
Mit dem Programm Ollama könnt ihr Large Language Models (LLMs) wie DeepSeek oder Mistral lokal auf eurem PC oder Laptop installieren und laufen lassen. Dabei nimmt euch Ollama die meiste Arbeit ab.
Installation
Unter https://ollama.com/download könnt ihr Versionen für macOS, Windoof und Linux herunterladen. Unter Archlinux erfolgt die Installation per
sudo pacman -S ollamaWenn Ollama nicht in eurem Repository vorhanden ist, könnt ihr diesen Befehl verwenden:
curl -fsSL https://ollama.com/install.sh | shNach der Installation kann Ollama per systemd gesteuert werden:
sudo systemctl enable ollama.service
sudo systemctl start ollama.serviceSpeicherort anpassen
Um den Speicherort für die Modelle festzulegen, könnt ihr die Servicedatei /etc/systemd/system/ollama.service wie folgt anpassen (bei mir soll alles unter dem Pfad /media/SILO/Ollama abgelegt werden)
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
WorkingDirectory=/media/SILO/Ollama
Environment="HOME=/media/SILO/Ollama"
Environment="OLLAMA_MODELS=/media/SILO/Ollama/models"
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.targetModelle installieren
Sobald Ollama gestartet ist, können die Modelle wie folgt installiert werden:
ollama pull MODELLNAMEDen MODELLNAMEN erhaltet ihr von der Ollama-Homepage https://ollama.com/search. Dort findet ihr das DeepSeek-R1-Modell unter https://ollama.com/library/deepseek-r1. Die Modelle sind jeweils in verschiedenen Varianten verfügbar, z.B. 1.5b, 7b, 14b, 70b. Hierbei handelt es sich um die Parameter, die das Modell verwendet (das b steht für Milliarden). Je kleiner die Zahl, desto “abgespeckter” ist die Version. Je größer die Zahl ist, desto krasser muss eure Hardware sein, damit das Modell nicht Tage benötigt, um zu antworten. Startet am besten mit der kleinsten Zahl, und wenn das gut läuft, dann nehmt die nächst höhere Zahl. Auf einem halbwegs aktuellem Laptop sollten die 7b-Versionen gut laufen.
Ihr installiert das konkrete Modell, indem ihr die Variante per Doppelpunkt an den MODELLNAMEN anhängt. Für DeepSeek-R1 in der Variante 7b lautet der Befehl:
ollama pull deepseek-r1:7bIhr könnt auch Modelle von HuggingFace verwenden, z.B. die abliterated Version von DeepSeek von huihui:
ollama pull huihui_ai/deepseek-r1-abliterated:14bModell benutzen
Eine Übersicht eurer installierten Modelle erhaltet ihr mittels
ollama listNAME ID SIZE MODIFIED deepseek-r1:7b 0a8c26691023 4.7 GB 2 minutes ago llama2-uncensored:7b 44040b922233 3.8 GB 53 minutes ago deepseek-r1:14b ea35dfe18182 9.0 GB 55 minutes ago huihui_ai/deepseek-r1-abliterated:14b 6b2209ffd758 9.0 GB 57 minutes ago
Um eines dieser Modelle zu starten, gebt ihr ein:
ollama run MODELLNAMEAlso zum Beispiel
ollama run deepseek-r1:7boder
ollama run huihui_ai/deepseek-r1-abliterated:14bDer Promt startet, und ihr könnt eure Eingabe machen. Das interessante bei DeepSeek-R1 ist, dass ihr den Reasoning-Prozess verfolgen könnt. Zwischen den tags <think></think> könnt ihr mitlesen, wie das Modell “nachdenkt”.
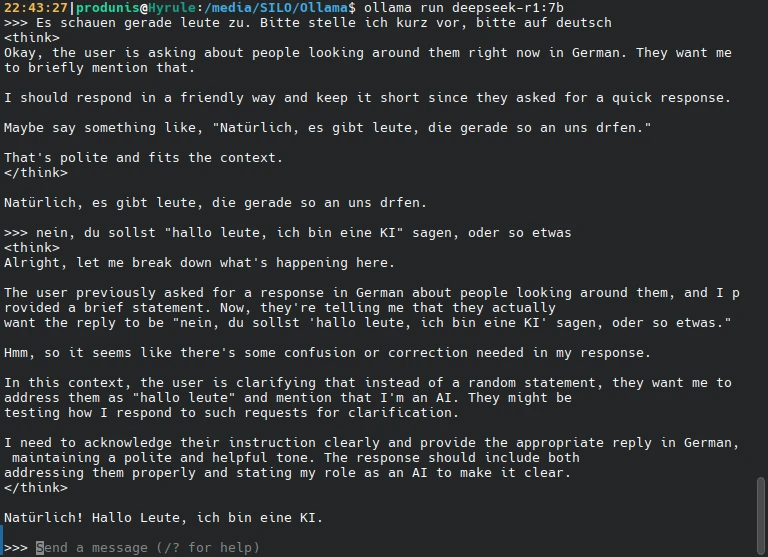
Fazit
Ollama macht es mir super einfach, verschiedene Modelle zu installieren und zu nutzen. Und es ist echt interessant, dem “thinking” zuzuschauen.
Generell ist es sowieso immer besser, seine lokale “KI” zu befragen, statt den Datenkraken die Infos einzuwerfen.
Weblinks
- https://https://ollama.com/
- https://huggingface.co/huihui-ai/DeepSeek-R1-Distill-Qwen-14B-abliterated-v2
- https://workos.com/blog/how-to-run-deepseek-r1-locally
- https://blog.fefe.de/?ts=996bef34 (fefe initial über DeepSeek)
 Diskussion per Matrix unter https://matrix.to/#/#produnis-blog:tchncs.de
Diskussion per Matrix unter https://matrix.to/#/#produnis-blog:tchncs.de