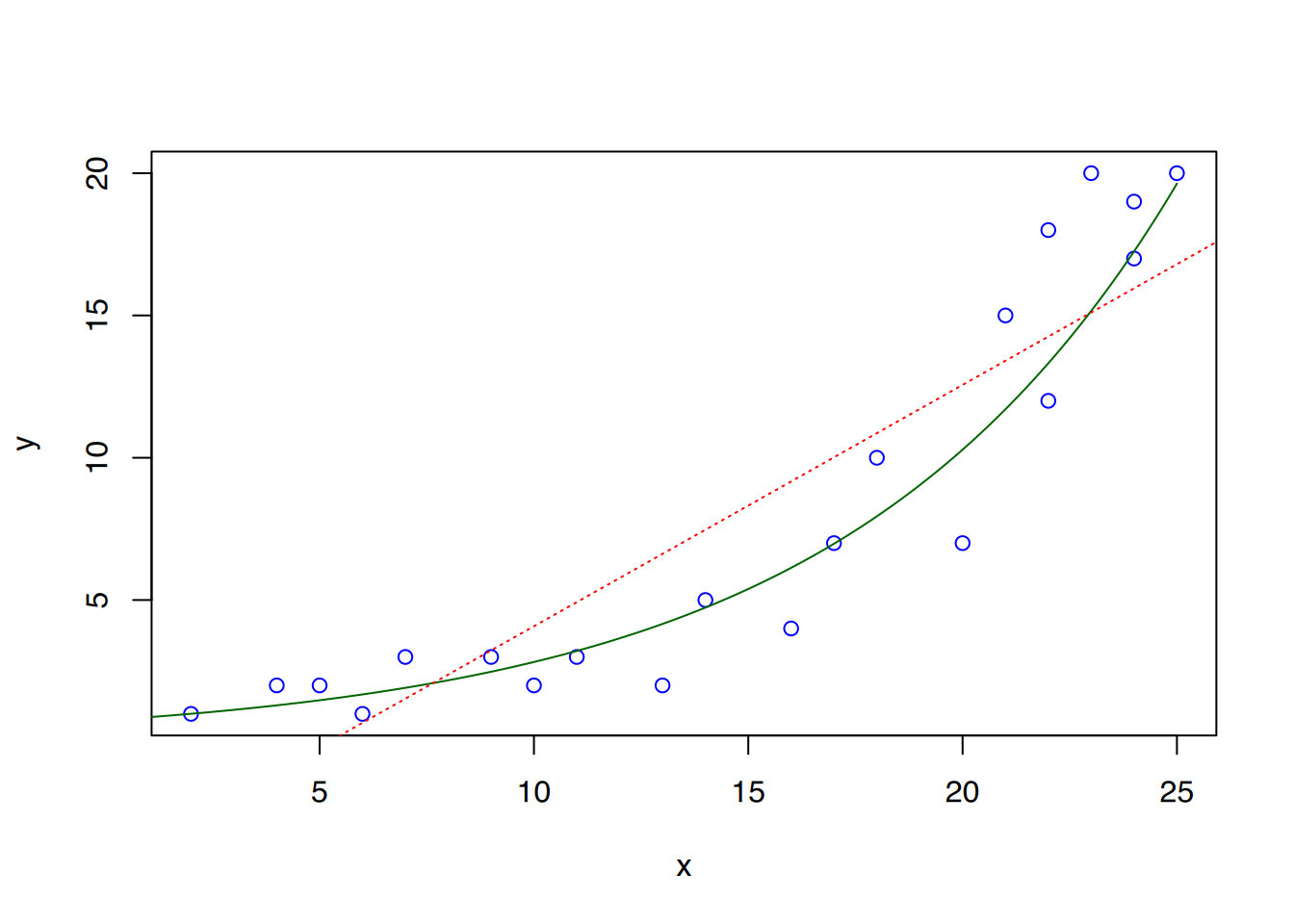
Mit R2 = 0,8996 beschreibt das Modell die Daten besser, als das zuvor erstellte lineare Modell. Die Funktionsformel lautet \(ln(y) = 0,12929\cdot x -0,2551\).
Um die Funktionskurve des Modells in das Plot zu zeichnen, erstellen wir zunächst einen neuen Vektor, der kontinuierliche Werte für x enthält. Über die Funktion predict() können dann die Modellwerte für y berechnet werden. Da wir das Modell auf log(y) gefittet haben, müssen die Werte von predict() mittels exp() umgewandelt werden.
# Erstelle kontinuierliche Werte# für x von 0 bis 8xref <-seq(0, 25, 0.1)# berechne dazugehörige y-Modellwerteyref <-exp(predict(fit, list(x = xref)))# Plottenplot(x, y, col="blue")# Modell-Parabel einzeichnenlines(xref, yref, col='darkgreen')abline(lm(y~x), col="red", lty=3 )
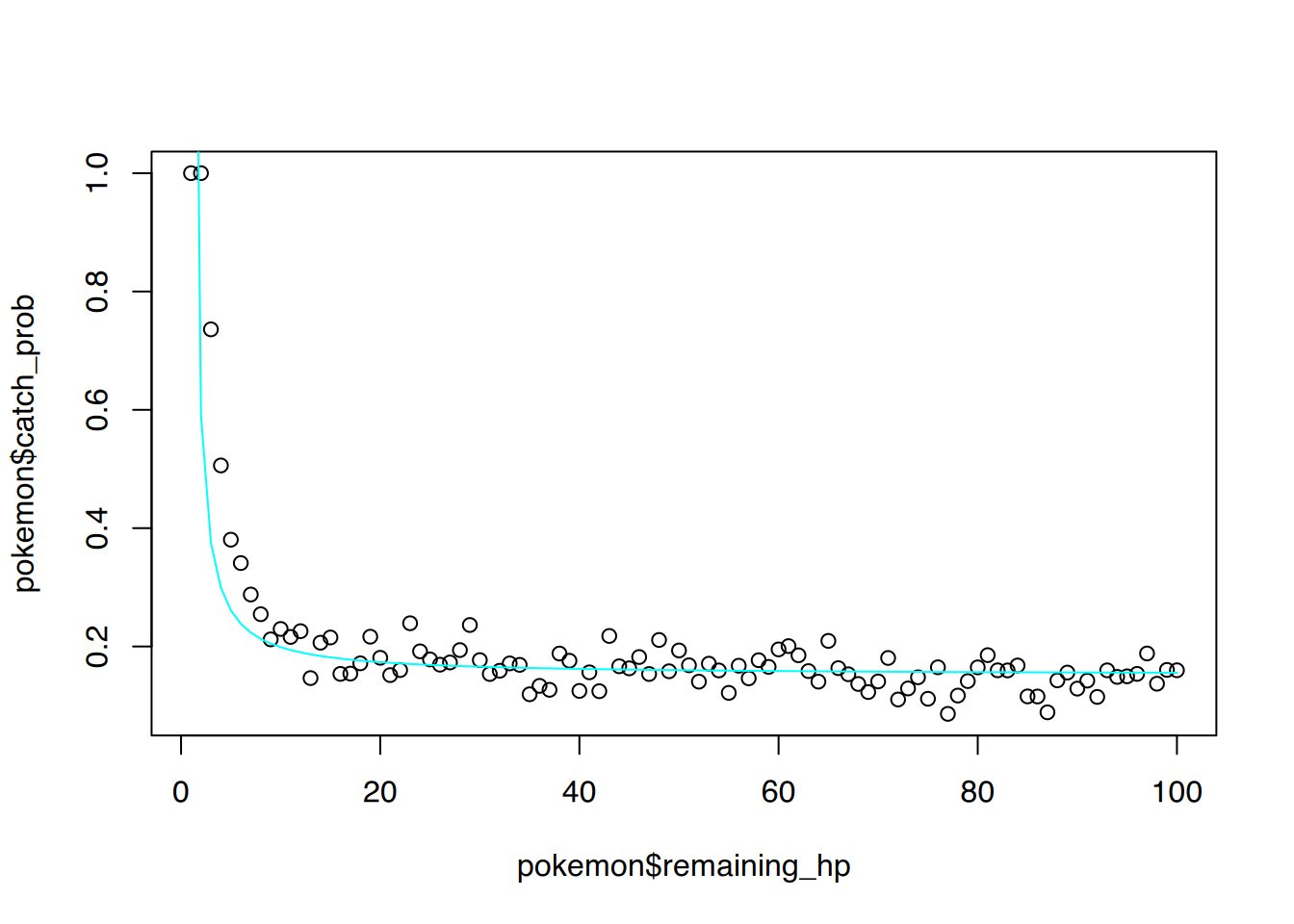
33.1.2.3 Sigmoidalfunktion
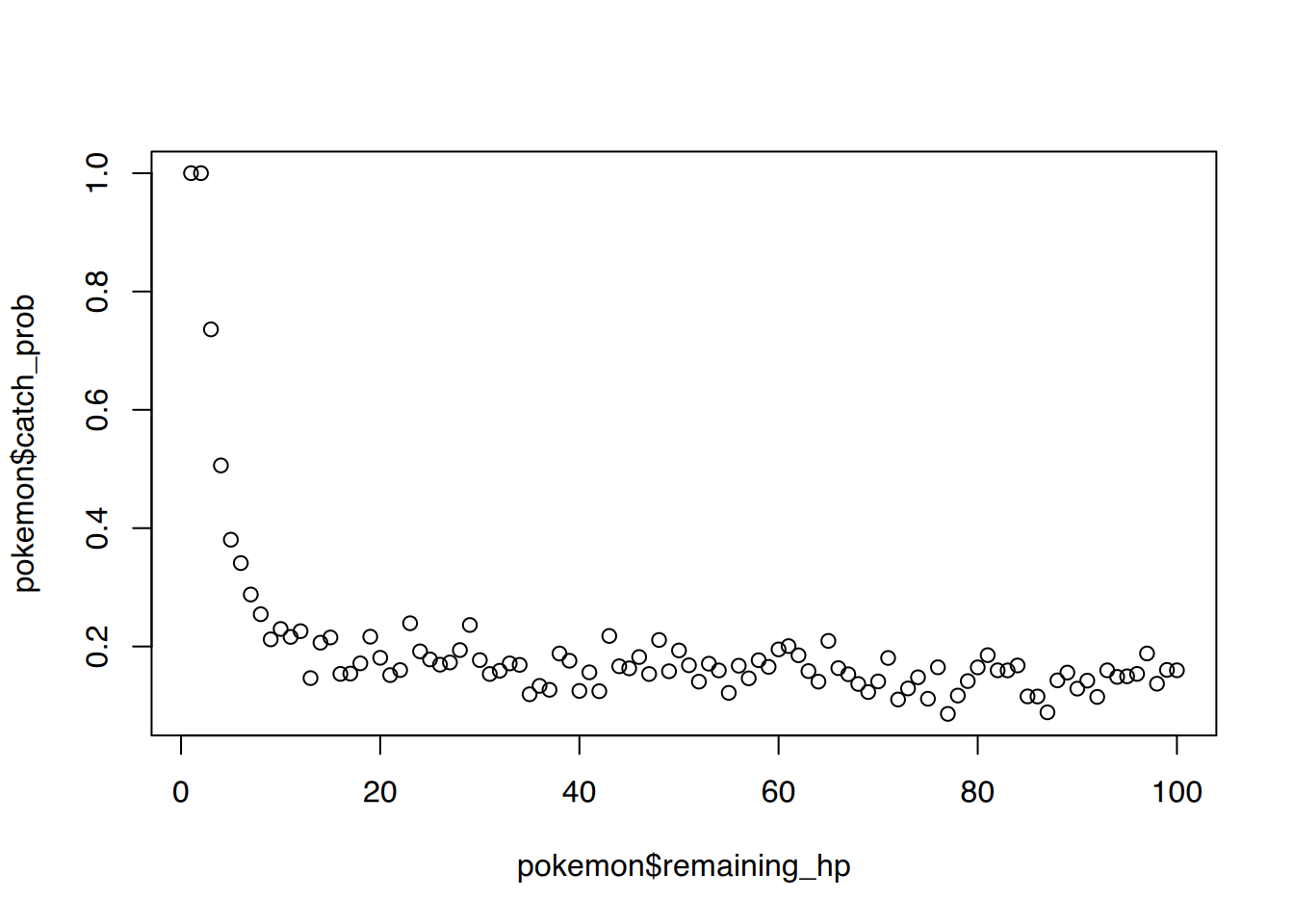
Auch für sigmoidale Verteilungen können wir ähnlich wie in den vorherigen Kapiteln vorgehen. Als Beispieldatensatz verwenden wir die (ausgedachte) Fangwahrscheinlichkeiten für Pokémons in Abhängigkeit zu ihrer Lebensenergie.
## remaining_hp catch_prob
## Min. : 1.00 Min. :0.08607
## 1st Qu.: 25.75 1st Qu.:0.14526
## Median : 50.50 Median :0.16318
## Mean : 50.50 Mean :0.19460
## 3rd Qu.: 75.25 3rd Qu.:0.18905
## Max. :100.00 Max. :0.99999
Die Punktwole legt ein sigmoidales Modell nahe, welches wir nun fitten möchten.
# Modell "Fangwahrscheinlichkeit erklärt durch Level"fit <-lm(log(catch_prob) ~I(1/remaining_hp), data=pokemon)# anschauensummary(fit)
##
## Call:
## lm(formula = log(catch_prob) ~ I(1/remaining_hp), data = pokemon)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.83416 -0.11957 0.02162 0.12840 0.67374
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.88747 0.02514 -75.08 <2e-16 ***
## I(1/remaining_hp) 2.72162 0.19661 13.84 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2298 on 98 degrees of freedom
## Multiple R-squared: 0.6616, Adjusted R-squared: 0.6582
## F-statistic: 191.6 on 1 and 98 DF, p-value: < 2.2e-16
Mit dem Modell können wir nun Werte vorhersagen. Hierbei muss die predict()-Funktion in die exp()-Funktion gewickelt werden, um den Logarithmus des Modells zu neutralisieren. Anschließend können wir die Modelllinie plotten.
# vorhersage für alle Levels von 1 bis 100px =1:100py =exp(predict(fit, list(remaining_hp=1:100)))# plottenplot(pokemon$remaining_hp, pokemon$catch_prob)# Modelllinie hinzufügenlines(px, py, col="cyan")
33.2 Generalisierte lineare Modelle
Mit der Funktion glm() können generalisierte lineare Modelle gebildet werden. Strenggenommen können alle Regressionsmodelle mit glm() erzeugt werden. In R wird sie vor allem verwendet für
Poisson-Regressionen
logistische Regressionen
binomiale Regressionen
Das Standardvorgehen ist in allen Fällen gleich, das gefittete Modell wird in ein Objekt geschrieben
fit <-glm(ZIEL ~ Prädiktor1 + Prädiktor2, family= gaussian)
wobei über den Parameter family die Art des Modells festgelgt wird (z.B. binomial, poisson oder gaussian).
Anschließend werden typischerweise die folgenden Befehle angewendet:
Für lineare Regressionen haben wir die Funktion lm() verwendet. Tatsächlich könnten wir die Modelle auch per gml() erstellen. Kommen wir zurück zu dem Beispiel des Lese- und Rechtschreibetests.
##
## Call:
## lm(formula = Rechtschreibung ~ Lesetest)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.42907 -0.26211 0.04498 0.36332 1.29412
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.20761 0.67774 1.782 0.113
## Lesetest 1.05536 0.05718 18.458 7.65e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.9221 on 8 degrees of freedom
## Multiple R-squared: 0.9771, Adjusted R-squared: 0.9742
## F-statistic: 340.7 on 1 and 8 DF, p-value: 7.648e-08
Der Aufruf in glm() erfolgt analog, wobei wir den Parameter family auf gaussian stellen müssen.
# fitte mit glm()fit <-glm(Rechtschreibung~Lesetest, family = gaussian)summary(fit)
##
## Call:
## glm(formula = Rechtschreibung ~ Lesetest, family = gaussian)
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.20761 0.67774 1.782 0.113
## Lesetest 1.05536 0.05718 18.458 7.65e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for gaussian family taken to be 0.850346)
##
## Null deviance: 296.5000 on 9 degrees of freedom
## Residual deviance: 6.8028 on 8 degrees of freedom
## AIC: 30.526
##
## Number of Fisher Scoring iterations: 2
Die errechneten Parameter stimmen mit lm() überein. Es fällt auf, dass glm() keinen Wert für R2 zeigt, dafür aber einen AIC-Wert liefert.
Eine alternative Modellübersicht bietet die Funktion summ() (mit 2 m) aus dem Paket jtools.
jtools::summ(fit, digits=4)
Observations
10
Dependent variable
Rechtschreibung
Type
Linear regression
𝛘²(1)
289.6972
Pseudo-R² (Cragg-Uhler)
0.9790
Pseudo-R² (McFadden)
0.6062
AIC
30.5262
BIC
31.4340
Est.
S.E.
t val.
p
(Intercept)
1.2076
0.6777
1.7818
0.1126
Lesetest
1.0554
0.0572
18.4576
0.0000
Standard errors: MLE
33.3 Poisson-Regression
Die Poisson-Regression wird beispielsweise verwendet, um die Anzahl an Ereignissen (Kunden in der Schlange, Patienten in der Notaufnahme) auf ihre Abhängikeit zu bestimmten Prädiktoren zu untersuchen.
Wir verwenden den Testdatensatz “Notaufnahme.txt”, der als Texttabelle im Internet verfügbar ist.
Er besteht aus 350 Beobachtungen der Patientenanzahl pro Tag in einer Notaufnahme. Zusätzlich wurden in der Spalte Wochentag die Wochentage erhoben. In Spalte Event wurde dichtotom erfasst, ob eine “größere” Veranstaltung in der Stadt stattgefunden hat.
# anzeigenhead(df)
## Patienten Wochentag Event
## 1 8 Mo nein
## 2 9 Di nein
## 3 14 Mi nein
## 4 10 Do nein
## 5 10 Fr nein
## 6 15 Mo nein
Untersuchen wir nun, inwieweit der Wochentag und das Stattfinden einer größeren Veranstaltung die Anzahl der Notfälle beeinflusst. Das Modell kann wie gewohnt mit glm() erstellt werden, wobei wir den Parameter family=poisson setzen müssen.
# Poissonregressionsmodell erzeugenfit <-glm(Patienten ~ Wochentag + Event, data = df, family = poisson)# Zusammenfassung des Modellssummary(fit)
##
## Call:
## glm(formula = Patienten ~ Wochentag + Event, family = poisson,
## data = df)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.528011 0.050672 49.889 < 2e-16 ***
## WochentagDo 0.071575 0.057063 1.254 0.2097
## WochentagFr 0.050956 0.057349 0.889 0.3743
## WochentagMi 0.119094 0.056421 2.111 0.0348 *
## WochentagMo 0.003367 0.058026 0.058 0.9537
## WochentagSa 0.429869 0.065146 6.599 4.15e-11 ***
## WochentagSo 0.365318 0.066489 5.494 3.92e-08 ***
## Eventnein -0.292176 0.037640 -7.762 8.33e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 512.02 on 349 degrees of freedom
## Residual deviance: 345.57 on 342 degrees of freedom
## AIC: 1830.7
##
## Number of Fisher Scoring iterations: 4
Das Modell zeigt an, dass die Patientenzahl signifikant an den Wochentagen “Sa” und “So” erhöht ist. Auch der Prädiktor Event ist signifikant. Der negative Prädiktorenwert bei “Eventnein” gibt an, dass sich die Patientenzahl verringert, wenn kein Event stattfindet. In der Modellzusammenfassung ist “Event=ja” der Bezugswert, so dass der Schätzwerte für “Event=nein” ausgegeben wird. Schöner anzusehen wäre es genau andersherum. Um “Event=nein” als Basiswert zu setzen, und den Schätzwert für “Event=ja” anzuzeigen, können wir die Events in einen Factor umwandeln, und dann mittels relevel() den Wert “nein” als Bezugspunkt setzen.
# Wir wollen Event="nein" als Basisdf$Event <-factor(df$Event)df$Event <-relevel(df$Event, "nein")# Poissonregressionsmodell neu erzeugenfit <-glm(Patienten ~ Wochentag + Event, data = df, family = poisson)# Zusammenfassung des Modellssummary(fit)
##
## Call:
## glm(formula = Patienten ~ Wochentag + Event, family = poisson,
## data = df)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 2.235835 0.041828 53.453 < 2e-16 ***
## WochentagDo 0.071575 0.057063 1.254 0.2097
## WochentagFr 0.050956 0.057349 0.889 0.3743
## WochentagMi 0.119094 0.056421 2.111 0.0348 *
## WochentagMo 0.003367 0.058026 0.058 0.9537
## WochentagSa 0.429869 0.065146 6.599 4.15e-11 ***
## WochentagSo 0.365318 0.066489 5.494 3.92e-08 ***
## Eventja 0.292176 0.037640 7.762 8.33e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for poisson family taken to be 1)
##
## Null deviance: 512.02 on 349 degrees of freedom
## Residual deviance: 345.57 on 342 degrees of freedom
## AIC: 1830.7
##
## Number of Fisher Scoring iterations: 4
Eine alternative Übersicht bietet die Funktion summ() (mit 2 m) aus dem Paket jtools.
jtools::summ(fit, digits=4)
Observations
350
Dependent variable
Patienten
Type
Generalized linear model
Family
poisson
Link
log
𝛘²(7)
166.4510
Pseudo-R² (Cragg-Uhler)
0.3798
Pseudo-R² (McFadden)
0.0840
AIC
1830.7077
BIC
1861.5712
Est.
