Das Anscombe-Quartett ist hervoragend geeignet, um Studierenden die Wichtigkeit von graphischen Auswertungen neben statistischen Kennzeichen zu verdeutlichen.
Professor Hastig
R
ubuntuusers
Autor:in
Joe Slam
Veröffentlichungsdatum
15. Oktober 2023
Ich verwende in der Lehre gerne das Anscombe-Quartett, welches der englische Statistiker Francis Anscombe im Jahr 19731 vorgestellt hat.
Es besteht aus 4 kleinen Datensätzen mit jeweils 11 Beobachtungen von 2 Variablen (x, y). Der Datensatz ist u.a. bei Wikipedia erhältlich, aber auch direkt in R implementiert.
# aktiviere den Datensatzdata("anscombe")# Daten anzeigenanscombe
Das Anscombe-Quartett ist hervoragend geeignet, um Studierenden die Wichtigkeit von graphischen Auswertungen neben statistischen Kennzeichen zu verdeutlichen.
Vorbereitung
Ich teile die Studierenden in 4 Gruppen auf, und jede Gruppe erhält einen Anscombe-Datensatz.
Jetzt sollen die Gruppen für ihren Datensazt jeweils auf 2 Stellen gerundet
den Mittelwert
die Standardabweichung
den Korrelationskoeffizienten nach Pearson
die Formel der linearen Regressionsgeraden
berechnen, sowie eine Punktwolke mit Regressionsgeraden zeichnen.
statistische Kennzeichen
Wenn die Gruppen wieder zusammenkommen und ihre Ergebnisse präsentieren, gibt es bei den statistischen Kennwerten den ersten Aha-Moment.
Gruppe 1
round(mean(Gruppe1$x),2)
[1] 9
round(sd(Gruppe1$x),2)
[1] 3.32
round(mean(Gruppe1$y),2)
[1] 7.5
round(sd(Gruppe1$y),2)
[1] 2.03
round(cor(Gruppe1$x,Gruppe1$y),2)
[1] 0.82
fit <-lm(Gruppe1$y~Gruppe1$x)round(fit$coefficients,2)
(Intercept) Gruppe1$x
3.0 0.5
Gruppe 2
round(mean(Gruppe2$x),2)
[1] 9
round(sd(Gruppe2$x),2)
[1] 3.32
round(mean(Gruppe2$y),2)
[1] 7.5
round(sd(Gruppe2$y),2)
[1] 2.03
round(cor(Gruppe2$x,Gruppe2$y),2)
[1] 0.82
fit <-lm(Gruppe2$y~Gruppe2$x)round(fit$coefficients,2)
(Intercept) Gruppe2$x
3.0 0.5
Gruppe 3
round(mean(Gruppe3$x),2)
[1] 9
round(sd(Gruppe3$x),2)
[1] 3.32
round(mean(Gruppe3$y),2)
[1] 7.5
round(sd(Gruppe3$y),2)
[1] 2.03
round(cor(Gruppe3$x,Gruppe3$y),2)
[1] 0.82
fit <-lm(Gruppe3$y~Gruppe3$x)round(fit$coefficients,2)
(Intercept) Gruppe3$x
3.0 0.5
Gruppe 4
round(mean(Gruppe4$x),2)
[1] 9
round(sd(Gruppe4$x),2)
[1] 3.32
round(mean(Gruppe4$y),2)
[1] 7.5
round(sd(Gruppe4$y),2)
[1] 2.03
round(cor(Gruppe4$x,Gruppe4$y),2)
[1] 0.82
fit <-lm(Gruppe4$y~Gruppe4$x)round(fit$coefficients,2)
(Intercept) Gruppe4$x
3.0 0.5
Alle Gruppen haben die selben (zugegeben gerundeten) Kennwertergebnisse ausgerechnet, obwohl die Datensätze unterschiedlich sind. Das sorgt häufig für Erstaunen und führt zu ersten Diskussionen.
