.qmd
quarto render DATEI
systemd
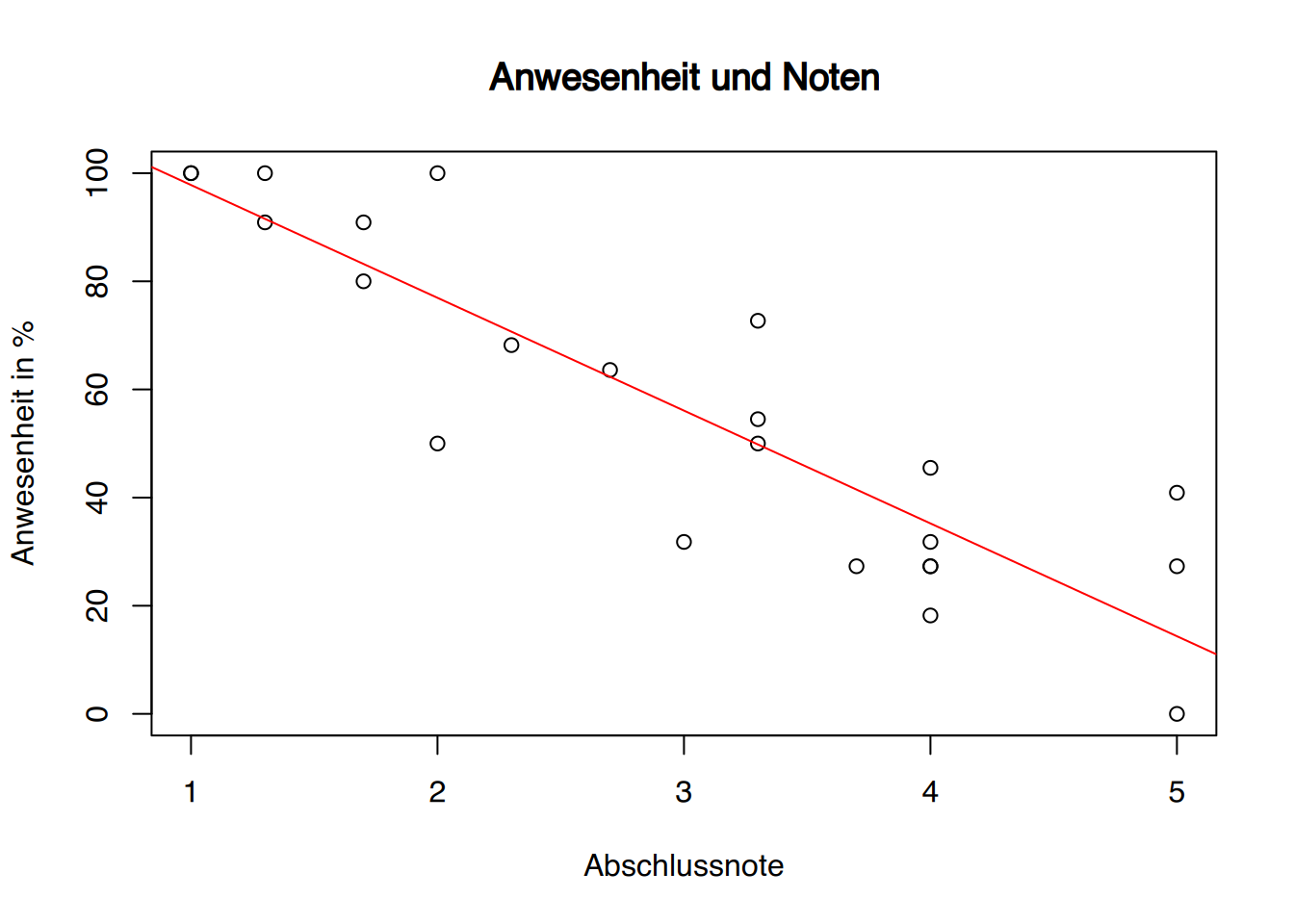
R
ggplot
RMarkdown
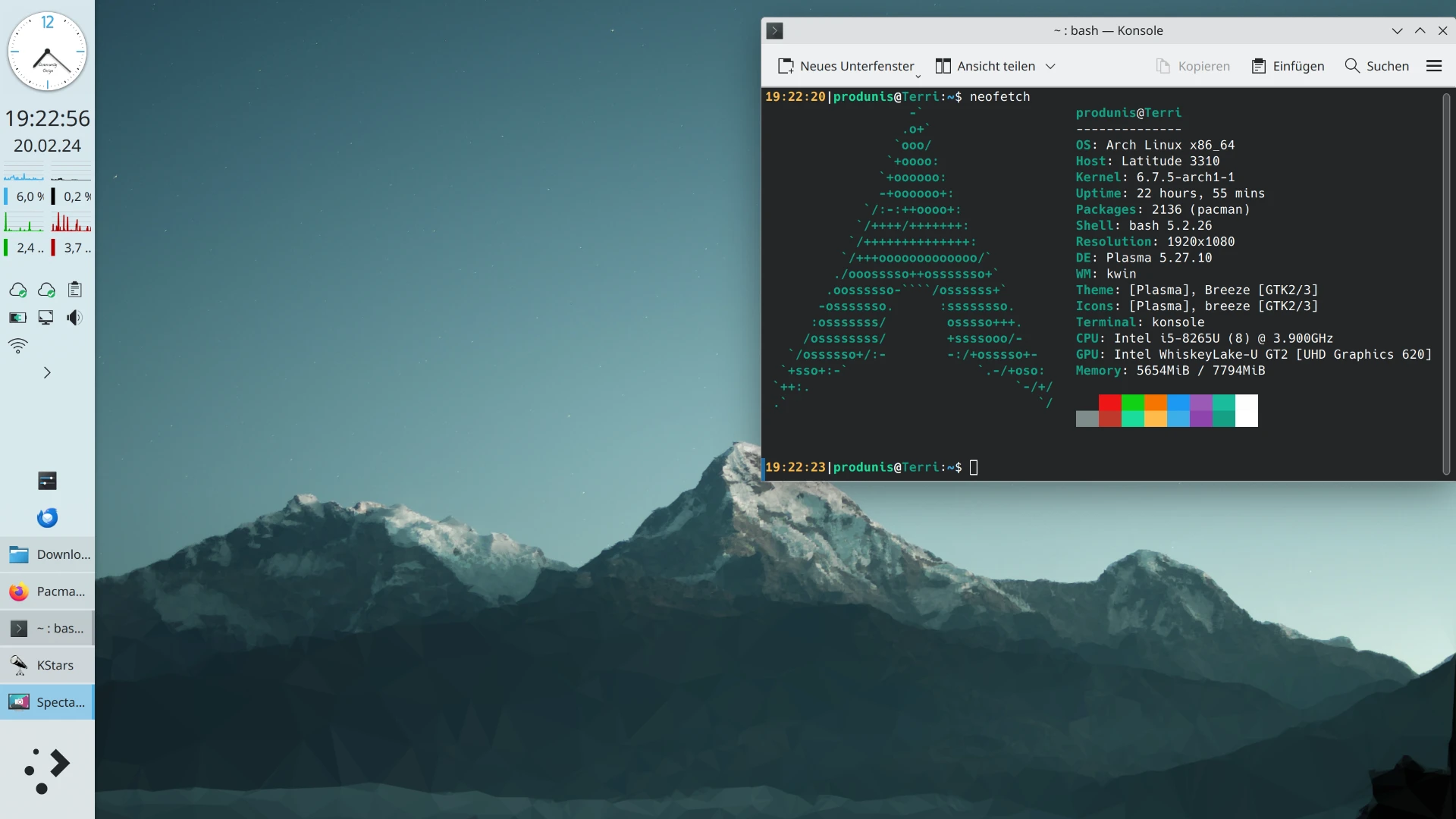
RStudio
LaTeX
Prop…
top
crontab
nano
.bashrc
mp3val
ssh
Sendung mit der Maus
rsync
rar
briss
fslint
Mendeley citation style
Lasmex S-01
QNAP TS-219P
nfs
need PK compat. v5.1 (can do v4.6)
deborphan
Audex
mpd
lame
vbrfix
unrar
Wordpress.com Stats
DeviceKit.Power
UPower
winmail.dat
bb
No Valid Source Found
extremaudio.de
NO_PUBKEY
syncevolution
funambol
icecast2
ices2
gnome-power-cmd
dbus-send
SUSPEND
ifupdown (eth0)
Asus O!Play HDP-R1
.img
.iso
moodle
/bin/bash: bad interpreter: Permission denied
HandbrakeCLI
avidemux2_cli
mencoder
low-graphics mode
LONGSHINE lcs-wa5-45
PhotoRec
TestDisk