S.E.
z val.
p
(Intercept)
2.2358
0.0418
53.4531
0.0000
WochentagDo
0.0716
0.0571
1.2543
0.2097
WochentagFr
0.0510
0.0573
0.8885
0.3743
WochentagMi
0.1191
0.0564
2.1108
0.0348
WochentagMo
0.0034
0.0580
0.0580
0.9537
WochentagSa
0.4299
0.0651
6.5986
0.0000
WochentagSo
0.3653
0.0665
5.4944
0.0000
Eventja
0.2922
0.0376
7.7624
0.0000
Standard errors: MLE
Die Werte der Koeffizienten sind als Log-Odds dargestellt. Eine bessere Lese- und Interpretierbarkeit bietet die Darstellung als Odds-Ratio. Hierfür muss der Logarithmus mittels exp() aufgehoben werden.
# Zeige die Koeffizienten als Odds-Ratioexp(fit$coefficients)
Die Funktion tab_model() aus dem sjPlot-Paket erstellt ihrerseits eine schöne Übersichtstabelle, wobei die Werte in Odds-Ratios angegeben und die Konfidenzintervalle enthalten sind.
sjPlot::tab_model(fit)
Patienten
Predictors
Incidence Rate Ratios
CI
p
(Intercept)
9.35
8.61 – 10.14
<0.001
Wochentag [Do]
1.07
0.96 – 1.20
0.210
Wochentag [Fr]
1.05
0.94 – 1.18
0.374
Wochentag [Mi]
1.13
1.01 – 1.26
0.035
Wochentag [Mo]
1.00
0.90 – 1.12
0.954
Wochentag [Sa]
1.54
1.35 – 1.75
<0.001
Wochentag [So]
1.44
1.26 – 1.64
<0.001
Event [ja]
1.34
1.24 – 1.44
<0.001
Observations
350
R2 Nagelkerke
0.493
Um die Güte des Modells zu bestimmen, können nun weitere Berechnungen vorgenommen werden.
33.3.1 Dispersion
Die Equidistation (Dispersion) des Modells sollte zwischen \(0,9\) und \(1,1\) liegen. Um sie zu bestimmen teilen wir die Residualdeviance durch die Anzahl der Feiheitsgrade.
Unser Wert liegt innerhalb des Bereichs, d.h. das Modell ist nicht überdispersioniert. Mit der Funktion dispersiontest() aus dem AER-Paket lässt sich zusätzlich ein Signifikanztest auf Überdispersion fahren. Die Nullhypothese besagt, das keine Überdispersion vorliegt.
AER::dispersiontest(fit, trafo=1)
##
## Overdispersion test
##
## data: fit
## z = -0.64112, p-value = 0.7393
## alternative hypothesis: true alpha is greater than 0
## sample estimates:
## alpha
## -0.04479655
Der Test ist nicht signifikant, es liegt keine Überdispersion vor.
Sollte in dem Modell Überdispersion vorliegen, erfolgt der Aufruf von gml() mit dem Parameter family=quasipoisson.
glm(Patienten ~ Wochentag + Event, data = df, family = quasipoisson)
33.3.2 Nullmodell
Mit einem Nullmodell können wir testen, ob unser gefittetes Modell die Daten besser erklären kann. Hierfür ersetzen wir alle Prädiktoren durch die Ziffer \(1\).
# erstelle Null-Modellfit0 <-glm(Patienten ~1, data = df, family = poisson)
Vergleichen wir die AIC-Werte beider Modelle.
# Ziehe von unserem Modell-AIC den Nullmodell-AIC abfit$aic - fit0$aic
## [1] -152.451
Das Ergebnis ist negativ. Das beudetet, dass der AIC-Wert des Nullmodells größer ist. Somit ist unser AIC-Modellwert kleiner, und das bedeutet, dass es besser ist als das Nullmodell.
Zusätzlich können wir die beiden Modelle mittels Varianzanalyse (siehe Abschnitt 33.9) untersuchen, wobei wir als Testeinstellung den Chi2-Test wählen.
# ANOVA auf beide Modelle mittels Chi^2-Testanova(fit0, fit, test="Chisq")
Unser gefittetes Modell erklärt die Daten signifikant besser als das Nullmodell.
33.3.3 Vorhersagen
Mit der Funktion predict() können wir nun die wahrscheinliche Patientenzahl für Kombinationen aus Wochentag und Event vorhersagen.
# Mit wievielen Patienten ist an einem# Dienstag mit Event in der Stadt zu rechnen?predict(fit, data.frame(Wochentag="Di", Event="ja"), type ="response")
## 1
## 12.52856
# ohne Label "1" ausgebenas.numeric(predict(fit, data.frame(Wochentag="Di", Event="ja"), type ="response"))
## [1] 12.52856
Um gut vorbereitet zu sein, runden wir die Patientenzahl mittels ceiling() auf die nächste ganze Zahl auf.
as.numeric(ceiling(predict(fit, data.frame(Wochentag="Di", Event="ja"), type ="response")))
## [1] 13
Wir können davon ausgehen, dass an einem Dienstag mit Event in der Stadt etwa 13 Patienten in die Notaufnahme kommen werden.
Die Wahrscheinlichkeiten für verschiedene Patientenanzahlen an beliebigen Wochentagen mit oder ohne Stadtevent lassen sich mit der Funktion ppois() bestimmen (siehe Abschnitt 18.4).
# Lambda-Wert für "Dienstag" und Event="ja"Modelllambda <-predict(fit, data.frame(Wochentag="Di", Event="ja"), type ="response")## Wahrscheinlichkeit, dass an einem Dienstag mit Event...## - bis zu 16 Patienten eingeliefert werden (nicht mehr als 16)ppois(16, Modelllambda)
## [1] 0.8674935
## - mindestens 16 Patienten eingeliefert werden (16 oder mehr)1-ppois(16, Modelllambda)
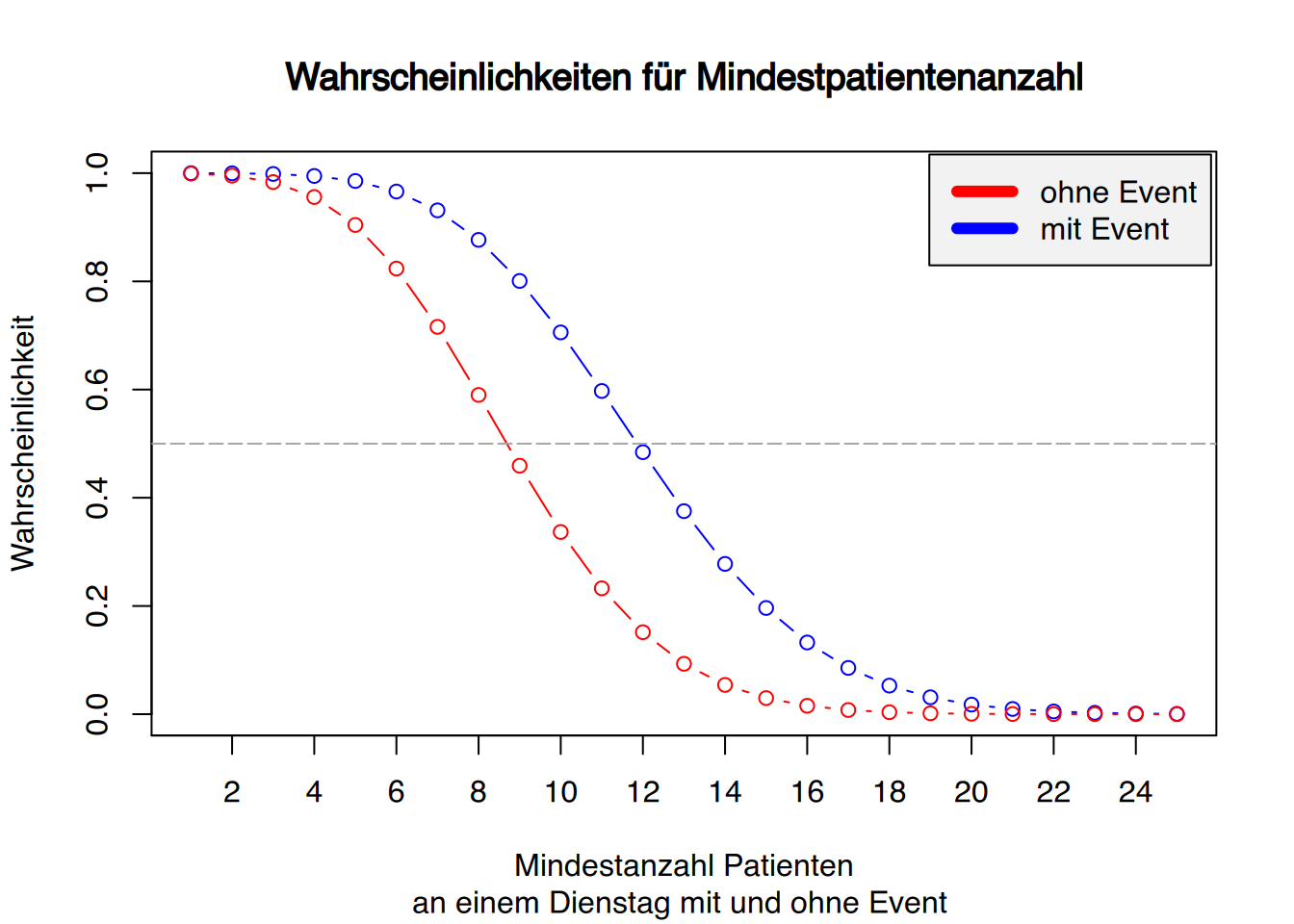
So können wir einen Plot erstellen, auf dem die Wahrscheinlichkeiten angegeben sind, dass an einem Dienstag mit oder ohne Event in der Stadt mindestensx Patienten aufgenommen werden.
# Lambda für Event="nein"Modelllambda_ohne <-predict(fit, data.frame(Wochentag="Di", Event="nein"), type ="response")# Patienten N 1 bis 25x <-1:25# plotten für Event="ja"plot(x, 1-ppois(x, Modelllambda), type="b", col="blue",main ="Wahrscheinlichkeiten für Mindestpatientenanzahl",sub="an einem Dienstag mit und ohne Event ",ylab="Wahrscheinlichkeit",xlab="Mindestanzahl Patienten", xaxt ="n")# X-Achsenticks in 2er-Schrittenaxis(1, at=seq(0, 25, 2))# füge Punktlinie für Event="nein" hinzulines(x, 1-ppois(x, Modelllambda_ohne),type="b", col="red")# füge Hilfslinie hinzuabline(h=.5, lty=5, col="grey65")# füge Legendenbox hinzulegend(x="topright", inset=0.005, legend=c("ohne Event", "mit Event"),col=c("red", "blue"), lwd=6, bg="grey95")
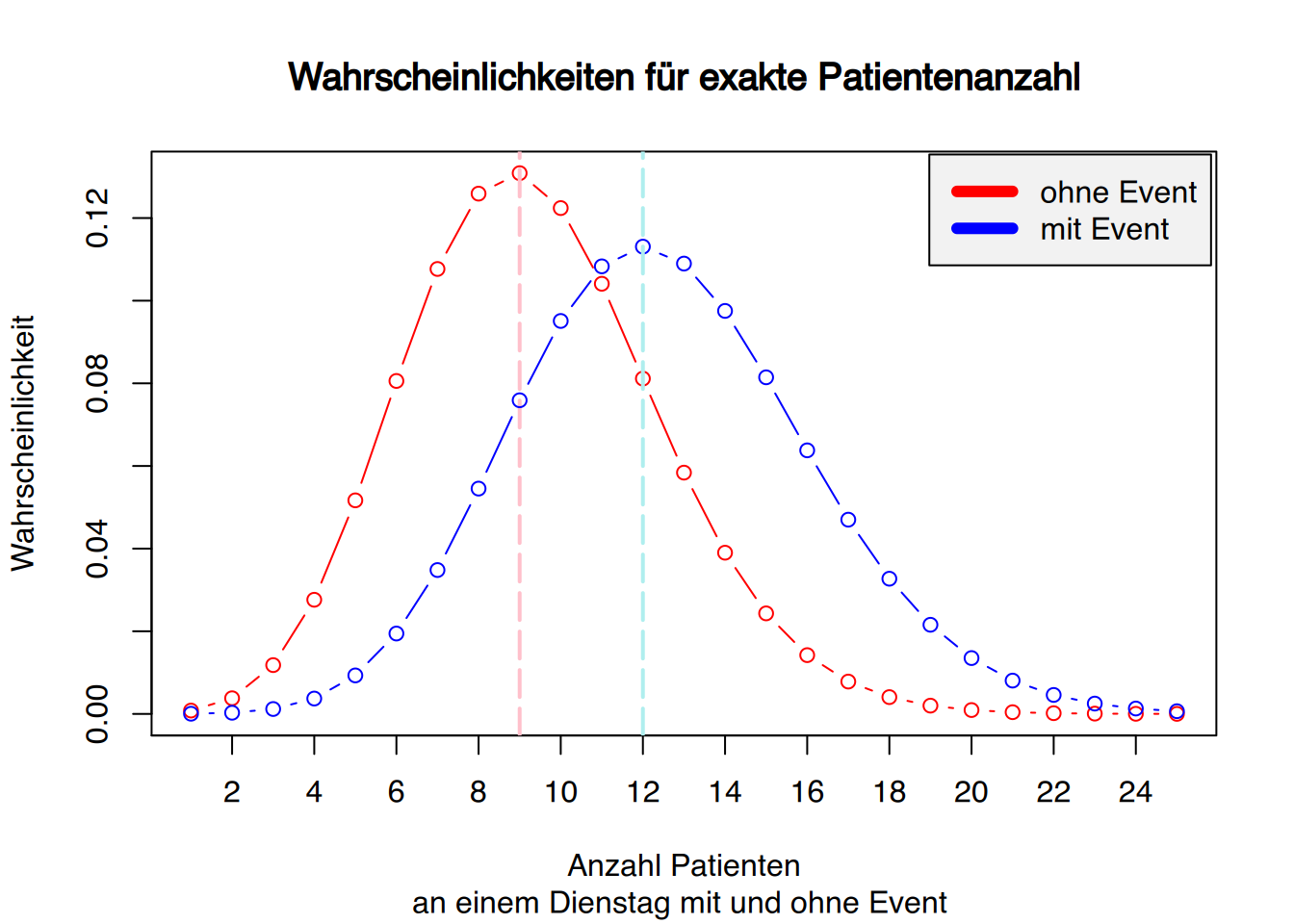
Das geht ebenso für die Wahrscheinlichkeiten der exakten Patientenanzahl.
# Wahrscheinlichkeit für exakte Patienten-N mit Event="ja"y1 <-ppois(x, Modelllambda) -ppois(x-1, Modelllambda)# Wahrscheinlichkeit für exakte Patienten-N mit Event="nein"y2 <-ppois(x, Modelllambda_ohne) -ppois(x-1, Modelllambda_ohne)# plotte für Event="nein"plot(x, y2, type="b", col="red",main ="Wahrscheinlichkeiten für exakte Patientenanzahl",sub="an einem Dienstag mit und ohne Event ",ylab="Wahrscheinlichkeit",xlab="Anzahl Patienten", xaxt ="n")# X-Achsenticks in 2er-Schrittenaxis(1, at=seq(0, 25, 2))# Hilfslinie für Event="nein"abline(v=9, lty=5, col="pink", lwd=2)# Punktlinie für Event="ja" einzeichnenlines(x, y1, type="b", col="blue")# Hilfslinie für Event="ja"abline(v=12, lty=5, col="paleturquoise", lwd=2)# Legendenbox hinzufügenlegend(x="topright", inset=0.005, legend=c("ohne Event", "mit Event"),col=c("red", "blue"), lwd=6, bg="grey95")
33.4 Logistische Regression
Als Beispiel dienen Daten der Challenger-Katastrophe (am 28. Januar 1986 explodierte die Raumfähre Challenger 73 Sekunden nach dem Start).
Der Ausfall eines oder mehrerer Dichtungsringe in einer der seitlichen Feststoffrakten wurde als Grund der Katastrophe ermittelt. Probleme mit den Dichtungsringen sind auch vor- her am Boden aufgetreten. So liegen Erhebungsdaten vor, die den Defekt ei- nes Rings in Zusammenhang mit der Außentemperatur darstellen können: Je kälter es draußen ist, desto höher die Ausfallwahrscheinlichkeit eines Rings. Bedauerlicher Weise wurden diese Daten erst rückwirkend ausgewertet. Diese Daten übertragen wir wie folgt in R:
Die Kodierung des factor Ausfall lautet: 0=kein Ausfall | 1=Ausfall Die Einheit für Temp lautet Fahrenheit.
Der Aufruf zur logistischen Regression (Ausfall erklärt durch Temp) lautet:
fit <-glm(Ausfall~Temp,data=shuttle, family=binomial)summary(fit)
##
## Call:
## glm(formula = Ausfall ~ Temp, family = binomial, data = shuttle)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 15.0429 7.3786 2.039 0.0415 *
## Temp -0.2322 0.1082 -2.145 0.0320 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 28.267 on 22 degrees of freedom
## Residual deviance: 20.315 on 21 degrees of freedom
## AIC: 24.315
##
## Number of Fisher Scoring iterations: 5
Die Odds Ratio (OR) für \(\beta\)Temp= -0,2322 errechnet sich mit der exp()-Funktion:
exp(-0.2322)
## [1] 0.7927875
Dies liefert das Ergebnis OR = 0.7927875. Die Interpretation lautet: Mit jedem höhren Grad an Temparatur ändert sich die Chance auf einem Ausfall um den Faktor 0.7927. Das bedeutet, dass die Chancen eines Ausfalls niedriger werden, je höher die Außentemperatur steigt.
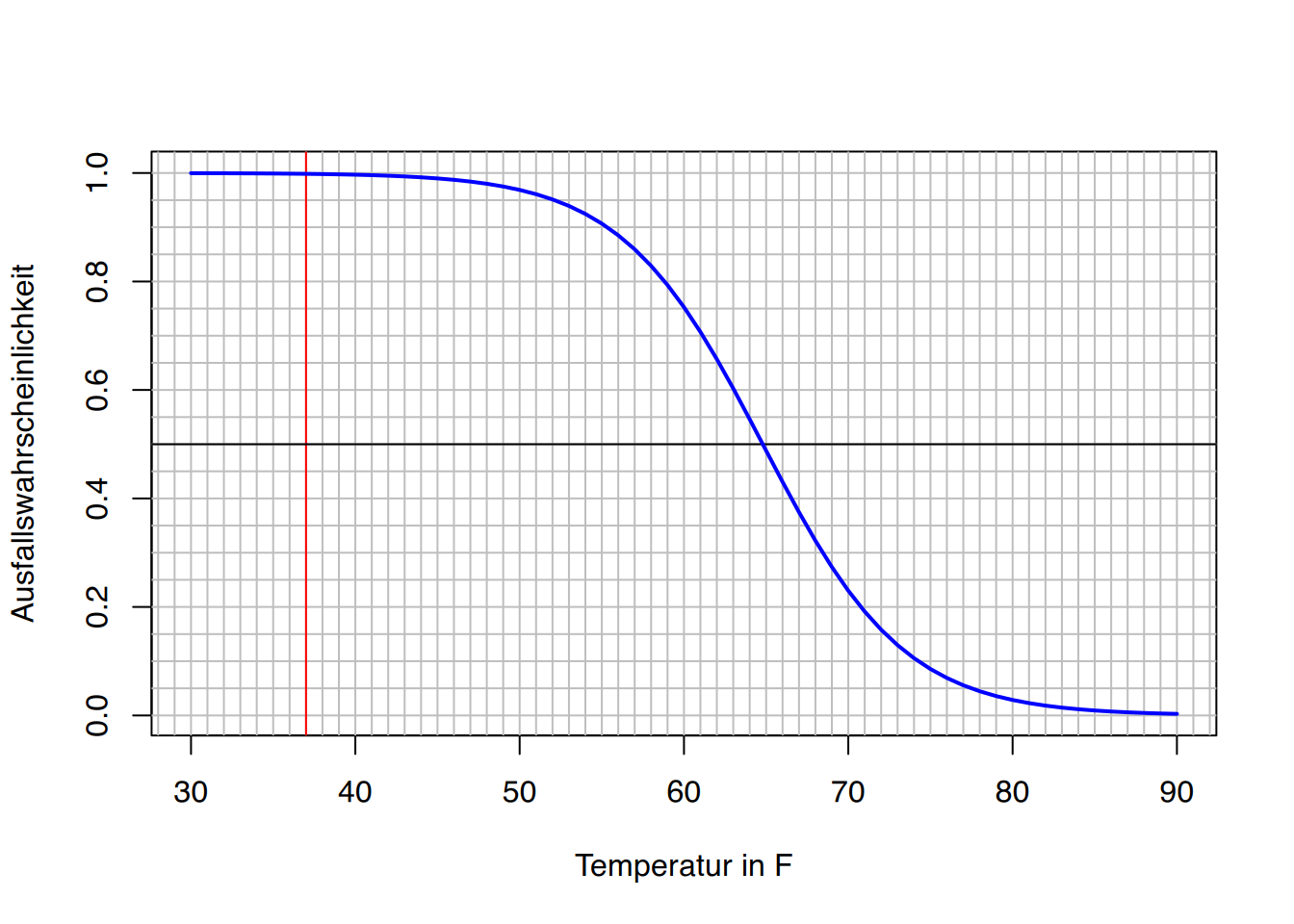
In der Nacht vor dem Challengerstart konnte eine Temperatur von 37° Fahrenheit gemessen werden. Auf Grundlage der logistischen Regression lässt sich nun die Ausfallwahrscheinlichkeit bei 37° Außentemperatur berechnen:
predict(fit, data.frame(Temp=37),type="response")
## 1
## 0.9984265
Das Modell sagt bei einer Außentemperatur von 37° eine Ausfallwahrscheinlichkeit von 99,84% voraus.
