Dieser Beitrag ist schon sehr alt, und die Infos hier sind sicherlich hoffnungslos veraltet…
The Personal Analytics of My Life: Meine Termine
In diesem Post habe ich gestern beschrieben, wie ich meinen Mailverkehr auslese und mit R plotte. Das Ganze hat keinerlei tieferen Sinn, sondern ist inspiriert von Stephen Wolframs Blogbeitrag The Personal Analytics of My Life. Heute geht es um meine Termindaten, die in verschiedenen Kalendern vorliegen. Diese Kalender haben das iCal-Formmat und daher die Endung *.ics.
Python-Script
Wieder verwende ich ein Python-Script, um meine Kalenderdateien auszulesen. Das Script liegt übrigens in diesem Gist bereit, und sieht so aus:
#!/usr/bin/python
# terminscanner.py Version 1
#------------------------------------------------------------------------------------------
#----- Inspired by Wolfram's "Analytics of My Life", we try it ourself
#----- http://blog.stephenwolfram.com/2012/03/the-personal-analytics-of-my-life/
#------------------------------------------------------------------------------------------
# call this script like this:
# /path/to/terminscanner.py CALENDAR APPENDIX
# where CALENDAR is the path to your ics-file,
# /foo/bar/calendar.ics
# and where APPENDIX is the appendix of the outputfile to be created by this script
# (and which will contain DATE and TIME for each calendar-entry in a texttable)
#--------------------------------------------------------------------------------------
# IMPORTS #
import os,re
import sys
import time
kalendername = sys.argv[1] # e.g.("/foo/bar/calendar.ics")
myfilename = sys.argv[2] # Filename-Appendix, e.g "Office"
# modify to your needs
ZIEL = ("MyCalendar-%s.txt") % (myfilename) # add apendix
### nothing to edit from here on, leave it alone ...
### My Functions and Routines
#-- BashReturn benoetigt: os ---------------------------------------
def BashReturn(cmd):
output = "a" # is a dummy, will be deleted afterwards
f=os.popen(cmd)
for i in f.readlines():
output = output + i
output = output[1:] # kill the dummy-a
return output
#-------------------------------------------------------------------
#==============End of Functions ========================================
SCHREIB = open(ZIEL,"w")
cmd = 'less %s|grep DTSTART' % (kalendername)
bla = BashReturn(cmd)
for line in bla.split('\n'):
if len(line)!=0: # check if line is an entry
if line[len(line)-8]=="T": # check if it has TIME
s = len(line)-7 # TIME
z = len(line)-1 # TIME
x = len(line)-16 # DATE
y = len(line)-8 # DATE
termintime = line[s:z]
termindate = line[x:y]
#print termindate
#print termintime
else: # it has DATE only
termintime = "000000"
x = len(line)-9 # DATE
y = len(line)-1 # DATE
termindate = line[x:y]
else: # is no real entry
termintime = "NA"
termindate = "NA"
SCHREIB.write(str("%s,%s\n") % (termindate, termintime))
SCHREIB.close()
## END OF FILE(Für alle, die ihre Kalender einer OwnCloud mit MySQL anvertraut haben, steht dieses Script als Alternative zur Verfügung)
Ich bin Code-Autodidakt und habe alle McGyver-Folgen gesehen. Daher ist der Code sicherlich irgendwie zusammengeschustert. Beispielsweise werden mit diesem Script wiederkehrende Termine ignoriert. Any help is welcome :)
Das Script durchforstet die Kalenderdatei, und schreibt für jeden Eintrag das Datum als YYYYMMDD und die Uhrzeit als HHMMSS in eine Texttabelle. Diese Texttabelle kann R dann einlesen…
Ich speichere dieses Script mit dem Namen “terminscanner.py” an einen beliebigen Ort und mache es ausführbar.
Daten auslesen
Jetzt muss man noch wissen, wo genau die auszulesenden ics-Dateien liegen. Dann kann das Script wie folgt aufgerufen werden:
/pfad/zu/terminscanner.py /PFAD/ZU/CALENDER.ics APPENDIXDie Pfade zum Script und zur Kalenderdatei müsst ihr entsprechend anpassen. Als APPENDIX wählt ihr einen Filenamezusatz, den die Texttabelle (die von dem Script generiert wird) haben soll. Bei mir sieht das so aus:
~/scripts/terminscanner.py ~/Calendars/produnis.ics ProdunisDies erzeugt mit im selben Verzeichnis die Datei MyCalendar-Produnis.txt, welche die Termindaten für R enthält. Der Vorgang kann nun für alle verfügbaren Kalender wiederholt werden.