Jetzt kann man dies für jede mögliche Temperatur durchmachen, und schon erhält man dieses schöne Plot:
y <-predict(fit, data.frame(Temp=30:90), type="response")plot(30:90, y, type="l", ylab="Ausfallswahrscheinlichkeit", xlab="Temperatur in F")abline(v=seq(20,100,1), h=seq(-0.2,1.2,0.05),col="gray") #Mathegitterabline(v=37, col="red") # 37-Gradabline(h=0.5, col="black") # Mittelliniepoints(30:90, y, type="l",lwd=2, col="blue") # Schätzwerte in "blau"
33.5 Ordinale Regression
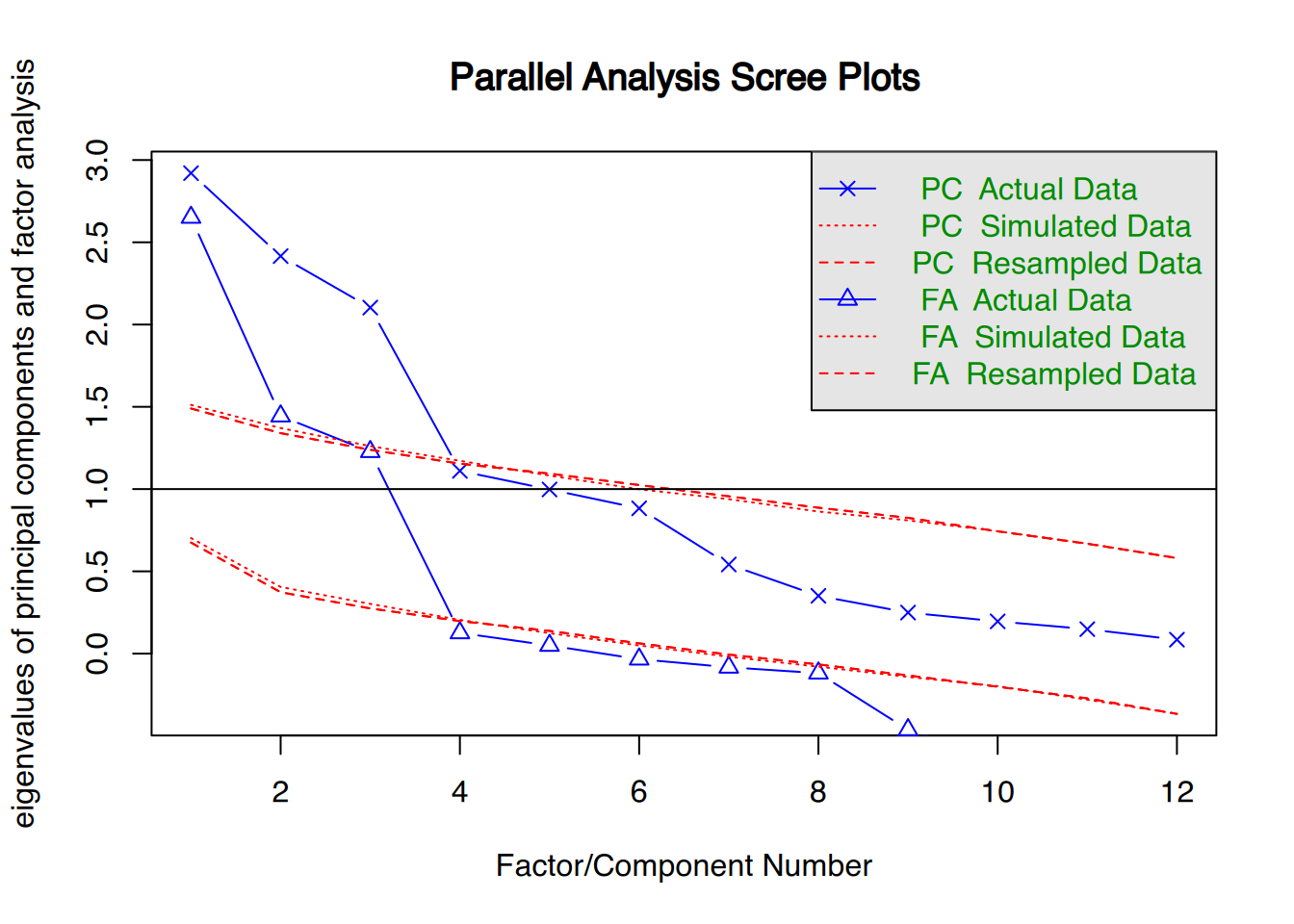
Zur Bestimmung des Einflusses von Prädiktoren auf ein ordinales Ziel stehen verschiedene Modelle der ordinalen Regression zur Verfügung. Namentlich werden hier vor allem Proportional Odds Modelle und Continuation Ratio Modelle verwendet.
Eine verständliche Einführung in ordinale Modelle findet sich im Open Access Artikel von große Schlarmann und Galatsch (große Schlarmann & Galatsch, 2014).
Für die ordinalen Regressionen verwenden wir das “VGAM”, welches zunächst in R installiert werden muss
Die Variable “Stimmung” dient hier als ordinales Ziel mit den Ausprägungen “schlecht” < “maessig” < “gut” < “sehr gut”.
Die Variable “Konflikt” dient als Prädiktor. Sie gibt an, wieviele Konflikte derzeit im Arbeitsleben vorliegen.
Die Variable “Zufriedenh” beschreibt, wie zufrieden Probanden mit ihrem Job sind.
Die Variable “Stimmung” soll nun durch “Konflikt” und “Zufriedenh” beschrieben werden.
Wir wollen wissen, wie stark Stimmung durch Konflikt und Zufriedenh beinflusst wird. Das heisst, in unserem Modell soll die Variable Stimmung durch Konflikt und Zufriedenh beschrieben werden.
33.5.1 Proportional Odds Modell
Ein Proportional Odds Modell errechnet sich leicht mit dem VGAM-Paket und der Funktion vglm():
Das Proportional Odds Modell geht von der “equal slopes assumption” (auch: “proportional odds assumption”) aus. Diese Annahme muss geprüft werden, bevor das Modell als gültig angesehen werden kann. Dies geht mit dem VGAM-Paket recht einfach. Der Befehl vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=propodds) ist eine Abkürzung für vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cumulative(parallel=T)). Der Parameter parallel=TRUE/FALSE stellt ein, ob das Modell mit equal slopes (=TRUE), oder ohne equal slopes assumption (=FALSE) erstellt werden soll. Zur Überprüfung der “Equal Slopes Assumption” erstellt man jeweils ein TRUE und ein FALSE-Modell, und führt dann einen Likelihood-Test durch. Die Nullhypothese lautet, dass equal slopes vorliegen.
# Modell OHNE equal slopesnpom <-vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cumulative(parallel=F))# log-likelihood-Test auf Equal Slopes Assumptionlrtest(pom,npom)# Test
## Likelihood ratio test
##
## Model 1: Stimmung ~ Konflikt + Zufriedenh
## Model 2: Stimmung ~ Konflikt + Zufriedenh
## #Df LogLik Df Chisq Pr(>Chisq)
## 1 1240 -460.27
## 2 1236 -456.46 -4 7.6202 0.1065
Der Test ist mit p=0,1065 nicht signifikant. Das heisst, es liegen equal slopes vor. Das Modell darf also verwendet werden.
Alternativ kann dieser Test auch auf die Devianz der Modelle bestimmt werden:
# Devianz-Test auf Equal Slopes Assumptionpom.pdevi = (1-pchisq(deviance(pom) -deviance(npom), df=df.residual(pom)-df.residual(npom)));pom.pdevi
## [1] 0.106526
Ist der Test signifikant, liegen keine “equal slopes” vor. Hier kann ein Partial Proportional Odds Modell erstellt werden, welches die “equal slopes” nur für bestimmte Prädiktoren annimmt. Mit dem VGAM-Paket kann recht einfach bestimmt werden, wie ein solches Modell erstellt werden soll. Hierfür erweitertet man den “parallel”-Switch wie folgt:
# Equal Slopes NUR für "Konflikt"ppom <-vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cumulative(parallel=T~Konflikt-1));ppom
##
## Call:
## vglm(formula = Stimmung ~ Konflikt + Zufriedenh, family = cumulative(parallel = T ~
## Konflikt - 1), data = mydata)
##
##
## Coefficients:
## (Intercept):1 (Intercept):2 (Intercept):3 Konflikt Zufriedenh:1
## 0.6614816 1.5373699 2.7337389 0.5705897 -1.9684047
## Zufriedenh:2 Zufriedenh:3
## -1.2805318 -0.8865225
##
## Degrees of Freedom: 1245 Total; 1238 Residual
## Residual deviance: 914.4929
## Log-likelihood: -457.2464
# Nochmals EqualSlopes NUR für "Konflikt"ppom <-vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cumulative(parallel=F~Zufriedenh));ppom
##
## Call:
## vglm(formula = Stimmung ~ Konflikt + Zufriedenh, family = cumulative(parallel = F ~
## Zufriedenh), data = mydata)
##
##
## Coefficients:
## (Intercept):1 (Intercept):2 (Intercept):3 Konflikt Zufriedenh:1
## 0.6614816 1.5373699 2.7337389 0.5705897 -1.9684047
## Zufriedenh:2 Zufriedenh:3
## -1.2805318 -0.8865225
##
## Degrees of Freedom: 1245 Total; 1238 Residual
## Residual deviance: 914.4929
## Log-likelihood: -457.2464
parallel=T~Konflikt-1 bedeutet, dass equal slopes nur für Konflikt angenommen wird.
parallel=F~Zufriedenh bedeutet, dass equal slopes nur für Zufriedenhnicht angenommen wird.
Beide Befehle bedeuten also das selbe. Daher ist die R-Ausgabe bei beiden Befehlen gleich.
## Estimate lCI uCI SD z p-value OR
## [1,] 0.5705897 0.3801667 0.7610126 0.09715456 5.873009 4.279541e-09 1.76931
33.5.2 Continuation Ratio Model
Um ein Continuation Ratio Modell zu rechnen, muss der Parameter family auf cratio gesetzt werden.
# CR-Modell MIT PO-Assumption (Vorwärts)crm<-vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cratio(parallel=T,reverse=F))summary(crm)
##
## Call:
## vglm(formula = Stimmung ~ Konflikt + Zufriedenh, family = cratio(parallel = T,
## reverse = F), data = mydata)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept):1 0.92610 0.57405 1.613 0.1067
## (Intercept):2 -1.14132 0.57924 -1.970 0.0488 *
## (Intercept):3 -3.01660 0.60706 -4.969 6.72e-07 ***
## Konflikt -0.53645 0.08639 -6.209 5.32e-10 ***
## Zufriedenh 1.16010 0.17944 6.465 1.01e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Names of linear predictors: logitlink(P[Y>1|Y>=1]), logitlink(P[Y>2|Y>=2]),
## logitlink(P[Y>3|Y>=3])
##
## Residual deviance: 924.3824 on 1240 degrees of freedom
##
## Log-likelihood: -462.1912 on 1240 degrees of freedom
##
## Number of Fisher scoring iterations: 6
##
## No Hauck-Donner effect found in any of the estimates
##
##
## Exponentiated coefficients:
## Konflikt Zufriedenh
## 0.5848225 3.1902597
Dies berechnet standardmäßig die Vorwärts-Methode. Möchte man die Rückwärts-Methode rechnen, setzt man den Parameter reverse auf TRUE.
# CR-Modell MIT PO-Assumption (Rückwärts)crm<-vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cratio(parallel=T,reverse=TRUE))summary(crm)
##
## Call:
## vglm(formula = Stimmung ~ Konflikt + Zufriedenh, family = cratio(parallel = T,
## reverse = TRUE), data = mydata)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept):1 0.12822 0.57259 0.224 0.822809
## (Intercept):2 2.08751 0.58094 3.593 0.000326 ***
## (Intercept):3 4.04245 0.60636 6.667 2.62e-11 ***
## Konflikt 0.45234 0.08488 5.329 9.88e-08 ***
## Zufriedenh -1.25631 0.18108 -6.938 3.98e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Names of linear predictors: logitlink(P[Y<2|Y<=2]), logitlink(P[Y<3|Y<=3]),
## logitlink(P[Y<4|Y<=4])
##
## Residual deviance: 920.4627 on 1240 degrees of freedom
##
## Log-likelihood: -460.2314 on 1240 degrees of freedom
##
## Number of Fisher scoring iterations: 5
##
## No Hauck-Donner effect found in any of the estimates
##
##
## Exponentiated coefficients:
## Konflikt Zufriedenh
## 1.5719790 0.2847038
Hat man die passende Methode gewählt, folgen die selben Befehle wie beim Proportional Odds Modell. Zunächst muss überprüft werden, ob “equal slopes” vorliegen:
# CR-Modell OHNE PO-Assumption (Rückwärts)ncrm<-vglm(Stimmung ~ Konflikt+Zufriedenh, data=mydata, family=cratio(parallel=F,reverse=T));summary(ncrm)
##
## Call:
## vglm(formula = Stimmung ~ Konflikt + Zufriedenh, family = cratio(parallel = F,
## reverse = T), data = mydata)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept):1 2.3649 1.1740 2.014 0.043969 *
## (Intercept):2 1.9998 0.8117 2.464 0.013753 *
## (Intercept):3 2.4670 1.1190 2.205 0.027474 *
## Konflikt:1 0.1465 0.1811 0.809 0.418633
## Konflikt:2 0.4864 0.1194 4.073 4.65e-05 ***
## Konflikt:3 0.6308 0.1689 3.736 0.000187 ***
## Zufriedenh:1 -1.8008 0.3919 -4.596 4.32e-06 ***
## Zufriedenh:2 -1.2602 0.2578 -4.889 1.01e-06 ***
## Zufriedenh:3 -0.8351 0.3382 -2.469 0.013543 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Names of linear predictors: logitlink(P[Y<2|Y<=2]), logitlink(P[Y<3|Y<=3]),
## logitlink(P[Y<4|Y<=4])
##
## Residual deviance: 914.7924 on 1236 degrees of freedom
##
## Log-likelihood: -457.3962 on 1236 degrees of freedom
##
## Number of Fisher scoring iterations: 6
##
## No Hauck-Donner effect found in any of the estimates
##
##
## Exponentiated coefficients:
## Konflikt:1 Konflikt:2 Konflikt:3 Zufriedenh:1 Zufriedenh:2 Zufriedenh:3
## 1.1577337 1.6264285 1.8791766 0.1651675 0.2836103 0.4338519
# loglikelihood test auf equal slopes assumptionlrtest(ncrm,crm)# Test
## Likelihood ratio test
##
## Model 1: Stimmung ~ Konflikt + Zufriedenh
## Model 2: Stimmung ~ Konflikt + Zufriedenh
## #Df LogLik Df Chisq Pr(>Chisq)
## 1 1236 -457.40
## 2 1240 -460.23 4 5.6703 0.2252
Der Test ist nicht signifikant (p=0,23). Das bedeutet, dass die Annahme der equal slopes für die hier getesteten Rückwärts-Modelle beibehalten werden kann.
Nun können weitere Modellparameter bestimmt werden:
## Estimate lCI uCI SD z p-value OR
## [1,] 0.4523353 0.2859635 0.6187071 0.08488357 5.328892 9.881398e-08 1.571979
get.ci(as.numeric(crm.ce[5,]))
## Estimate lCI uCI SD z p-value OR
## [1,] -1.256306 -1.611224 -0.9013879 0.1810807 -6.937825 3.981704e-12 0.2847038
33.6 Konfidenzintervalle
Konfidenzintervalle folgen der Logik, dass zum Punktschätzwert ein gewisser Fehlerbereich addiert und subtrahiert wird. Hierdurch wird ein Intervall mit Unter- und Obergrenze aufgezogen, das mit einer bestimmten Irrtumswahrscheinlichkeit den “wahren Wert” der Grundgesamtheit enthält.
33.6.1 Normalverteilung
Um ein Konfidenzintervall für einen Mittelwert aus einer normalverteilten Wertemenge zu berechnen wird folgende Formel angewendet:
##
## One Sample t-test
##
## data: x
## t = 27.806, df = 19, p-value < 2.2e-16
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 46.65246 54.24754
## sample estimates:
## mean of x
## 50.45
Über die Zusatzparameter $estimate und $conf.int kann die Ausgabe auf Median und Konfidenzgrenzen beschränkt werden.
Damit die Ausgabe schöner wird, wickeln wir noch as.numeric() außen herum.
as.numeric(t.test(x)$conf.int)
## [1] 46.65246 54.24754
Standardmäßig wird das 95%-Intervall berechnet. Über den Parameter conf.level können beliebige Konfidenzniveaus angegeben werden.
# 99%-Intervallt.test(x, conf.level=0.99)
##
## One Sample t-test
##
## data: x
## t = 27.806, df = 19, p-value < 2.2e-16
## alternative hypothesis: true mean is not equal to 0
## 99 percent confidence interval:
## 45.25918 55.64082
## sample estimates:
## mean of x
## 50.45
Wenn die Daten selbsst nicht vorliegen, sondern lediglich die Kennwerte bekannt sind, müssen wir die Grenzen von Hand ausrechnen. Nehmen wir an, eine Zufalls-Erhebung über die jährlichen Ausgaben für Pflegehilfsmittel ergab bei 100 Befragten (n = 100) einen Mittelwert \(\bar{x}\)=400,-€ bei einer Standardabweichung von s=20,-€. Das Konfidenzintervall für \(\alpha\)=0.05 wird nun wie folgt bestimmt.
# schreibe gegebene Werte in Variablenn <-100xquer <-400s <-20# 95%KI-Fehler berechnen mit (alpha/2) fehler95 <-qt(0.975, df=n-1)*s/sqrt(n)# Fehlerwert ausgebenfehler95
## [1] 3.968434
Beachten Sie, dass in der Funktion qt() zur Bestimmung des kritischen t-Wertes die Irrtumswahrscheinlichkeit \(\alpha\) halbiert werden muss, da es sich um eine zweiseitige Fragestellung handelt. So muss qt() nicht mit dem Wert 0.95 (\(\alpha=0.05\)) aufgerufen werden, sondern mit 0.975 (\(\frac{\alpha}{2}=0.025\)).
# untere Grenze des 95%KIxquer - fehler95
## [1] 396.0316
Die untere Grenze des 95%-Konfidenzintervalls liegt bei 396.0316 Euro.
# obere Grenze des 95%KIxquer + fehler95
## [1] 403.9684
Die obere Grenze des 95%-Konfidenzintervalls liegt bei 403.9684 Euro.
# Länge des 95%KI(xquer + fehler95) - (xquer - fehler95)
## [1] 7.936868
# oder schlauer2*fehler95
## [1] 7.936868
Das 95%-Konfidenzintervall hat eine Länge von 7.936868 Euro.
Für das 99% Konfidenzintervall ändern wir entsprechend um. Auch hier muss, da es sich um eine zweiseitige Fragestellung handelt, mit \(\frac{\alpha}{2}\), also 0.005, gerechnet werden. In der Funktion qt() ändert sich also der Wert auf 0,995.
##
## Welch Two Sample t-test
##
## data: x and y
## t = -1.2848, df = 26.194, p-value = 0.2101
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -6.628295 1.528295
## sample estimates:
## mean of x mean of y
## 50.45 53.00
Über die Parameter $estimate und $conf.int können wir die Ausgabe auf unsere Werte beschränken.
u <-t.test(x,y)# Unterschied der Mittelwerteas.numeric(u$estimate[2]) -as.numeric(u$estimate[1])
## [1] 2.55
# Konfidenzintervallas.numeric(u$conf.int)
## [1] -6.628295 1.528295
Standardmäßig wird das 95%-Intervall berechnet. Über den Parameter conf.level können beliebige Konfidenzniveaus angegeben werden.
# 99%-Intervallt.test(x, y, conf.level=0.99)
##
## Welch Two Sample t-test
##
## data: x and y
## t = -1.2848, df = 26.194, p-value = 0.2101
## alternative hypothesis: true difference in means is not equal to 0
## 99 percent confidence interval:
## -8.061928 2.961928
## sample estimates:
## mean of x mean of y
## 50.45 53.00
Liegen uns lediglich die Kennwerte der Verteilungen vor, müssen wir das Intervall von Hand ausrechnen. Nehmen wir an, in einer Studie wurde die Wirkung von zwei Medikamenten auf den Magnesiumgehalt des Blutserums (in mg/dl) untersucht. 13 Personen erhielten Medikament A und 10 Personen Medikament B. Nach 6 Wochen wurden folgende Daten bestimmt:
\(\bar{x}_{A}\) = 2,22 mg/dl
\(\bar{x}_{B}\) = 2,70 mg/dl
\(s_{A}\) = 0,255 mg/dl
\(s_{B}\) = 0,306 mg/dl
\(n_{A}\) = 13
\(n_{B}\) = 10
Das Konfidenzintervall für den Unterschied der Mittelwerte bei \(\alpha=0,05\) wird nun wie folgt bestimmt (Achtung, da es sich um eine zweiseitige Fragestellung handelt, müssen wir mit \(\frac{\alpha}{2} =0,025\) rechnen).
# erzeuge die Datenxa <-2.22xb <-2.7sa <-0.255sb <-0.306na <-13nb <-10# Differenz der Mittelwerted <- xb - xa# ausgebend
Die untere Grenze des 95%-Konfidenzintervalls liegt bei 0.4125813 mg/dl.
# obere Grenze des 95%KId + fehler95
## [1] 0.5474187
Die obere Grenze des 95%-Konfidenzintervalls liegt bei 0.5474187 mg/dl.
# Länge des Intervalls2*fehler95
## [1] 0.1348373
Das 95%-Konfidenzintervall hat eine Länge von 0.1348373 mg/dl.
Für das 99%-Konfidenzintervall wird der Wert für die Funktion qt() auf 0.995 gesetzt (da es sich um eine zweiseitige Fragestellung handelt, müssen wir mit \(\frac{\alpha}{2} = 0,005\) rechnen).
# Konfidenzintervall für Anteil "ja"prop.test(freq[["ja"]], length(antwort))
##
## 1-sample proportions test with continuity correction
##
## data: freq[["ja"]] out of length(antwort), null probability 0.5
## X-squared = 4.5, df = 1, p-value = 0.03389
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.5191861 0.9262769
## sample estimates:
## p
## 0.7777778
# Konfidenzintervall für Anteil "nein"prop.test(freq[["nein"]], sum(freq))
##
## 1-sample proportions test with continuity correction
##
## data: freq[["nein"]] out of sum(freq), null probability 0.5
## X-squared = 4.5, df = 1, p-value = 0.03389
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.0737231 0.4808139
## sample estimates:
## p
## 0.2222222
Wenn die Werte der absoluten Häufigkeitstabelle bekannt sind, können die Werte auch direkt an die Funktion übergeben werden. Angenommen, von 120 Studierenden hätten 95 die Abschlussprüfung bestanden, dann lautet der Funktionsaufruf für den Anteil “bestanden” entsprechend:
prop.test(95, 120)
##
## 1-sample proportions test with continuity correction
##
## data: 95 out of 120, null probability 0.5
## X-squared = 39.675, df = 1, p-value = 2.999e-10
## alternative hypothesis: true p is not equal to 0.5
## 95 percent confidence interval:
## 0.7059845 0.8582409
## sample estimates:
## p
## 0.7916667
Über die Zusatzparameter $estimate und $conf.int kann die Ausgabe auf die Konfidenzgrenzen beschränkt werden.
# Konfidenzintervall für Anteil "ja"prop.test(95, 120)$conf.int
##
## 1-sample proportions test with continuity correction
##
## data: 95 out of 120, null probability 0.5
## X-squared = 39.675, df = 1, p-value = 2.999e-10
## alternative hypothesis: true p is not equal to 0.5
## 99 percent confidence interval:
## 0.6775964 0.8738928
## sample estimates:
## p
## 0.7916667
Wenn die absolute Häufigkeitstabelle nicht vollständig vorliegt, müssen wir von Hand rechnen. Nehmen wir an, in einer klinischen Studie wurde an 150 Patienten die Dekubitusprävalenz ermittelt. Dabei wurde eine Prävalenz von 35% festgestellt. Die Konfidenzintervalle für den “wahren Wert” der Grundgesamtheit wird wie folgt bestimmt.
Beachten Sie, dass in der Funktion qnorm() die Irrtumswahrscheinlichkeit \(\alpha\) halbiert werden muss, da es sich um eine zweiseitige Fragestellung handelt. So muss qnorm() nicht mit dem Wert 0.95 (\(\alpha=0.05\)) aufgerufen werden, sondern mit 0.975 (\(\frac{\alpha}{2}=0.025\)).
# untere Grenze des KIk - fehler95
## [1] 0.2736704
Die untere Grenze des 95%-Konfidenzintervalls liegt bei 0.2736704 = 27,36704%.
# obere Grenze des KIk + fehler95
## [1] 0.4263296
Die obere Grenze des 95%-Konfidenzintervalls liegt bei 0.4263296 = 42,63296%.
# Länge des KI2*fehler95
## [1] 0.1526593
Das 95%-Konfidenzintervall hat eine Länge von 0.1526593 = 15,26593%.
Für das 99%-Konfidenzintervall muss der Wert der Funktion qnorm() auf 0.995 (\(\frac{\alpha}{2}=0,005\)) angepasst werden.
# Fehler berechnen mit (alpha/2)!fehler99 <-qnorm(0.995)*sqrt(k*(1-k)/n)# anzeigenfehler99
## [1] 0.1003141
# untere Grenze des KIk - fehler99
## [1] 0.2496859
Die untere Grenze des 99%-Konfidenzintervalls liegt bei 0.2496859 = 24,96859%.
# obere Grenze des KIk + fehler99
## [1] 0.4503141
Die obere Grenze des 99%-Konfidenzintervalls liegt bei 0.4503141 = 45,03141%.
# Länge des KI2*fehler99
## [1] 0.2006283
Das 99%-Konfidenzintervall hat eine Länge von 0.2006283 = 20,06283%.
Die Funktion KIbinomial_a() aus dem jgsbook-Paket nimmt uns auch hier die vorgestellten Rechenschritte ab.
# Berechne das 95%-KIjgsbook::KIbinomial_a(p=0.35, n=150, alpha=0.05)
## x y
## 1 0.95 KI untere Grenze 0.2736704
## 2 0.95 KI obere Grenze 0.4263296
## 3 0.95 KI Laenge 0.1526593
# Berechne das 99%-KIjgsbook::KIbinomial_a(p=0.35, n=150, alpha=0.01)
## x y
## 1 0.99 KI untere Grenze 0.2496859
## 2 0.99 KI obere Grenze 0.4503141
## 3 0.99 KI Laenge 0.2006283
33.6.2.1 Unterschied von Anteilswerten
Zur Berechnung der Konfidenzintervalle bei Unterschieden von Anteils- werten wird die folgende Formel verwendet.
## geschlecht
## antwort m w
## ja 7 6
## nein 2 3
# Konfidenzintervall für Anteil "ja" zwischen "m" und "w"prop.test(c(freq[["ja","m"]], freq[["ja","w"]]), c(sum(freq[,"m"]), sum(freq[,"w"])))
##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(freq[["ja", "m"]], freq[["ja", "w"]]) out of c(sum(freq[, "m"]), sum(freq[, "w"]))
## X-squared = 0, df = 1, p-value = 1
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.4106382 0.6328604
## sample estimates:
## prop 1 prop 2
## 0.7777778 0.6666667
Wenn alle Daten der Kreuztabelle vorliegen, können die Werte auch direkt an die Funktion übergeben werden. Angenommen wir wissen, dass von 9 Frauen 6 mit “ja” geantwortet haben, und von 9 Männern 7, dann können wir das Konfidenzintervall für den Anteilsunterschied wie folgt berechnen:
# Unterschied im Anteil "ja"prop.test(c(7, 6), c(9, 9))
##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(7, 6) out of c(9, 9)
## X-squared = 0, df = 1, p-value = 1
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.4106382 0.6328604
## sample estimates:
## prop 1 prop 2
## 0.7777778 0.6666667
Über die Zusatzparameter $estimate und $conf.int kann die Ausgabe auf die Konfidenzgrenzen beschränkt werden.
# Konfidenzintervall für Anteilsunterschied "ja"prop.test(c(7, 6), c(9, 9))$conf.int
##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(7, 6) out of c(9, 9)
## X-squared = 0, df = 1, p-value = 1
## alternative hypothesis: two.sided
## 99 percent confidence interval:
## -0.5396700 0.7618923
## sample estimates:
## prop 1 prop 2
## 0.7777778 0.6666667
Wenn wir keine absoluten Zahlen vorliegen haben, müssen wir von Hand rechnen. Nehmen wir an, in Bundesland A gaben 25% von 100 Befragten an, Zuzahlungen bei Pflegehilfsmitteln leisten zu müssen. In Bundesland B wurden 150 Personen befragt, von denen 40% von Zuzahlungen betroffen waren. Der Punktschätzwert für die Differenz dˆ beträgt folglich 0,40-0,25 = 0,15.
Die Konfidenzintervalle für die wahre Differenz d kann nun wie folgt bestimmt werden.
Beachten Sie, dass in der Funktion qnorm() die Irrtumswahrscheinlichkeit \(\alpha\) halbiert werden muss, da es sich um eine zweiseitige Fragestellung handelt. So muss qnorm() nicht mit dem Wert 0.95 (\(\alpha=0.05\)) aufgerufen werden, sondern mit 0.975 (\(\frac{\alpha}{2}=0.025\)).
# 95%KI-Fehler berechnen mit (alpha/2) fehler95 <-qnorm(0.975)*sqrt(p1*(1-p1)/n1 + p2*(1-p2)/n2)#anzeigenfehler95
## [1] 0.1155382
# untere Grenze des 95%KId - fehler95
## [1] 0.03446183
Die untere Grenze des 95%-Konfidenzintervalls liegt bei 0.03446183 = 3,446183%.
# obere Grenze des 95%KId + fehler95
## [1] 0.2655382
Die obere Grenze des 95%-Konfidenzintervalls liegt bei 0.2655382 = 26,55382%.
# Länge des KI2*fehler95
## [1] 0.2310763
Die Länge des 95%-Konfidenzintervalls liegt bei 0.2310763 = 23,10763%.
Für das 99%-Konfidenzintervall muss der Wert der Funktion qnorm() auf 0.995 (\(\frac{\alpha}{2}=0,005\)) angepasst werden.
# 99%KI-Fehler berechnen mit (alpha/2) fehler99 <-qnorm(0.995)*sqrt(p1*(1-p1)/n1 + p2*(1-p2)/n2)#anzeigenfehler99
## [1] 0.1518429
# untere Grenze des 99%KId - fehler99
## [1] -0.001842898
Die untere Grenze des 99%-Konfidenzintervalls liegt bei -0.0018429 = -0,18429%.
# obere Grenze des 99%KId + fehler99
## [1] 0.3018429
Die obere Grenze des 99%-Konfidenzintervalls liegt bei 0.3018429 = 30,18429%.
# Länge des KI2*fehler99
## [1] 0.3036858
Die Länge des 99%-Konfidenzintervalls liegt bei 0.3036858 = 30,36858%.
Wie Sie sehen, liegt die untere Grenze des 99%-Konfidenzintervalls im negativen Bereich. Errechnet sich ein Intervall, welches die 0 einschließt, bedeutet dies, dass der wahre Unterschied auch 0 sein könnte.
Die Funktion KIbinomail_u() aus dem jgsbook-Paket nimmt uns auch hier die vorgestellten Rechenschritte ab.
# Berechne das 95%-KIjgsbook::KIbinomial_u(p1, n1, p2, n2, alpha=0.05)
## x y
## 1 Differenz der Anteile 0.15000000
## 2 0.95 KI untere Grenze 0.03446183
## 3 0.95 KI obere Grenze 0.26553817
## 4 0.95 KI Laenge 0.23107635
# Berechne das 99%-KIjgsbook::KIbinomial_u(p1, n1, p2, n2, alpha=0.01)
## x y
## 1 Differenz der Anteile 0.150000000
## 2 0.99 KI untere Grenze -0.001842898
## 3 0.99 KI obere Grenze 0.301842898
## 4 0.99 KI Laenge 0.303685796
33.7 Signifikanztests
33.7.1\(\chi^2\)-Test
Der \(\chi^2\)-Test wird mit der Funktion chisq.test() durchgeführt. Hierfür müssen die Daten als Kreuztabelle vorliegen.
# lade Testdatenload(url("https://www.produnis.de/R/data/nw.RData"))# erstelle Kreuztabelle aus Alter und Geschlechtxtabelle <-xtabs(~ nw$age + nw$sex)# Führe Chiquadrat-Test durchchisq.test(xtabelle)
## Warning in chisq.test(xtabelle): Chi-Quadrat-Approximation kann inkorrekt sein
Der p-Wert ist nicht signifikant, das heisst, das kein Zusammenhang gefunden werden konnte.
Die Warnung bedeutet, dass der p-Wert aus sehr kleinen Zellenhäufigkeiten (kleiner 5) geschätzt wurde, und daher fehlerhaft sein kann (wir sollten daher einen exakten Test durchführen, zum Beispiel den Fisher-Test).
Der exakte Fisher-Test wird mit der Funktion fisher.test() durchgeführt.
# Führe Fisher-Test durchfisher.test(xtabelle)
Fisher's Exact Test for Count Data with simulated p-value (based on 2000 replicates)
data: nw$sex and nw$age
p-value = 0.3848
alternative hypothesis: two.sided
Der exakte Fisher-Test bestätigt, dass es keinen Unterschied gibt.
33.7.3 t-Test
Der t-Test ist wohl einer der bekanntesten Signifikanztests. In R wird er mit der Funktion t.test() ausgeführt.
33.7.3.1 Einstichproben t-Test
Beim Einstichproben t-Test wird der Mittelwert der Grundgesamtheit über den Parameter mu mitgegeben. Schauen wir, ob im Nachtwachendatensatz das Alter von einem gedachten Mittelwert 40 in der Grundgesamtheit abweicht.
# lade Testdatenload(url("https://www.produnis.de/R/data/nw.RData"))# Führe t-Test für "Alter" auf Mittelwert 40 durcht.test(nw$age, mu=40)
##
## One Sample t-test
##
## data: nw$age
## t = 6.8274, df = 275, p-value = 5.524e-11
## alternative hypothesis: true mean is not equal to 40
## 95 percent confidence interval:
## 43.00908 45.44744
## sample estimates:
## mean of x
## 44.22826
Der Test ist signifikant, das bedeutet, das Alter im Datensatz nw weicht von einem Mittelwert in der Grundgesamtheit von 40 ab. Es liegt ein Unterschied vor.
Zur Beschreibung der Effektstärke des Unterschieds können wir Cohen’s d berechnen. Dies kann über das Zusatzpaket lsr und der Funktion cohensD() erfolgen.
Für den Vergleich der Mittelwerte bei unabhängige Stichproben werden die Werte beider Gruppen als Variable übergeben. So können wir z.B. schauen, ob sich die Datensätze nw und epa hinsichtlich des Alters unterscheiden
# t-test auf Alter in Datensatz "epa" und "nw"t.test(nw$age, epa$age)
##
## Welch Two Sample t-test
##
## data: nw$age and epa$age
## t = -19.316, df = 854.37, p-value < 2.2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -20.65610 -16.84545
## sample estimates:
## mean of x mean of y
## 44.22826 62.97903
Das Ergebnis ist signifikant, die Gruppen unterscheiden sich also.
Standardmäßig wird ein zweiseitiger Test durchgeführt. Über den Parameter alternative kann dies geändert werden.
# t-test einseitig, kleinert.test(nw$age, epa$age, alternative ="less")# t-test einseitig, größert.test(nw$age, epa$age, alternative ="greater")# t-test zweiseitigt.test(nw$age, epa$age, alternative ="two.sided")
Die Funktion nimmt auch die Syntax erklärt durch entgegen. Wir schauen, ob sich das Alter im Datensatz epa in den Geschlechtergruppen unterscheidet, also Alter erklärt durch Geschlecht.
# t-test Alter zwischen Geschlechtern im Datensatz "epa"t.test(age ~ sex, data=epa)
##
## Welch Two Sample t-test
##
## data: age by sex
## t = -4.7535, df = 595.03, p-value = 2.51e-06
## alternative hypothesis: true difference in means between group m and group w is not equal to 0
## 95 percent confidence interval:
## -9.923268 -4.120822
## sample estimates:
## mean in group m mean in group w
## 59.79646 66.81851
Das Ergebnis ist signifikant. Auch hier lässt sich wieder die Effektstärke Cohen’s D berechnen.
Bei gepaarten Werten muss ein abhängiger t-Test berechnet werden. Dies erfolgt über den Parameter paired, der auf TRUE gesetzt wird. Auch hier können wir wieder die Richtung (größer, kleiner, zweiseitig) über den Parameter alternative verändern.
Der F-Test wird mit der Funktion var.test() berechnet. So können wir prüfen, ob die Varianz des Alters im Datensatz epa in den Geschlechtergruppen unterschiedlich ist.
# lade Testdatenload(url("https://www.produnis.de/R/data/epa.RData"))# F-Test var.test(age ~ sex , data=epa)
##
## F test to compare two variances
##
## data: age by sex
## F = 0.98352, num df = 338, denom df = 280, p-value = 0.8816
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.7848842 1.2294811
## sample estimates:
## ratio of variances
## 0.983521
Der Test ist nicht signifikant, es liegt kein Unterschied in den Varianzen vor.
33.7.5 Levene-Test
Ebenso kann mit dem Levene-Test auf Varianzunterschied geprüft werden. Hierfür rufen wir die Funktion leveneTest() aus dem Zusatzpaket car auf.
## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 1 0.0232 0.8789
## 618
Der Test ist nicht signifikant, es liegt kein Unterschied in den Varianzen vor. Ein gutes Anleitungsvideo zum verbundenen Levene-Test findet sich bei Youtube: https://www.youtube.com/watch?v=717UWGnyQGA
33.7.6 Mann-Whitney-U-Test
Dies ist die nicht-parametrische alternative zum t-Test für unabhängige Stichproben. Er wird mit der Funktion wilcox.test() durchgeführt, wobei der Parameter paired auf FALSE gesetzt wird (ist die Standardeinstellung).
##
## Wilcoxon rank sum test with continuity correction
##
## data: epa$age by epa$sex
## W = 35862, p-value = 1.151e-07
## alternative hypothesis: true location shift is not equal to 0
Das Ergebnis ist signifikant, das Alter im Datensatz epa unterscheidet sich zwischen den Geschlechtern.
Mit dem Parameter conf.int kann das Konfidenzintervall des Schätzwertes mit ausgegeben werden.
# Man-Whitney-U-Test mit Konfidenzintervallwilcox.test(epa$age ~ epa$sex, conf.int=TRUE)
##
## Wilcoxon rank sum test with continuity correction
##
## data: epa$age by epa$sex
## W = 35862, p-value = 1.151e-07
## alternative hypothesis: true location shift is not equal to 0
## 95 percent confidence interval:
## -9.999986 -4.999952
## sample estimates:
## difference in location
## -7.000029
Dies ist die nicht-parametrische alternative zum abhängigen t-Test. Er wird mit der Funktion wilcox.test() durchfegührt, wobei der Parameter paired auf TRUE gesetzt werden muss. Andernfalls rechnet R einen Man-Whitney-U-Test.
##
## Wilcoxon signed rank test with continuity correction
##
## data: t0 and t1
## V = 805, p-value = 5.628e-09
## alternative hypothesis: true location shift is not equal to 0
Mit dem Parameter conf.int kann das Konfidenzintervall des Schätzwertes mit ausgegeben werden.
Zum Test auf Normalverteilung kann der Shapiro-Wilk-Test über die Funktion shapiro.test() verwendet werden. Die Nullhypothese lautet, dass eine Normalverteilung vorliegt. Testen wir, ob im Datensatz nw das Alter (age) normalverteilt ist.
# lade Testdatenload(url("https://www.produnis.de/R/data/nw.RData"))# Teste "age" auf Normalverteilungshapiro.test(nw$age)
##
## Shapiro-Wilk normality test
##
## data: nw$age
## W = 0.96636, p-value = 4.677e-06
Das Ergebnis ist signifikant, die Daten sind nicht normalverteilt.
Erzeugen wir normalverteilte Werte zur Gegenprobe.
# Test mit 100 zufälligen und normalverteilten Wertenshapiro.test(rnorm(100))
##
## Shapiro-Wilk normality test
##
## data: rnorm(100)
## W = 0.99307, p-value = 0.8921
Das Ergebnis ist (wie erwartet) nicht signifikant, das heisst, unsere Zufallszahlen sind wirklich normalverteilt.
Der Shapiro-Wilk-Test funktioniert nur bis zu einer Stichprobengröße von \(n=5000\). Besteht der Datensatz aus mehr Fällen, kann auf den Kolmogorov-Smirnov-Test ausgewichen werden.
33.7.9 Kolmogorov-Smirnov-Test
Der Kolmogorov-Smirnov-Test prüft die Nullhypothese, dass die Daten einer bestimmten Verteilung (z.B. der Normalverteilung) folgen. In R ist er über die Funktion ks.test() implementiert.
Prüfen wir nun also mittels Kolmogorov-Smirnov-Test, ob im Datensatz nw das Alter (age) normalverteilt ist.
# lade nw Datensatzload(url("https://www.produnis.de/R/data/nw.RData"))# Teste, ob Alter normalverteilt istks.test(nw$age, "pnorm")
##
## Asymptotic one-sample Kolmogorov-Smirnov test
##
## data: nw$age
## D = 1, p-value < 2.2e-16
## alternative hypothesis: two-sided
Der Test ist signifikant, das heisst, es liegt keine Normalverteilung vor.
Die Testparameter können zudem auf die Lage- und Streuungskenngrößen der Wertereihe angepasst werden.
# passe auf Kenngrößen anks.test(nw$age, "pnorm", mean =mean(nw$age, na.rm =TRUE), sd =sd(nw$age, na.rm =TRUE))
##
## Asymptotic one-sample Kolmogorov-Smirnov test
##
## data: nw$age
## D = 0.11477, p-value = 0.001391
## alternative hypothesis: two-sided
Auch dieser Test ist signifikant, das heisst, es liegt keine Normalverteilung vor.
Machen wir nun den Gegentest mit normalverteilten Werten:
# erzeuge normalverteilte Dummywertedummy <-rnorm(10000)# Test auf Normalverteilungks.test(dummy, "pnorm", mean =mean(dummy), sd =sd(dummy))
##
## Asymptotic one-sample Kolmogorov-Smirnov test
##
## data: dummy
## D = 0.0059544, p-value = 0.8703
## alternative hypothesis: two-sided
Der Test ist nicht signifikant, das heisst, es liegen normalverteilte Werte vor.
33.8 Post-Hoc-Tests
Post-hoc-Tests werden verwendet, um paarweise Vergleiche nach einem initialen Test (wie ANOVA (siehe Abschnitt 33.9)) durchzuführen, der signifikante Unterschiede zwischen Gruppenmittelwerten anzeigt. Durch die Mehrfachvergleiche (multiples Testen) entsteht das erhöhte Risiko von falsch-positiven Ergebnissen (Typ-I-Fehler).
Post-Hoc-Tests helfen dabei, spezifische Gruppen zu identifizieren, die sich voneinander unterscheiden, während sie das Problem der Mehrfachtestung berücksichtigen.
R bietet mehrere Funktionen zur Durchführung von Post-hoc-Tests. In diesem Abschnitt bschränken wir uns auf die weit verbreiteten Funktionen reporttools::pairwise.fisher.test(), pairwise.wilcox.test() und pairwise.t.test().