R
Hat man die Texttabellen vorliegen, kann man sie wie folgt in R einlesen:
R
mycalendar <- read.table("/Path/to/MyCalendar-foobar.txt", sep=",", colClasses = "character") # Read table as charactersMit etwas R-Kung-Fu (eigentlich das selbe wie bei den Mails), kann man nun die Daten aufpolieren und plotten.
colnames(mycalendar) <- c("Datum","Uhrzeit") # give names to colums
mycalendar$Datum <- strptime(inbox$Datum,format="%Y%m%d") # turn into format DATE
mycalendar$Uhrzeit <- strptime(inbox$Uhrzeit, format="%H%M%S") # turn into format TIME
plot(mycalendar$Datum, mycalendar$Uhrzeit) # plot the stuffHier mal ein Beispiel mit meinen Daten:
privat <- read.table("http://www.produnis.de/R/CALENDAR1.txt", sep=",", colClasses = "character") # Read table as characters
colnames(privat) <- c("Datum","Uhrzeit") # give names to colums
privat$Datum <- strptime(privat$Datum,format="%Y%m%d") # turn into format DATE
privat$Uhrzeit <- strptime(privat$Uhrzeit, format="%H%M%S") # turn into format TIME
#
lecture <- read.table("http://www.produnis.de/R/CALENDAR2.txt", sep=",", colClasses = "character") # Read table as characters
colnames(lecture) <- c("Datum","Uhrzeit") # give names to colums
lecture$Datum <- strptime(lecture$Datum,format="%Y%m%d") # turn into format DATE
lecture$Uhrzeit <- strptime(lecture$Uhrzeit, format="%H%M%S") # turn into format TIME
#
uni <- read.table("http://www.produnis.de/R/CALENDAR3.txt", sep=",", colClasses = "character") # Read table as characters
colnames(uni) <- c("Datum","Uhrzeit") # give names to colums
uni$Datum <- strptime(uni$Datum,format="%Y%m%d") # turn into format DATE
uni$Uhrzeit <- strptime(uni$Uhrzeit, format="%H%M%S") # turn into format TIME
#
plot(privat, col="darkgreen", xlim=c(as.POSIXct(strptime("20020801",format="%Y%m%d")), as.POSIXct(strptime("20120701",format="%Y%m%d"))))
points(lecture, col="red")
points(uni, col="darkblue")
legend("bottomleft",legend=c("Privat","Lectures","Uni"),fill=c("darkgreen","red","darkblue"),inset=.03)Das sieht dann in etwa so aus 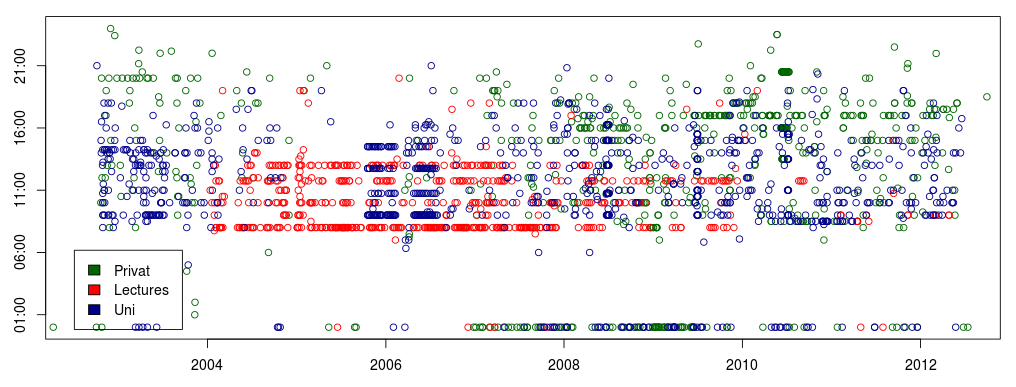
…
Weitere Codeschnipsel sammle ich in diesem Gist.