33.8.1 Paarweise Chiquadrat
In R-base ist keine Funktion implementiert, die einen paarweisen Chiquadrat-Test durchführt. Das mag daran liegen, dass der Chiquadrat-Test als (weniger genaue) Alternative zu dem rechenaufwändigen exakten Fisher-Test entwickelt wurde. Mit der heutigen Computertechnologie ist es jedoch in den meisten Fällen kein Problem, den exakten Test nach Fisher auch auf älterer Hardware anzuwenden.
33.8.2 Paarweise Fisher-Test
Der pairwise.fisher.test aus dem Paket reporttools wird verwendet, um paarweise Vergleiche zwischen Gruppen durchzuführen, wenn nonimale Daten vorliegen.
Als Beispiel untersuchen wir im Datensatz pf8, ob sich die Geschlechter je nach Standort unterscheiden.
##
## Pairwise comparisons using
##
## data: pf8$Geschlecht and pf8$Standort
##
## Rheine Münster Bahn Ladbergen
## Münster 1.00000 - - -
## Bahn 1.00000 1.00000 - -
## Ladbergen 0.56615 0.24097 0.32261 -
## Internet 0.00262 0.02282 0.09245 0.00065
##
## P value adjustment method: holm
Als Ergebnis erhalten wir eine Tabelle mit p-Werten. Es ist zu erkennen, dass sich die Geschlechterverteilungen zwischen den Standortvergleichen Internet-Rheine, Internet-Münster und Internet-Landbergen unterscheiden.
33.8.3 Paarweise Wilcoxon-Test (Mann-Whitney-U)
Die Funktion pairwise.wilcox.test() wird verwendet, um paarweise Vergleiche zwischen Gruppen durchzuführen, wenn die Daten nicht normalverteilt sind. Dieser Test basiert auf dem Wilcoxon-Rangsummentest, auch bekannt als Mann-Whitney-U-Test, und ist eine nichtparametrische Methode, die keine Annahmen über die Verteilung der Daten erfordert.
Als Beispiel untersuchen wir im Datensatz pf8, ob sich das Alter der Probanden je nach Standort unterscheidet.
##
## Pairwise comparisons using Wilcoxon rank sum test with continuity correction
##
## data: pf8$Alter and pf8$Standort
##
## Rheine Münster Bahn Ladbergen
## Münster 1.00000 - - -
## Bahn 0.55704 1.00000 - -
## Ladbergen 0.56286 1.00000 1.00000 -
## Internet 0.02780 3.5e-05 0.00027 0.00062
##
## P value adjustment method: bonferroni
Als Ergebnis erhalten wir eine Tabelle mit p-Werten. Es ist zu erkennen, dass sich die Altersverteilungen zwischen den Standortvergleichen Internet-Rheine, Internet-Münster und Internet-Landbergen unterscheiden.
33.8.4 Paarweise t-Test
Die Funktion pairwise.t.test() wird verwendet, um paarweise Vergleiche zwischen Gruppen durchzuführen, wenn die Daten normalverteilt sind.
# erzeuge TestdatenGruppe <-factor(rep(c("Handball", "Fussball", "Volleyball"), each =10))Punkte <-c(rnorm(10, mean =5), rnorm(10, mean =6), rnorm(10, mean =7))# Führe paarweise t-Tests durchpairwise.t.test(Punkte, Gruppe, p.adjust.method ="holm")
##
## Pairwise comparisons using t tests with pooled SD
##
## data: Punkte and Gruppe
##
## Fussball Handball
## Handball 0.116 -
## Volleyball 0.391 0.025
##
## P value adjustment method: holm
Als Ergebnis erhalten wir eine Tabelle mit p-Werten. Es ist zu erkennen, dass sich die Punkteverteilungen zwischen Handball-Fussball, und Handball-Volleyball unterscheiden.
33.9 Varianzanalysen
33.9.1 ANOVA mit Messwiederholung
Eine ANOVA mit Messwiederholung kann wie folgt in R durchgeführt werden. Wir nutzen den Testdatensatz Messwiederholung.rda.
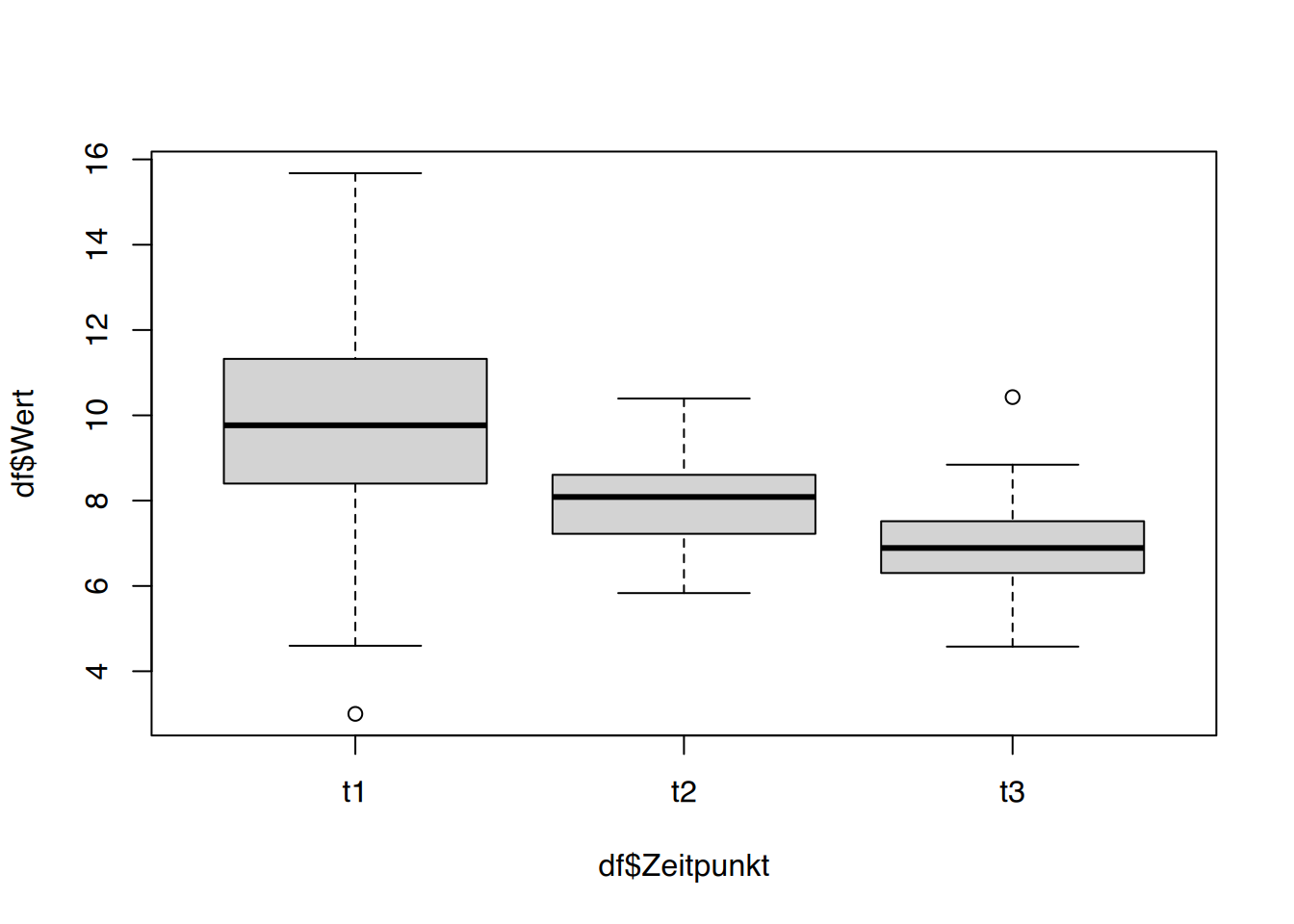
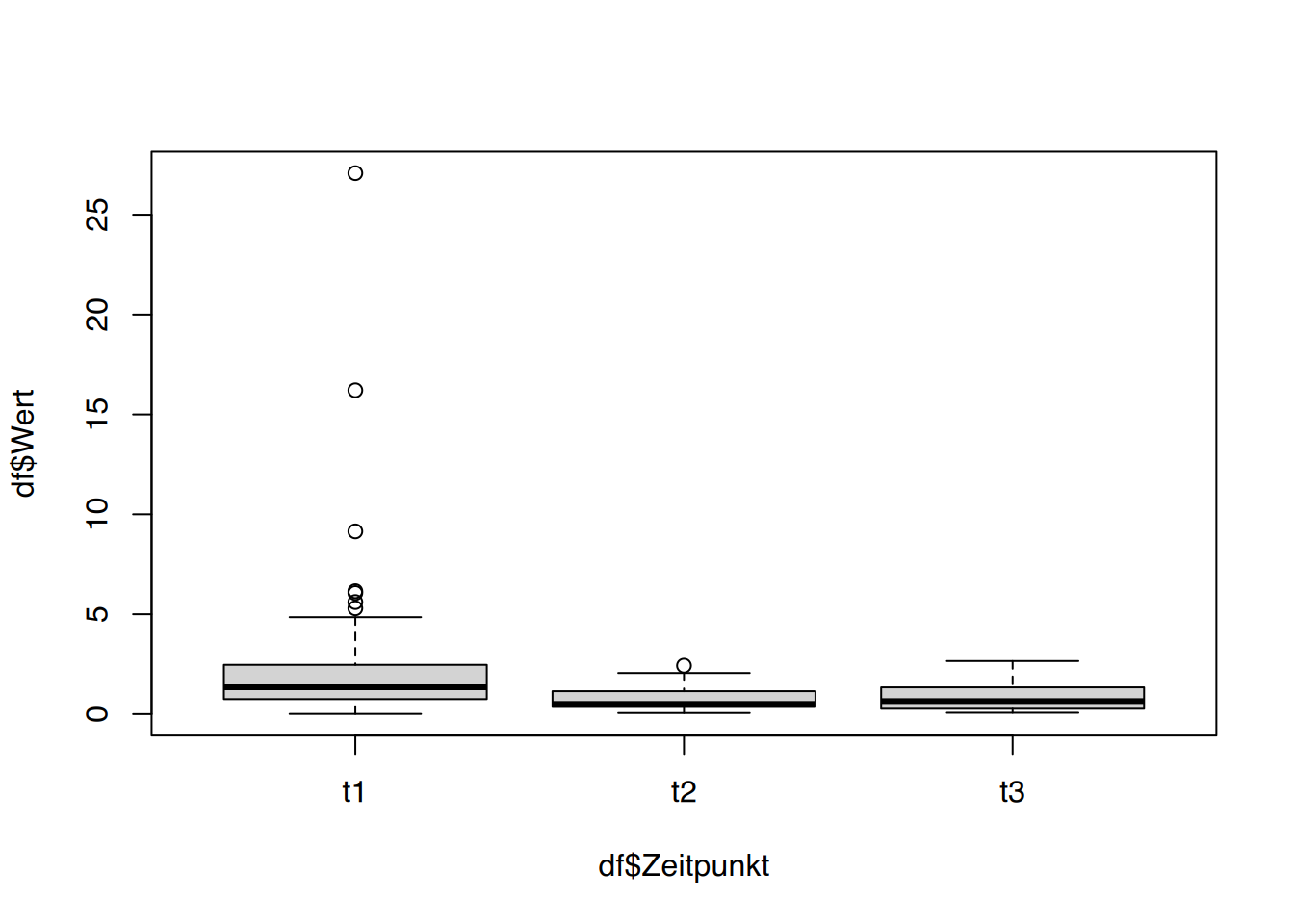
# mal graphisch anschauenboxplot(df$Wert ~ df$Zeitpunkt)
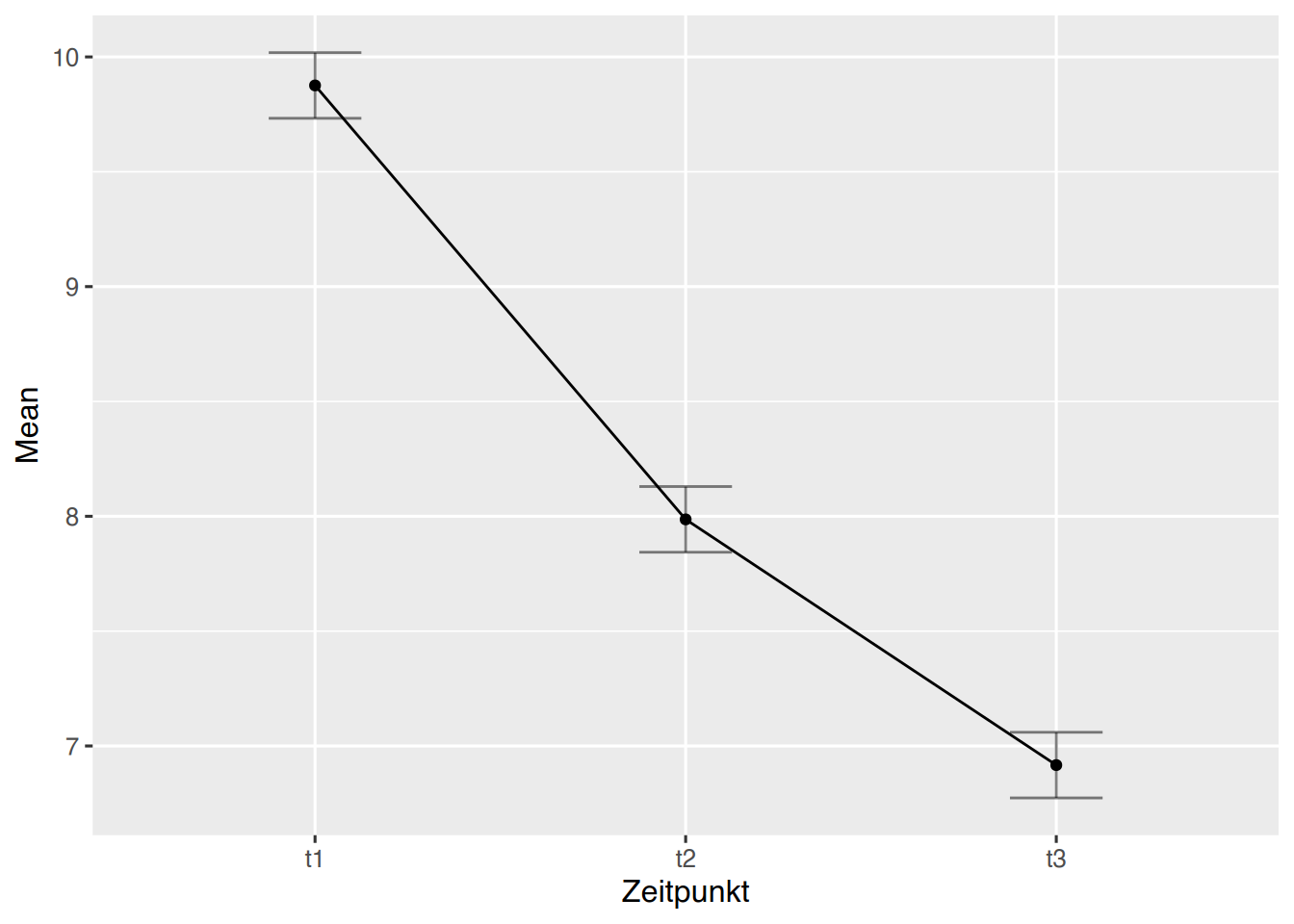
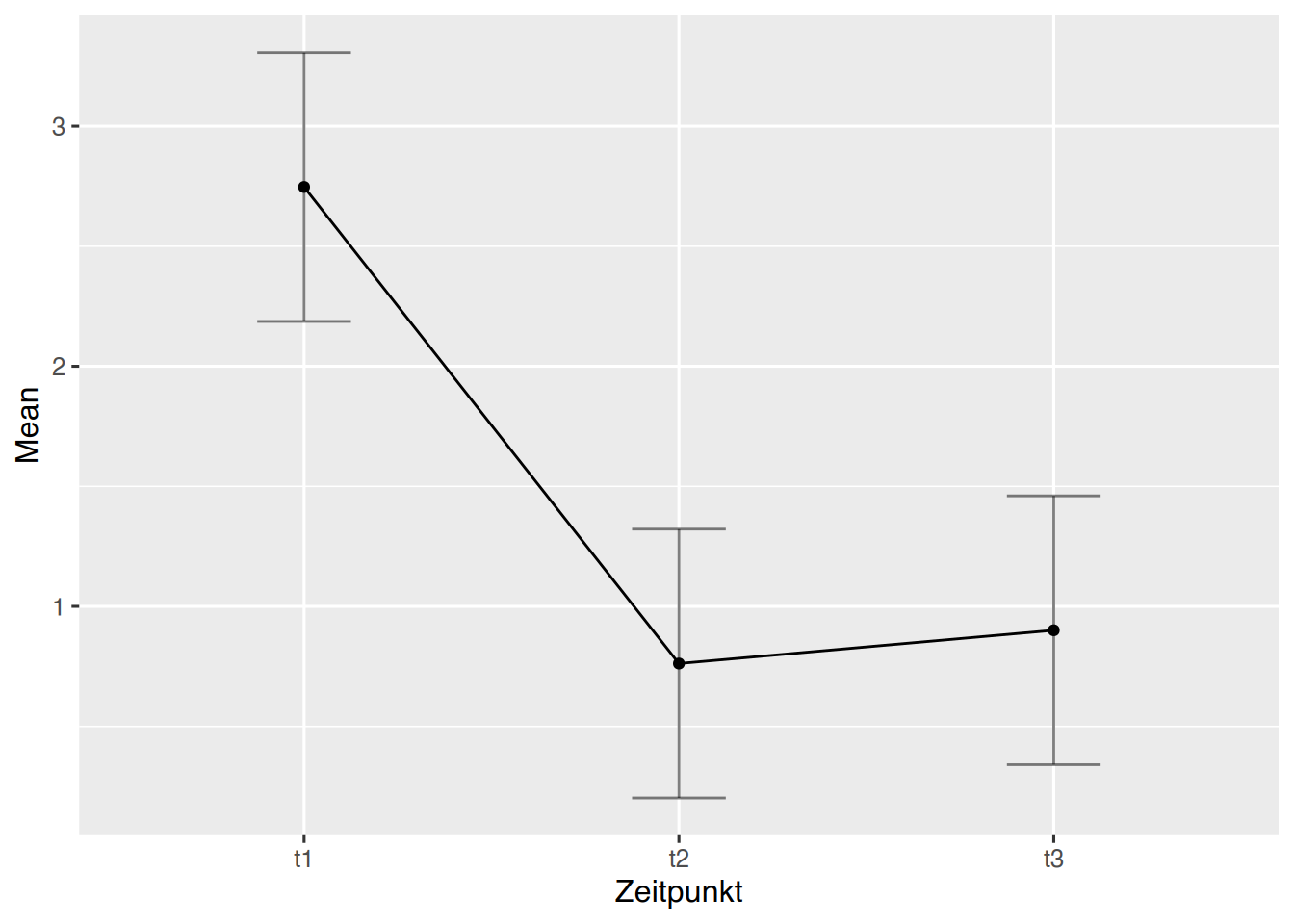
ez::ezPlot(df, Wert, Name, within = Zeitpunkt, x = Zeitpunkt)
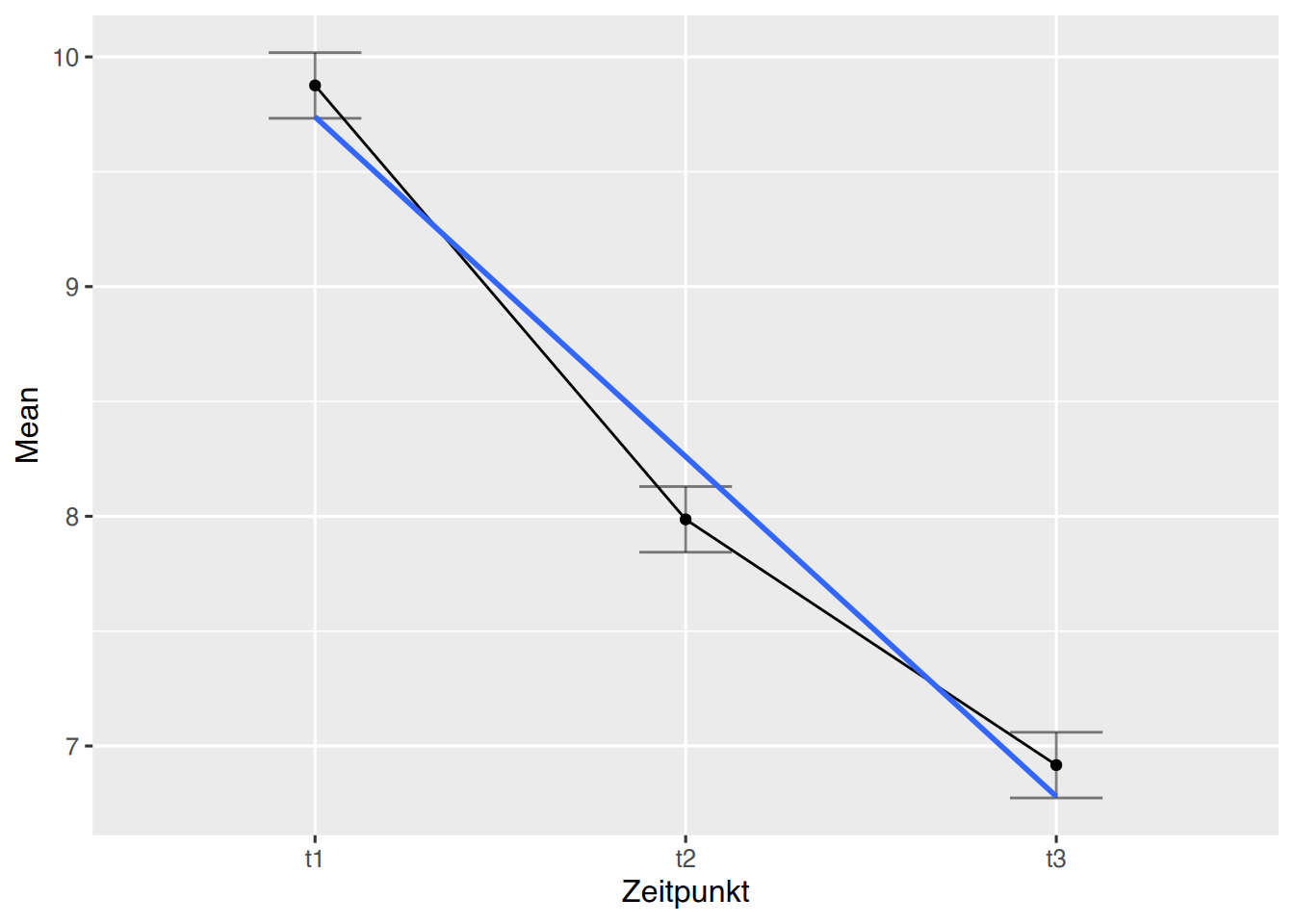
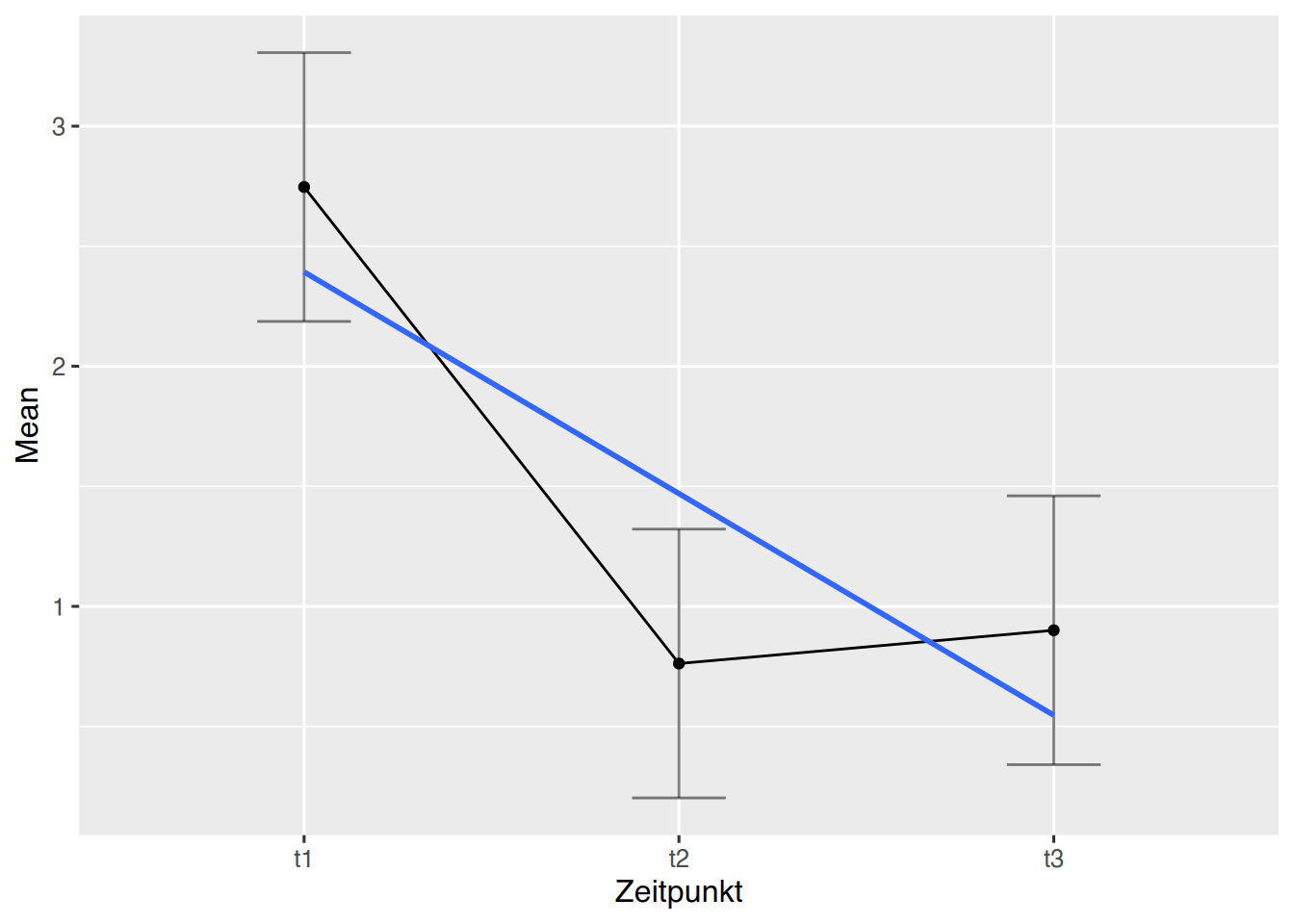
# mit Regressionsgeradeez::ezPlot(df, Wert, Name, within = Zeitpunkt, x = Zeitpunkt) +geom_smooth(aes(x =as.numeric(Zeitpunkt)), method ='lm', se = F)
## `geom_smooth()` using formula = 'y ~ x'
Die Plots legen nahe, dass es einen Unterschied in den Zeitpunktgruppen gibt.
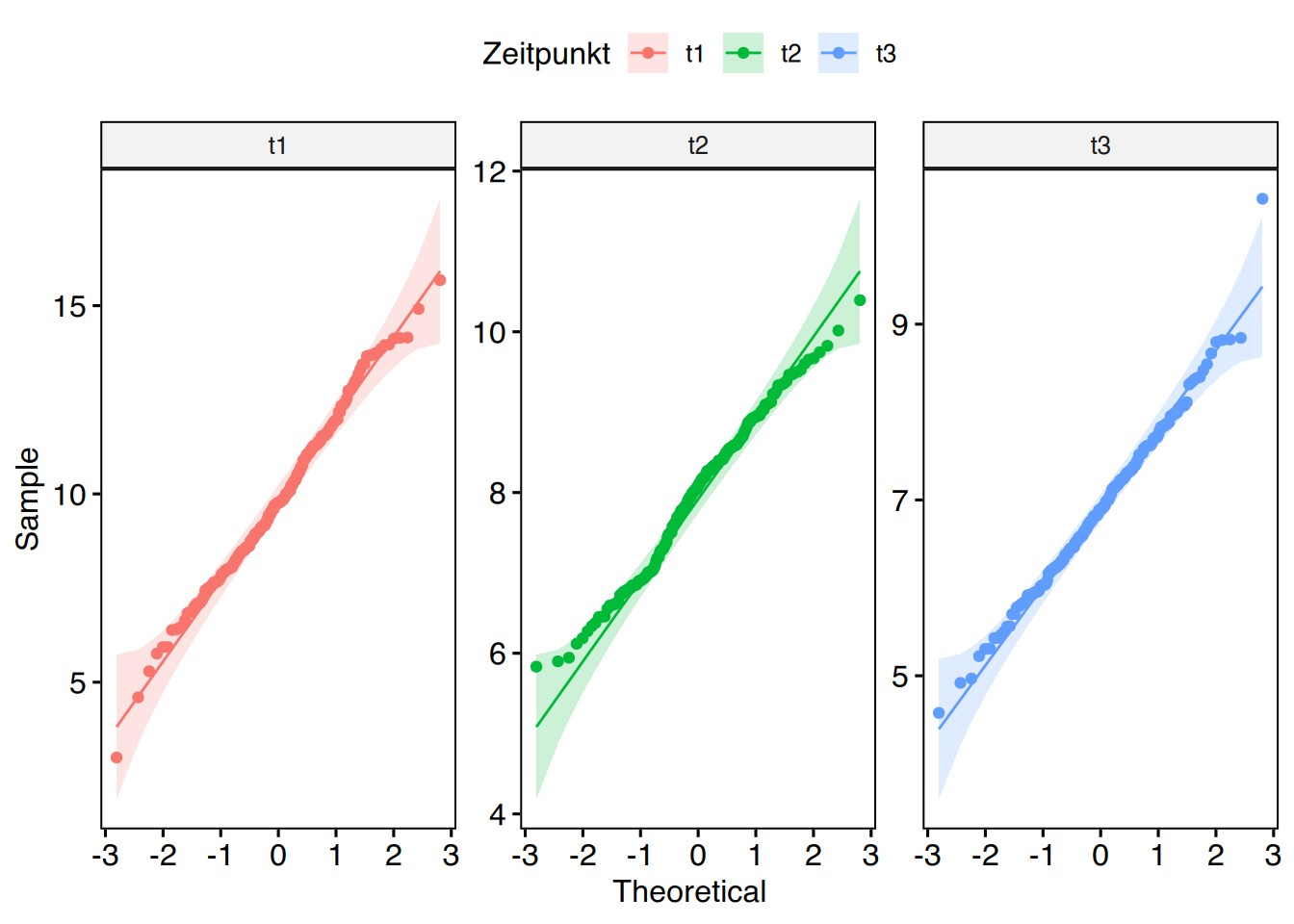
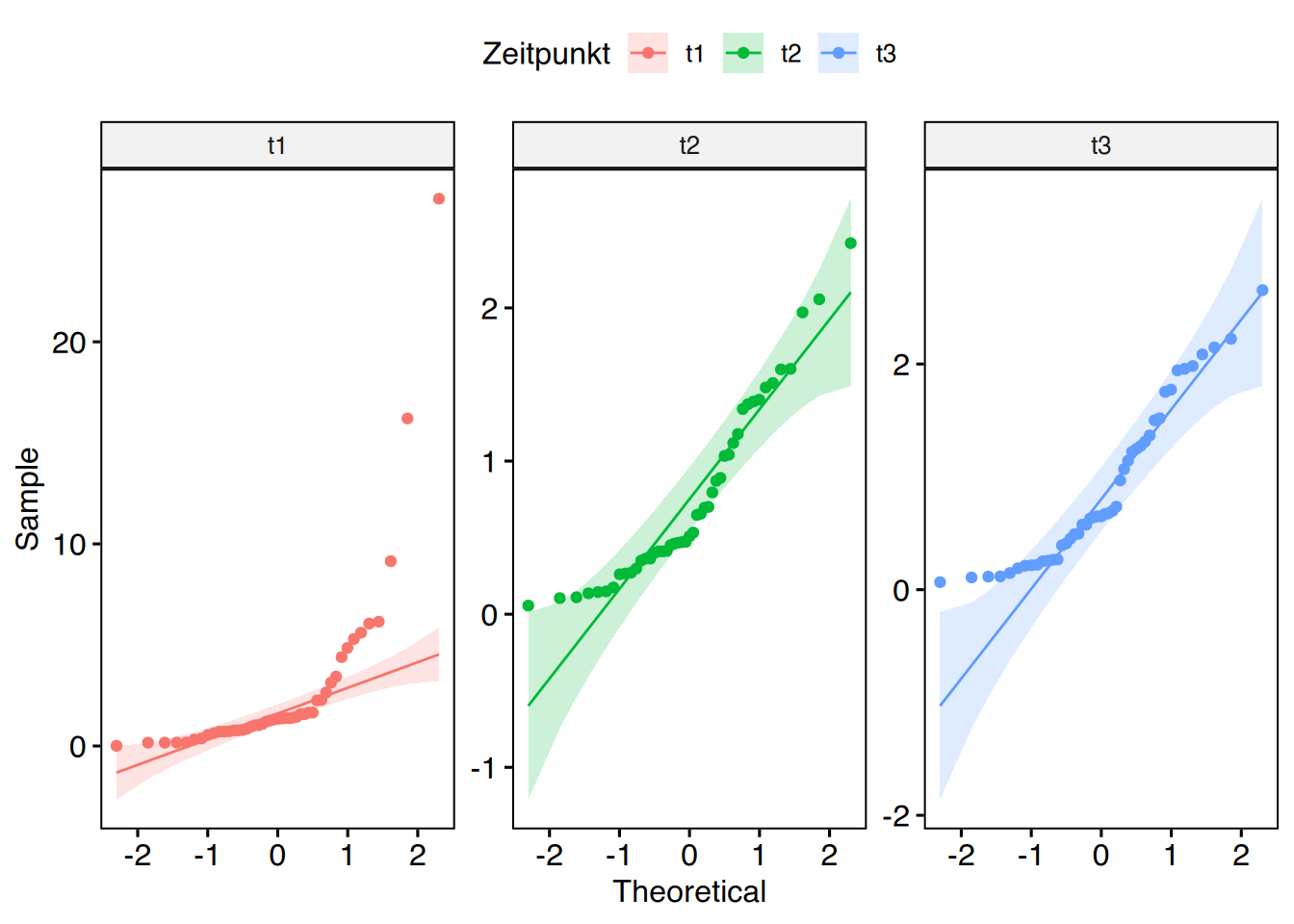
Wir überprüfen mittels Shapiro-Test und QQ-Plot, ob die Daten normalverteilt sind.
## qq-Plot (Normalverteilung)ggpubr::ggqqplot(df, x="Wert", facet.by ="Zeitpunkt", color ="Zeitpunkt",scales ="free")
# Teste "Wert" auf Normalverteilungshapiro.test(df$Wert[df$Zeitpunkt=="t1"])
##
## Shapiro-Wilk normality test
##
## data: df$Wert[df$Zeitpunkt == "t1"]
## W = 0.99364, p-value = 0.5481
shapiro.test(df$Wert[df$Zeitpunkt=="t2"])
##
## Shapiro-Wilk normality test
##
## data: df$Wert[df$Zeitpunkt == "t2"]
## W = 0.98766, p-value = 0.08025
shapiro.test(df$Wert[df$Zeitpunkt=="t3"])
##
## Shapiro-Wilk normality test
##
## data: df$Wert[df$Zeitpunkt == "t3"]
## W = 0.99116, p-value = 0.2625
Die Testergebnisse sind nicht signifikant, also liegt Normalverteilung vor.
Wir dürfen eine ANOVA mit Messwiederholung rechnen. Mit R-Hausmittel könnten wir so vorgehen:
# ANOVA mit Messwiederholung fit <-aov(Wert ~ Zeitpunkt +Error(Name), data=df)summary(fit)
##
## Error: Name
## Df Sum Sq Mean Sq F value Pr(>F)
## Residuals 199 395.8 1.989
##
## Error: Within
## Df Sum Sq Mean Sq F value Pr(>F)
## Zeitpunkt 2 898.0 449.0 212.3 <2e-16 ***
## Residuals 398 841.6 2.1
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Das Ergebnis ist signifikant. Mit der Funktion pairwise.t.test() können wir nun schauen, welche Gruppenunterschiede es konkret gibt:
# geht auch mit R-Hausmitteln so:pairwise.t.test(df$Wert, df$Zeitpunkt, p.adjust="bonferroni")
##
## Pairwise comparisons using t tests with pooled SD
##
## data: df$Wert and df$Zeitpunkt
##
## t1 t2
## t2 < 2e-16 -
## t3 < 2e-16 1.1e-12
##
## P value adjustment method: bonferroni
Die Unterschiede sind zwischen allen Gruppen signifikant.
Das Zusatzpaket rstatix bietet mit der Funktion anova_test() eine alternative Vorgehensweise.
# ANOVA mit Messwiederholung fit <- rstatix::anova_test(data = df, dv = Wert, wid = Name,within = Zeitpunkt, effect.size ="pes")# auf Sphärizität prüfenfit$`Mauchly's Test for Sphericity`
## Effect W p p<.05
## 1 Zeitpunkt 0.668 4.29e-18 *
Mauchly’s Test ist signifikant, das heisst, es liegt keine Sphärizität vor. R hat in diesem Falle bereits die Freiheitsgrade automatisch korrigiert (mittels Greenhouse-Geisser-Verfahren).
Schauen wir uns die ANOVA an:
rstatix::get_anova_table(fit)
## ANOVA Table (type III tests)
##
## Effect DFn DFd F p p<.05 pes
## 1 Zeitpunkt 1.5 298.73 212.34 2.18e-48 * 0.516
Die ANOVA ist signifikant. Jetzt können wir analysieren, welche konkreten Gruppenunterschiede vorliegen.
Achtung, nur solche Werte interpretieren, die oben signifkant waren. In unserem Beispiel sind alle Werte signifikant, darum dürfen wir alle Effekte interpretieren.
33.9.2 Friedman ANOVA
Sind die Werte nicht normalverteilt, kann ein Friedman-ANOVA gerechnet werden. Wir nutzen den Testdatensatz MarioANOVA.rda. Er enthält Informationen über 47 Super Mario Charaktere, deren Fehlerquote beim Spielen eines schweren Levels zu 3 Zeitpunkten erfasst wurde.
Der Effekt von t1 nach t2 ist “groß”, der von t1 nach t3 “moderat”.
33.9.3 einfaktorielle ANOVA
Eine einfaktorielle Varianzanalyse (ANOVA) wird mit der Funktion aov() durchgeführt. Sie wird nach der Syntax x erklärt durch y aufgerufen. Wie bei anderen Modellen ist es ratsam, die Ergebnisse der Berechnung in ein Objekt zu speichern, und dieses per summary() anzuschauen.
## Df Sum Sq Mean Sq F value Pr(>F)
## Standort 4 10557 2639.3 8.48 1.09e-06 ***
## Residuals 725 225633 311.2
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## 1 Beobachtung als fehlend gelöscht
Das Ergebnis ist signifikant, wir haben unterschiedliche Varianzen im Alter erklärt durch Standort.
Wir wissen aber noch nicht, innerhalb welche Standorte die Unterschiede bestehen. Dazu führen wir post hoc Tests durch, in denen alle Gruppen paarweise verglichen werden. Wegen dieses multiplen Testens muss eine Fehlerkorrektur für Alpha durchgeführt werden. Dazu steht die Funktion pairwise.t.test() zur Verfügung, die mit den selben Angaben aufgerufen wird.
pairwise.t.test(pf8$Alter, pf8$Standort)
##
## Pairwise comparisons using t tests with pooled SD
##
## data: pf8$Alter and pf8$Standort
##
## Rheine Münster Bahn Ladbergen
## Münster 0.5042 - - -
## Bahn 0.4354 1.0000 - -
## Ladbergen 0.5432 1.0000 1.0000 -
## Internet 0.0090 1.8e-05 0.0002 0.0059
##
## P value adjustment method: holm
Die gewählte Fehlerkorrektur ist standardmäßig holm. Möchten Sie auf die Bonferroni-Korrekturmethode wechseln, übergeben Sie den Parameter p.adjust="bonferroni".
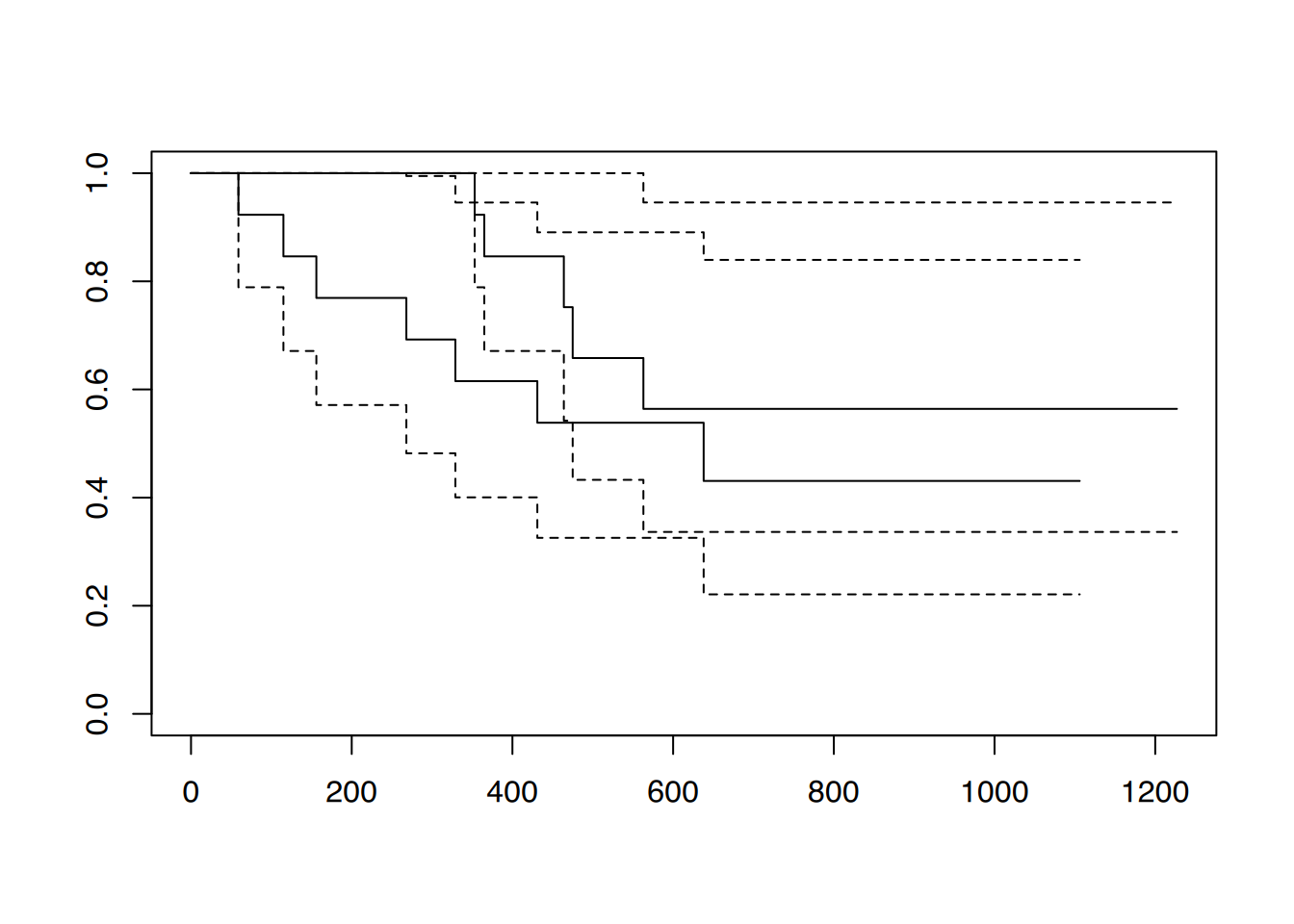
Zur Überlebenszeitanalyse nach dem Kaplan-Meier-Verfahren steht das Zusatzpaket survival zur Verfügung. Zum Ausprobieren der Funktionen liegt dem Paket der Datensatz ovarian bei.
# Beschreibung des Datensatzes lesen?survival::ovarian
# speichere Testdatensatz "ovarian" in Objekt "ov"ov <- survival::ovarianhead(ov)
Bevor wir mit der Analyse beginnen, sollten wir den Datensatz noch aufbereiten. Wir überführen alle kategorialen Variablen in einen factor.
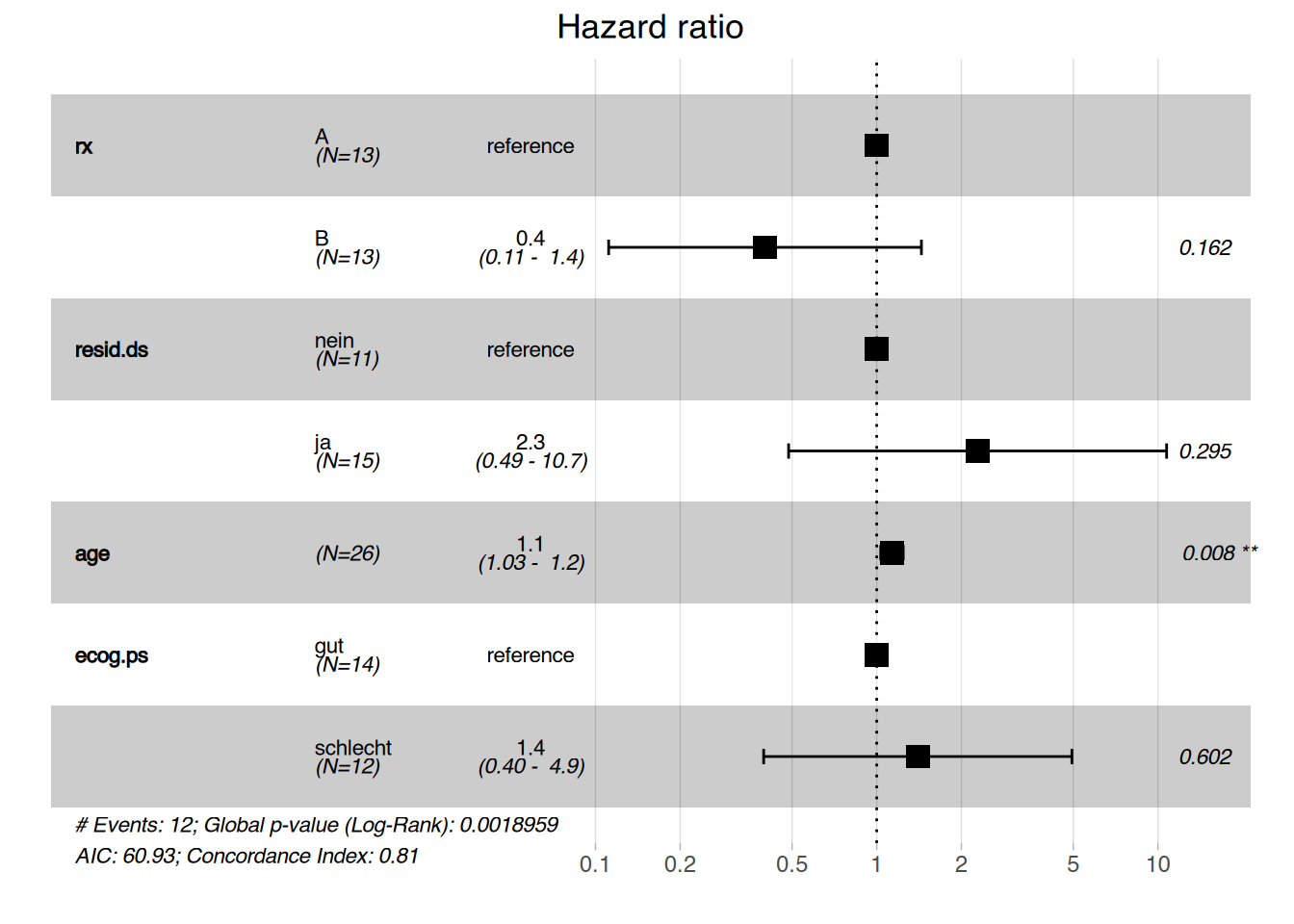
### Datensatz aufbereiten## alle kategorialen Variablen# rx ist die Behandlungsgruppeov$rx <-factor(ov$rx,levels =c("1", "2"),labels =c("A", "B"))# resid.ds sind Nebenerkrankungenov$resid.ds <-factor(ov$resid.ds,levels =c("1", "2"),labels =c("nein", "ja"))# ecog.ps ist der ECOG-Statusov$ecog.ps <-factor(ov$ecog.ps,levels =c("1", "2"),labels =c("gut", "schlecht"))
Als ersten Analyseschritt erzeugen wir mit der Funktion Surv() ein “Survivalobjekt”. Der Funktion muss eine Zeitvariable mit der Beobachtungszeit sowie eine dichotome Statusvariable mit dem Ereignis (0 = nicht eingetreten; 1 = eingetreten) übergeben werden. Im ovarian-Datensatz ist die Zeit in futime und der Status in fustat gespeichert. Der Funktionsaufruf lautet dementsprechend
Die Spalte survival gibt die entsprechenden Überlebenswahrscheinlichkeiten an.
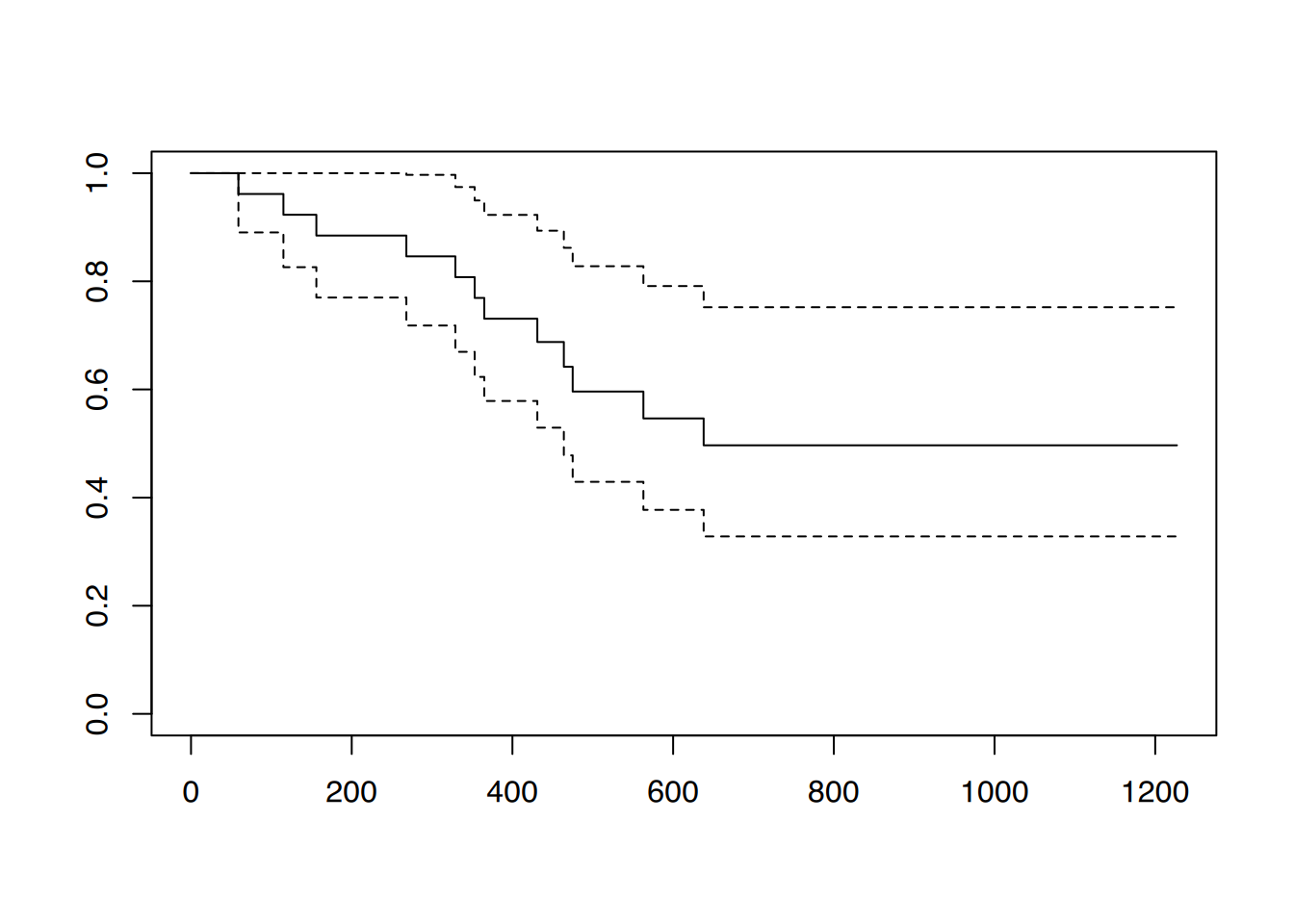
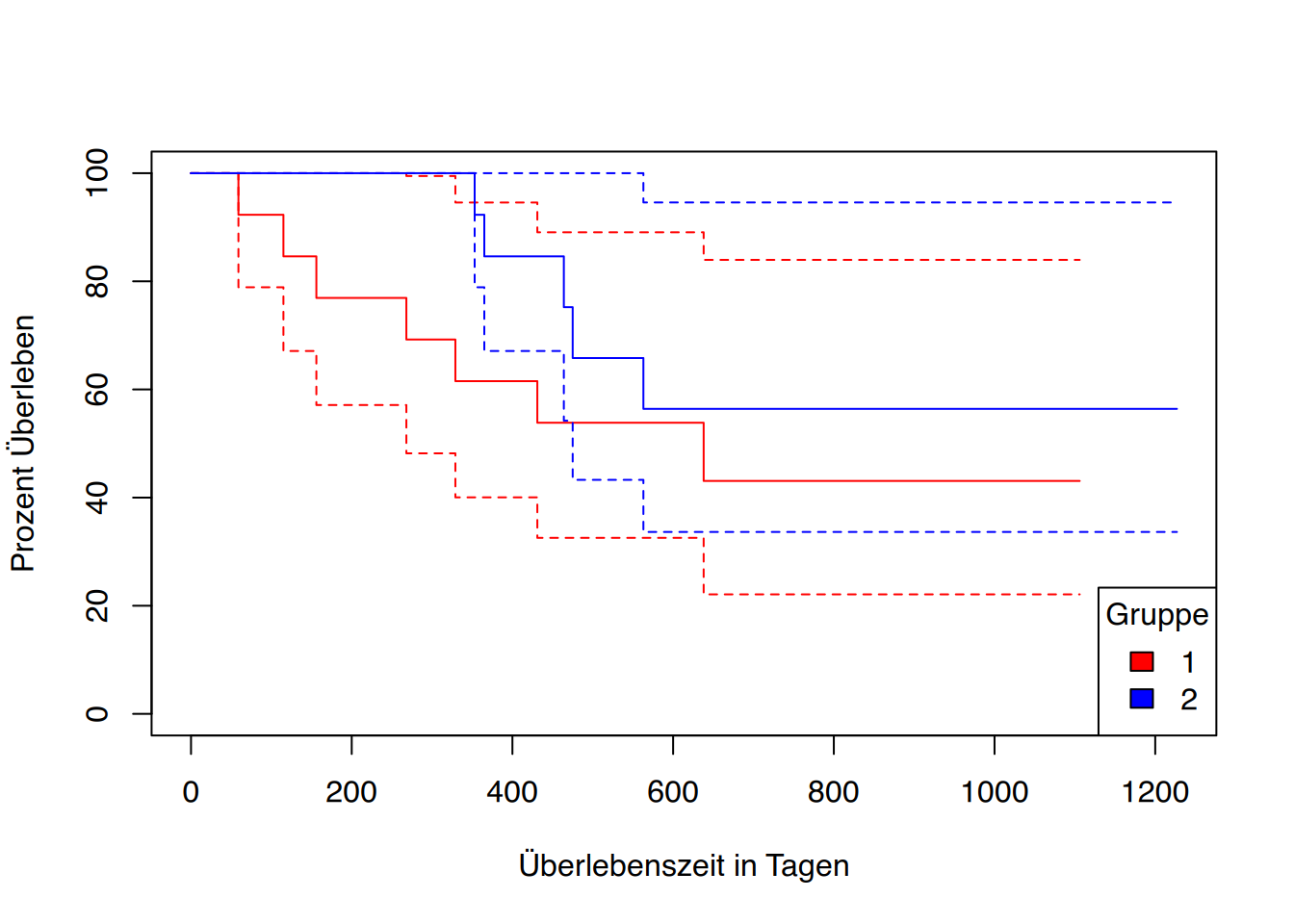
## plot() (sehr hässlich)plot(km_fit)
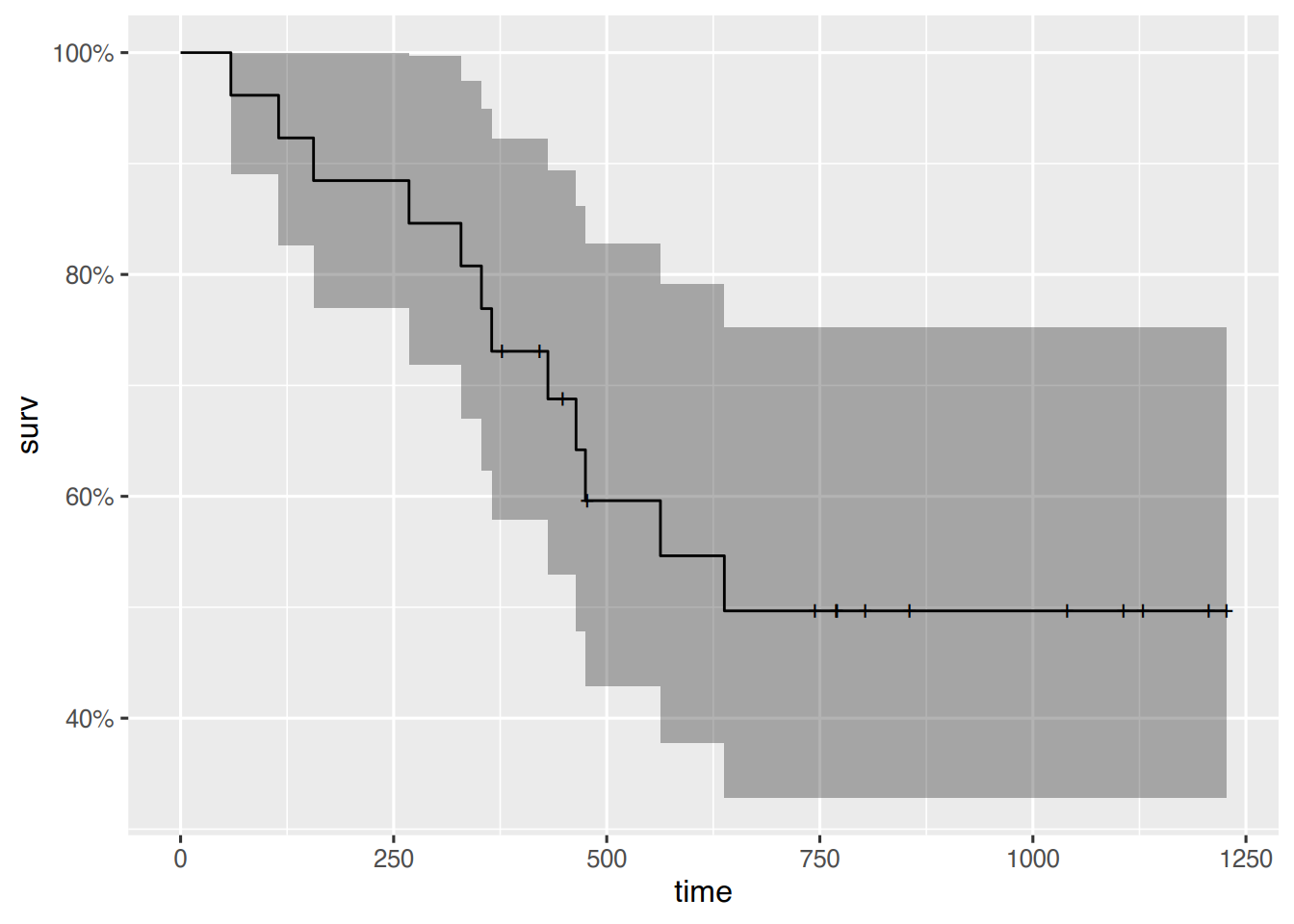
Etwas hübschere Plots lassen sich mit der Funktion autoplot() erzeugen. Damit die Funktion die Modelldaten versteht, muss das Zusatzpaket ggfortify geladen werden.
# etwas hübscherlibrary(ggfortify)autoplot(km_fit)
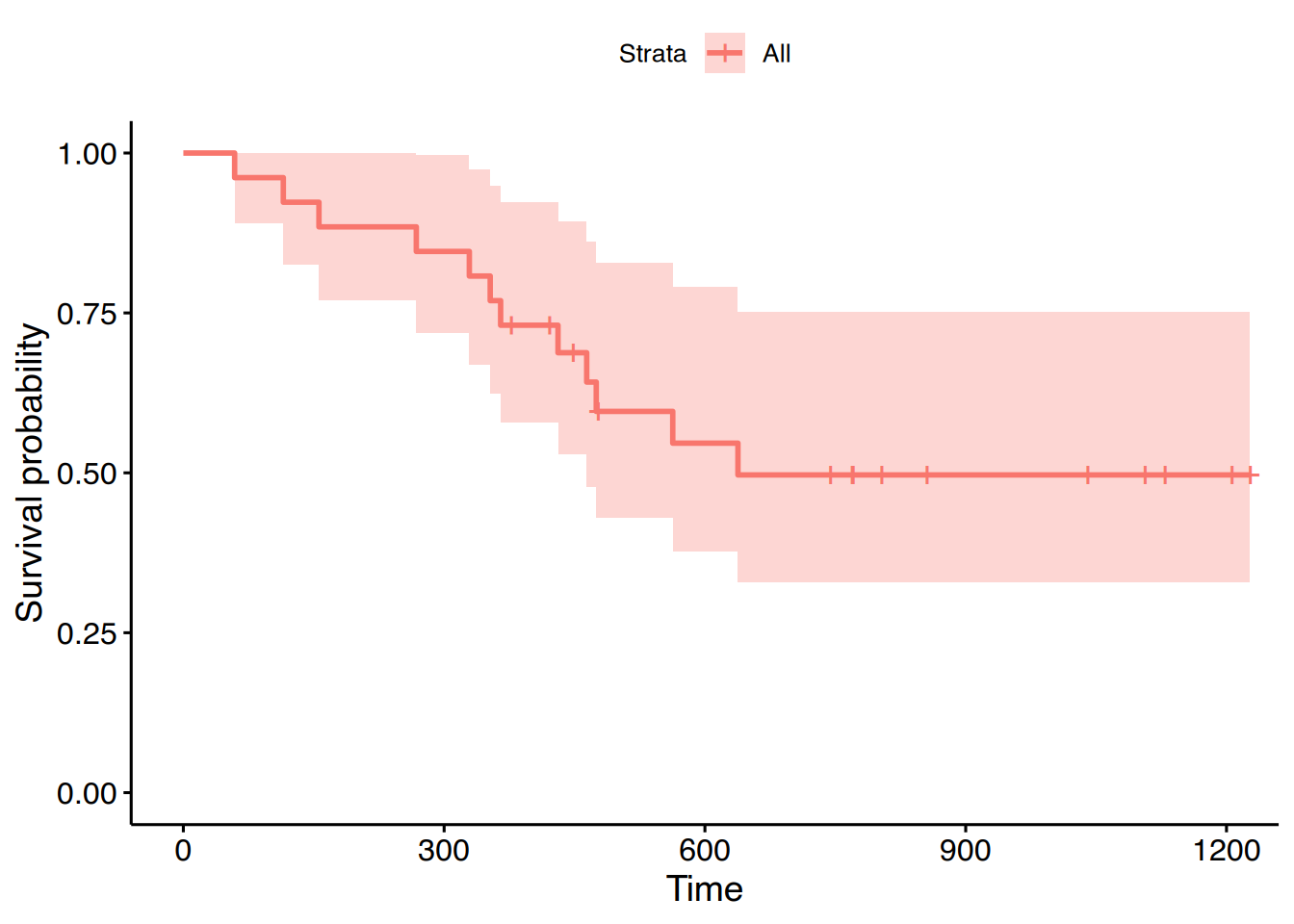
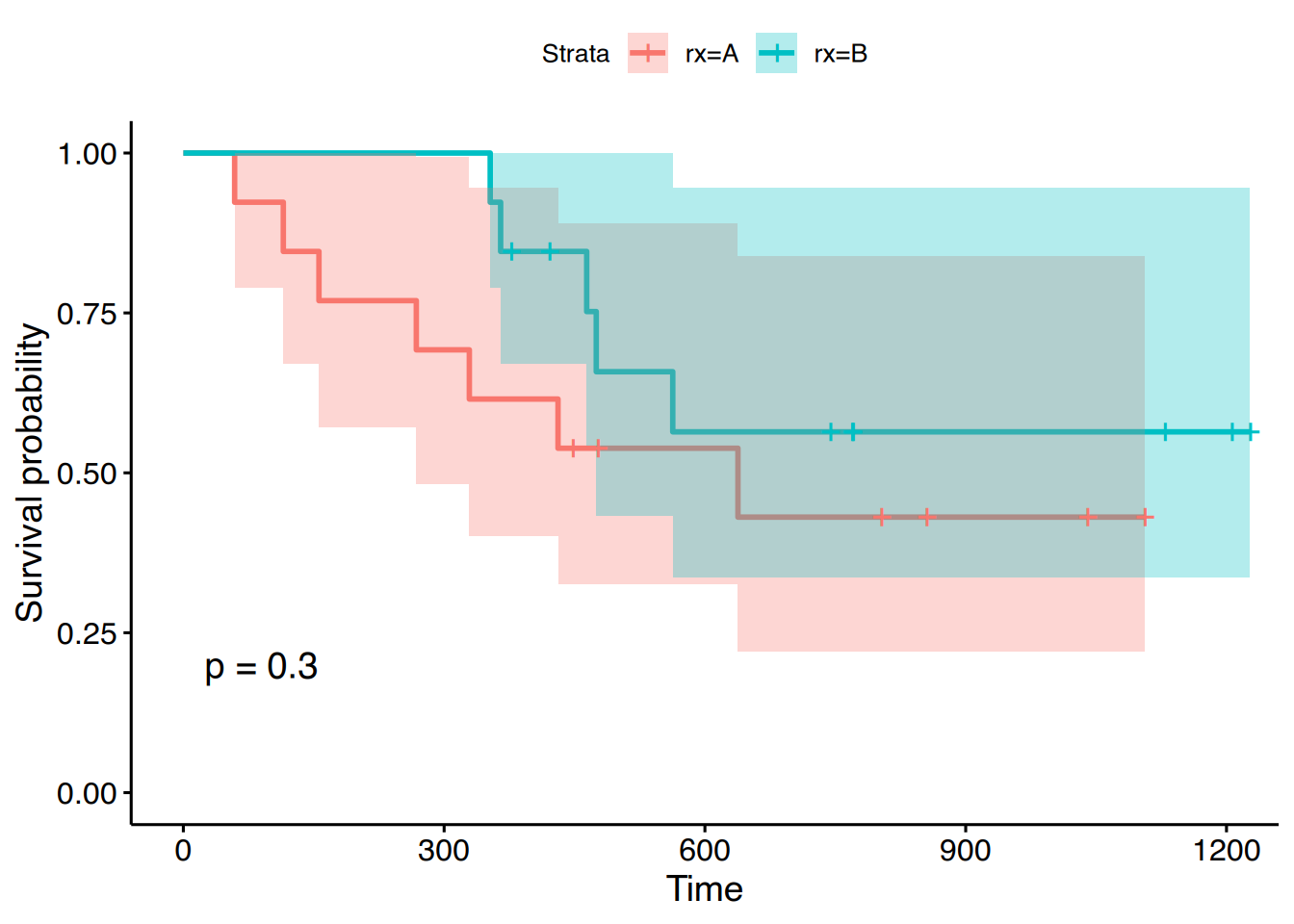
Darüber hinaus bietet das Paket survminer die Funktion ggsurvplot():
Das Modell lässt sich auch für Gruppenvergleiche erstellen. Die Variable ov$rx unterteilt den Datensatz in zwei Behandlungsgruppen. Das Überlebensmodell pro Gruppe lässt sich wie folgt erzeugen:
Neben der Kaplan-Meier-Analyse können die Daten auch per Cox-Regression analysiert werden. Der Vorteil besteht darin, dass Prädiktoren verschiedensten Datenniveaus in die Analyse integriert werden können. Das Paket survival bietet hierzu die Funktion coxph().
## Cox-Regressioncox <- survival::coxph(survObjekt ~ rx+resid.ds+age+ecog.ps, data=ov)# Modell ausgebencox
## Call:
## survival::coxph(formula = survObjekt ~ rx + resid.ds + age +
## ecog.ps, data = ov)
##
## coef exp(coef) se(coef) z p
## rxB -0.91450 0.40072 0.65332 -1.400 0.16158
## resid.dsja 0.82619 2.28459 0.78961 1.046 0.29541
## age 0.12481 1.13294 0.04689 2.662 0.00777
## ecog.psschlecht 0.33621 1.39964 0.64392 0.522 0.60158
##
## Likelihood ratio test=17.04 on 4 df, p=0.001896
## n= 26, number of events= 12
Die Spalte exp(coef) entspricht der Hazard-Ratio, mit welcher Richtung und Stärke des jeweiligen Einflusses interpretiert werden kann.
Das Modell kann mittels ggforest() geplottet werden:
# Forestplot der Hazard-Ratiosurvminer::ggforest(cox, data=ov)
33.11 Faktorenanalyse
Die beiden am Häufigsten genutzen Verfahren sind die Hauptkomponentenanalyse (PCA) und die Hauptachsenanalyse (PAF). Sie unterscheiden sich in den Varianzanteilen, die in den Items enthalten sein können. Die PCA versucht, die gesamte Varianz auf Faktoren zurückzuführen, die PAF die gemeinsame Varianz der Items. In psychologischen Anwendungen (= am Menschen) wird daher eher die PAF verwendet.
33.11.1 explorative Faktorenanalyse
Bei der explorativen Faktorenanalyse (EFA) erfolgt die Auswertung (häufig) nicht theoriegeleitet. Ziel ist es vielmehr zu erfahren, mit wievielen Faktoren die Daten bestmöglich erklärt werden können.
Wir verwenden den Datensatz Faktorenbogen, der wie folgt geladen werden kann.
## vars n mean sd median trimmed mad min max range skew kurtosis
## age 1 150 53.11 18.82 53.0 54.16 17.05 1 101 100 -0.47 0.29
## gender* 2 150 1.65 0.55 2.0 1.64 0.00 1 3 2 0.02 -0.87
## A 3 150 4.41 2.03 5.0 4.40 2.97 0 10 10 0.05 -0.43
## B 4 150 1.92 0.84 2.0 1.84 1.48 1 5 4 0.76 0.43
## C 5 150 7.91 6.19 7.0 7.22 5.93 0 30 30 1.12 1.31
## D 6 150 12.23 5.05 12.0 11.95 4.45 3 27 24 0.51 -0.04
## E 7 150 14.77 2.39 15.0 14.69 2.97 10 21 11 0.28 -0.13
## F 8 150 5.00 1.32 5.0 5.03 1.48 2 8 6 -0.12 -0.67
## G 9 150 10.35 4.08 9.5 10.06 3.71 3 24 21 0.78 0.76
## H 10 150 15.92 2.93 16.0 15.84 2.97 10 24 14 0.21 -0.39
## I 11 150 85.02 68.19 65.0 75.93 51.15 0 356 356 1.40 2.05
## J 12 150 5.02 2.25 5.0 4.93 1.48 1 11 10 0.33 -0.12
## K 13 150 5.44 2.08 6.0 5.38 2.97 1 12 11 0.31 -0.10
## L 14 150 1.47 0.65 1.0 1.36 0.00 1 4 3 1.20 0.86
## se
## age 1.54
## gender* 0.04
## A 0.17
## B 0.07
## C 0.51
## D 0.41
## E 0.20
## F 0.11
## G 0.33
## H 0.24
## I 5.57
## J 0.18
## K 0.17
## L 0.05
Die Items für die Faktorenanalyse befinden sich in den Variablen A bis L.
items <- Faktorenbogen %>%select(A:L)
Mit dem Bartlett-Test kann überprüft werden, ob die Items miteinander korrelieren (das sollten sie tun).
psych::cortest.bartlett(items)$p.value
## R was not square, finding R from data
## [1] 8.843226e-151
Das Ergebnis ist signifikant.
Mittels Kaiser-Meyer-Olkin-Verfahren (KMO) wird geprüft, wie gut die Daten für eine Faktorenanalyse geeignet sind, wobei Werte zwischen 0 (für “nicht geeignet”) und 1 (für “perfekt geeignet”) angenommen werden. Die Minimum Average Partial (MSA) ist ein Maß der internen Konsistenz, und nimmt ebenfalls Werte zwischen 0 (nicht konsistent) und 1 (perfekt konsistent) an. Beide Werte sollte größer als 0,5 sein.
# berechne KMO und MSApsych::KMO(items)
## Kaiser-Meyer-Olkin factor adequacy
## Call: psych::KMO(r = items)
## Overall MSA = 0.69
## MSA for each item =
## A B C D E F G H I J K L
## 0.36 0.72 0.66 0.68 0.60 0.73 0.24 0.73 0.75 0.62 0.78 0.61
Die “Overall MSA” entspricht dem KMO.
Mittels Screeplot kann die Faktorenzahl graphisch entschieden werden. Dabei sollte der letzte “gültige” Faktor vor dem deutlichen Knick zu einer abflachenden Gerade genutzt werden. Darüber hinaus sollten die Eigenwerte der Faktoren größer 1 sein.
Mit R-Hausmitteln kann ein Screeplot wie folgt erzeugt werden.
## Parallel analysis suggests that the number of factors = 3 and the number of components = 3
Es werden 3 Faktoren/Komponenten vorgeschlagen.
Die Funktion berechnet das Screeplot sowohl für PAC (Sternchen) als auch PAF (Dreieck). Mit dem Parameter fa = "fa" kann die PAC-Methode entfernt werden.
psych::fa.parallel(items, fa ="fa")
## Parallel analysis suggests that the number of factors = 3 and the number of components = NA
Die Daten lassen sich am besten mit 3 Faktoren erklären.
33.11.2 konfirmatorische Faktorenanalyse
Ist die Anzahl der Faktoren bekannt (z.B. theoriegeleitet), wird die Hauptachsenanaylse wie folgt durchgeführt.
## Factor Analysis using method = minres
## Call: psych::fa(r = items, nfactors = 3, rotate = "varimax")
## Standardized loadings (pattern matrix) based upon correlation matrix
## MR1 MR2 MR3 h2 u2 com
## A 0.00 0.08 0.03 0.0069 0.993 1.2
## B -0.01 0.83 -0.08 0.6997 0.300 1.0
## C -0.05 0.88 -0.01 0.7770 0.223 1.0
## D 0.96 -0.09 -0.07 0.9266 0.073 1.0
## E -0.02 0.10 0.88 0.7820 0.218 1.0
## F -0.04 -0.12 0.59 0.3655 0.635 1.1
## G 0.00 0.00 0.07 0.0048 0.995 1.0
## H 0.94 -0.02 -0.08 0.8855 0.115 1.0
## I -0.03 0.78 -0.05 0.6107 0.389 1.0
## J -0.08 0.08 0.88 0.7866 0.213 1.0
## K 0.89 0.03 -0.01 0.7896 0.210 1.0
## L -0.10 0.09 0.14 0.0393 0.961 2.6
##
## MR1 MR2 MR3
## SS loadings 2.61 2.13 1.94
## Proportion Var 0.22 0.18 0.16
## Cumulative Var 0.22 0.39 0.56
## Proportion Explained 0.39 0.32 0.29
## Cumulative Proportion 0.39 0.71 1.00
##
## Mean item complexity = 1.2
## Test of the hypothesis that 3 factors are sufficient.
##
## df null model = 66 with the objective function = 6.38 with Chi Square = 920.48
## df of the model are 33 and the objective function was 0.32
##
## The root mean square of the residuals (RMSR) is 0.03
## The df corrected root mean square of the residuals is 0.05
##
## The harmonic n.obs is 150 with the empirical chi square 20.2 with prob < 0.96
## The total n.obs was 150 with Likelihood Chi Square = 45.01 with prob < 0.079
##
## Tucker Lewis Index of factoring reliability = 0.971
## RMSEA index = 0.049 and the 90 % confidence intervals are 0 0.083
## BIC = -120.34
## Fit based upon off diagonal values = 0.99
## Measures of factor score adequacy
## MR1 MR2 MR3
## Correlation of (regression) scores with factors 0.98 0.94 0.94
## Multiple R square of scores with factors 0.96 0.88 0.88
## Minimum correlation of possible factor scores 0.92 0.76 0.77
Die Ausgabe von fit ist ziemlich lang. Wie gewohnt besteht die Möglichkeit, mittels $ auf die einzelnen Ergebnisse zuzugreifen. Eine Übersicht erhält man mittels names().
## A B C D E F
## 0.006940720 0.699704328 0.776989353 0.926609287 0.782014553 0.365479522
## G H I J K L
## 0.004811051 0.885466837 0.610670890 0.786557566 0.789638724 0.039273937
fit$loadings
##
## Loadings:
## MR1 MR2 MR3
## A
## B 0.833
## C 0.880
## D 0.956
## E 0.103 0.878
## F -0.118 0.592
## G
## H 0.938
## I 0.779
## J 0.879
## K 0.888
## L -0.104 0.141
##
## MR1 MR2 MR3
## SS loadings 2.605 2.129 1.940
## Proportion Var 0.217 0.177 0.162
## Cumulative Var 0.217 0.394 0.556
Mit diesen Informationen können die Items ein bisschen umsortiert…
##
## Loadings:
## RC1 RC2 RC3
## A 0.128
## B 0.887
## C 0.905
## D 0.958
## E 0.102 0.890
## F -0.146 0.764
## G 0.121
## H 0.954
## I 0.865
## J 0.890
## K 0.940
## L -0.135 0.143 0.238
##
## RC1 RC2 RC3
## SS loadings 2.744 2.435 2.260
## Proportion Var 0.229 0.203 0.188
## Cumulative Var 0.229 0.432 0.620
Zur Fallzahlkalkulation bei klinischen Studien (z.B. RCTs) kann das Zusatzpaket pwr installiert werden. Mit der Funktion pwr.t.test() können alle Werte berechnet werden. Ihr müssen die entsprechenden Werte für das Signifikanzlevel, Power und Cohen’s d (Effektstärke) übergeben werden.
# erechne Fallzahl mit# Cohens d = 0.1# alpha = 0.05# Power = 0.8pwr::pwr.t.test(d=0.1, sig.level=0.05, power=0.8, type="two.sample", alternative="two.sided")
##
## Two-sample t test power calculation
##
## n = 1570.733
## d = 0.1
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* group
Über die Parameter type und alternative lassen sich die Testbedingungen festlegen.
Möchten Sie nicht immer die gesamte Testausgabe angezeigt bekommen, sondern nur den Wert für n, können Sie dies mit einem Dollarzeichen $ hinter dem Funktionsaufruf spezifizieren.
# zeige nur "n"pwr.t.test(d=0.1, sig.level=0.05, power=0.8, type="two.sample")$n
## [1] 1570.733
# runde auf nächste ganze Zahlceiling(pwr.t.test(d=0.1, sig.level=0.05, power=0.8, type="two.sample")$n)
## [1] 1571
Sie benötigen 1571 Probanden pro Untersuchungsgruppe.
33.12.2 Umfragen
Soll eine Befragung (ein Survey) durchgeführt werden, kann die benötigte Fallzahl über das Zusatzpaket samplingbook errechnet werden.
Geht es um numerische Werte, wird die Funktion sample.size.mean() verwendet. Ihr übergibt man Fehlerspanne e (ein Präzisionswert, der besagt, wie breit das Konfidenzintervall - nach oben sowie nach unten - sein darf, für gewöhnlich 5% bzw. 0.05), das Konfidenzniveau, die Standardabweichung S innerhalb der Grundgesamtheit (füre gewöhnlich 50% bzw. 0.5) sowie die Populationsgröße. Standardmäßig ist die Populationsgröße auf N=Inf (für unendlich) gesetzt.
# Berechne Fallzahl für einen Survey# Konfidenzniveau auf 95%, Fehlerbereich 5%.# In der Grundgesamtheit hat der Wert eine# Standardabweichung von S=0.5samplingbook::sample.size.mean(e=0.05, S=0.5, level=0.95 )
##
## sample.size.mean object: Sample size for mean estimate
## Without finite population correction: N=Inf, precision e=0.05 and standard deviation S=0.5
##
## Sample size needed: 385
Ist die Grundgesamtheit bekannt, kann dies mit N angegeben werden.
# Die Grundgesamtheit ist 1.500 Personen großsamplingbook::sample.size.mean(e=0.05, S=0.5, level=0.95, N=1500 )
##
## sample.size.mean object: Sample size for mean estimate
## With finite population correction: N=1500, precision e=0.05 and standard deviation S=0.5
##
## Sample size needed: 306
Sollen Prozentwerte kategorialer Variablen erfragt werden (z.B. der Anteil weiblicher Pflegepersonen), wird die Funktion sample.size.prop() verwendet. Ihr werden ebenso e, N und level (Konfidenzniveau) übergeben. Statt der Standardabweichung wird über den Parameter P die prozentuale Verteilung in der Grundgesamtheit angegeben.
# Berechne Fallzahl für einen Survey# unsere Werte düren maximal 5% abweichen# Konfidenzniveau auf 95%# In der Grundgesamtheit hat der Wert eine# Verteilung von 65%# Die Grundgesamtheit ist 1.500 Personen großsamplingbook::sample.size.prop(e=0.05, P=0.65, level=0.95, N=1500)
##
## sample.size.prop object: Sample size for proportion estimate
## With finite population correction: N=1500, precision e=0.05 and expected proportion P=0.65
##
## Sample size needed: 284
33.12.2.1 Tabellen
Um ein Gefühl für die benötigten Stichprobengrößen zu erhalten, können wir Tabellen erzeugen, in denen die benötigten Fallzahlen beispielsweise in Abhängigkeit zur Populationsgröße angezeigt werden. Die Tabelle soll Werte für metrische und kategoriale Items anzeigen, wobei wir jeweils das 90%-, 95% und 99%-Konfidenzintervall einsehen wollen. In diesem Beispiel gehen wir für metrische Daten von 30% Streuung aus (S=0.3) und setzen die Fehlerspanne e auf 5%. Für kategoriale Items nehmen wir eine Verteilung von 50% an (P=0.5).
Mit der Funktion sapply() können wir sample.size.mean() und sample.size.prop() auf jeden Wert des Vectors Population anwenden. Die Ergebnisse schreiben wir als neue Variable in unser Datenframes df.
## Wende sample.size.mean() auf jeden Wert in "Population" an# 90%-Konfidenzintervalldf$ConA10 <-sapply(Population, FUN=function(x) samplingbook::sample.size.mean(e=0.05, S=0.3, level=0.90, N=x)$n)# 95%-Konfidenzintervalldf$ConA05 <-sapply(Population, FUN=function(x) samplingbook::sample.size.mean(e=0.05, S=0.3, level=0.95, N=x)$n)# 99%-Konfidenzintervalldf$ConA01 <-sapply(Population, FUN=function(x) samplingbook::sample.size.mean(e=0.05, S=0.3, level=0.99, N=x)$n)## Wende sample.size.prop() auf jeden Wert in "Population" an# 90%-Konfidenzintervalldf$CatA10 <-sapply(Population, FUN=function(x) samplingbook::sample.size.prop(e=0.05, P=0.5, level=0.9, N=x)$n)# 95%-Konfidenzintervalldf$CatA05 <-sapply(Population, FUN=function(x) samplingbook::sample.size.prop(e=0.05, P=0.5, level=0.95, N=x)$n)# 99%-Konfidenzintervalldf$CatA01 <-sapply(Population, FUN=function(x) samplingbook::sample.size.prop(e=0.05, P=0.5, level=0.99, N=x)$n)
Die Variablennamen ConA10 - CatA01 sind etwas kryptisch und für eine “schöne” Tabelle eher ungeeignet. Daher ändern wir die Variablennamen mittels colnames() in leserliche Spaltennamen um. Zuvor speichern wir aber unser Datenframe in ein neues Objekt df2, denn mit den veränderten Variablennamen können wir später viel schlechter weiterarbeiten.
# Mache Sicherungskopie von dfdf2 <- df# ändere die Variablennamen für eine "schöne" TabelleKopfzeile <-c("Population N", "metrisch 90%", "metrisch 95%", "metrisch 99%","kategor 90%", "kategor 95%", "kategor 99%")colnames(df) <- Kopfzeile
Mit den neuen Variablennamen sieht die Tabelle nun so aus:
Population N
metrisch 90%
metrisch 95%
metrisch 99%
kategor 90%
kategor 95%
kategor 99%
100
50
59
71
74
80
87
200
66
82
109
115
132
154
300
74
95
133
143
169
207
400
79
103
150
162
196
250
500
82
109
162
176
218
286
600
84
113
171
187
235
316
700
86
116
179
196
249
341
800
87
118
184
203
260
363
900
88
120
189
209
270
382
1000
89
122
193
213
278
399
1500
92
127
207
230
306
461
2000
93
130
214
239
323
499
4000
96
134
226
254
351
570
6000
96
136
230
259
362
598
8000
97
136
232
262
367
613
10000
97
137
234
264
370
623
Inf
98
139
239
271
385
664
Und um auf das nächste Kapitel vorzugreifen, können wir die Daten der Tabelle in einem einfachen Plot graphisch darstellen.
große Schlarmann, J. (2025a). Grundlagen der Statistik. Einführung in die deskriptive und inferentielle Statistik. Hochschule Niederrhein. https://www.produnis.de/manual
große Schlarmann, J. (2025c). trainingslageR. Ein Übungsbuch für R-Einsteiger*innen und Fortgeschrittene. Hochschule Niederrhein. https://www.produnis.de/trainingslager
große Schlarmann, J., & Galatsch, M. (2014). Regressionsmodelle für ordinale Zielvariablen. GMS Medizinische Informatik, Biometrie und Epidemiologie, 10(1), 1–9. https://doi.org/10.3205/mibe000154