graphische Darstellung
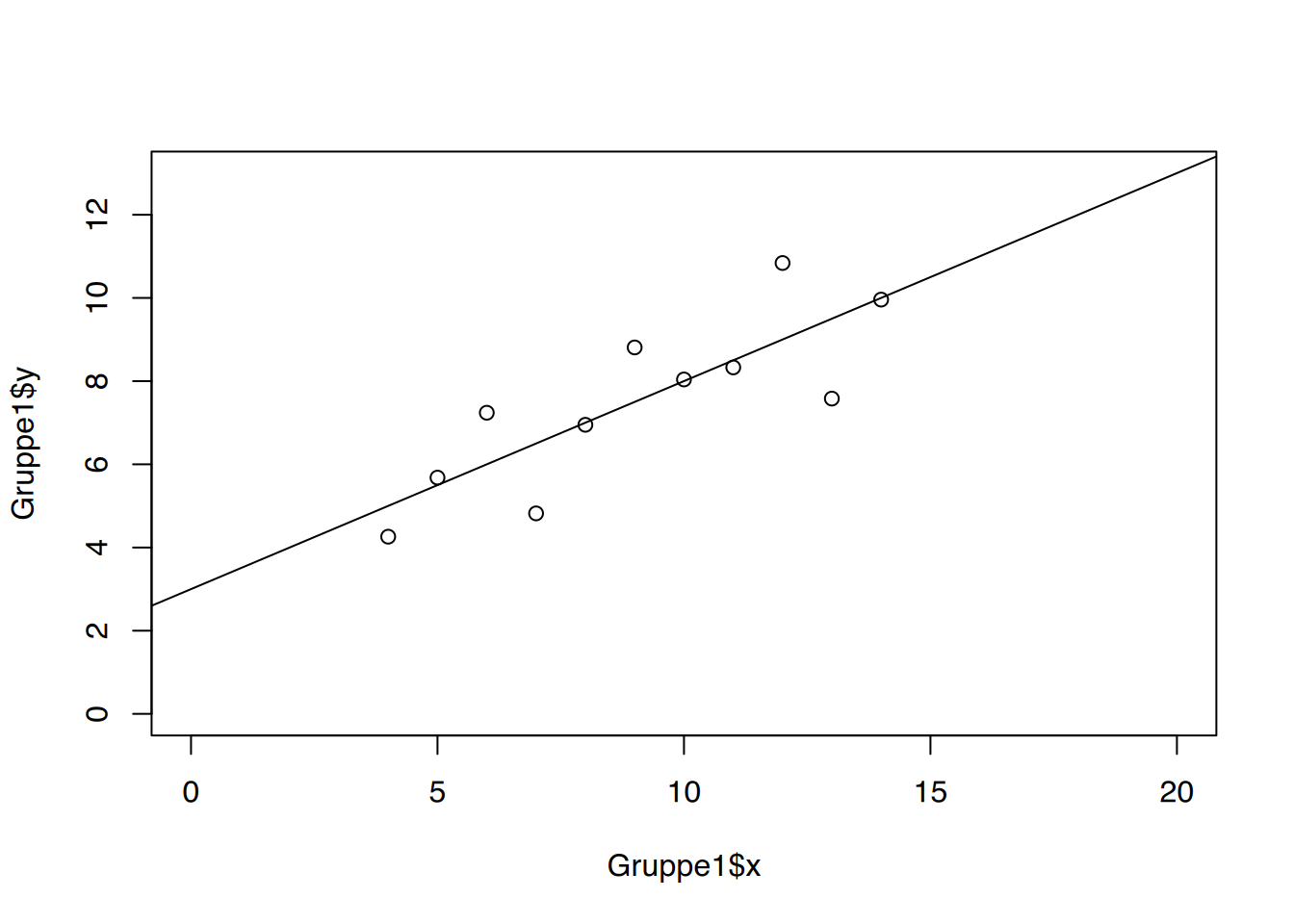
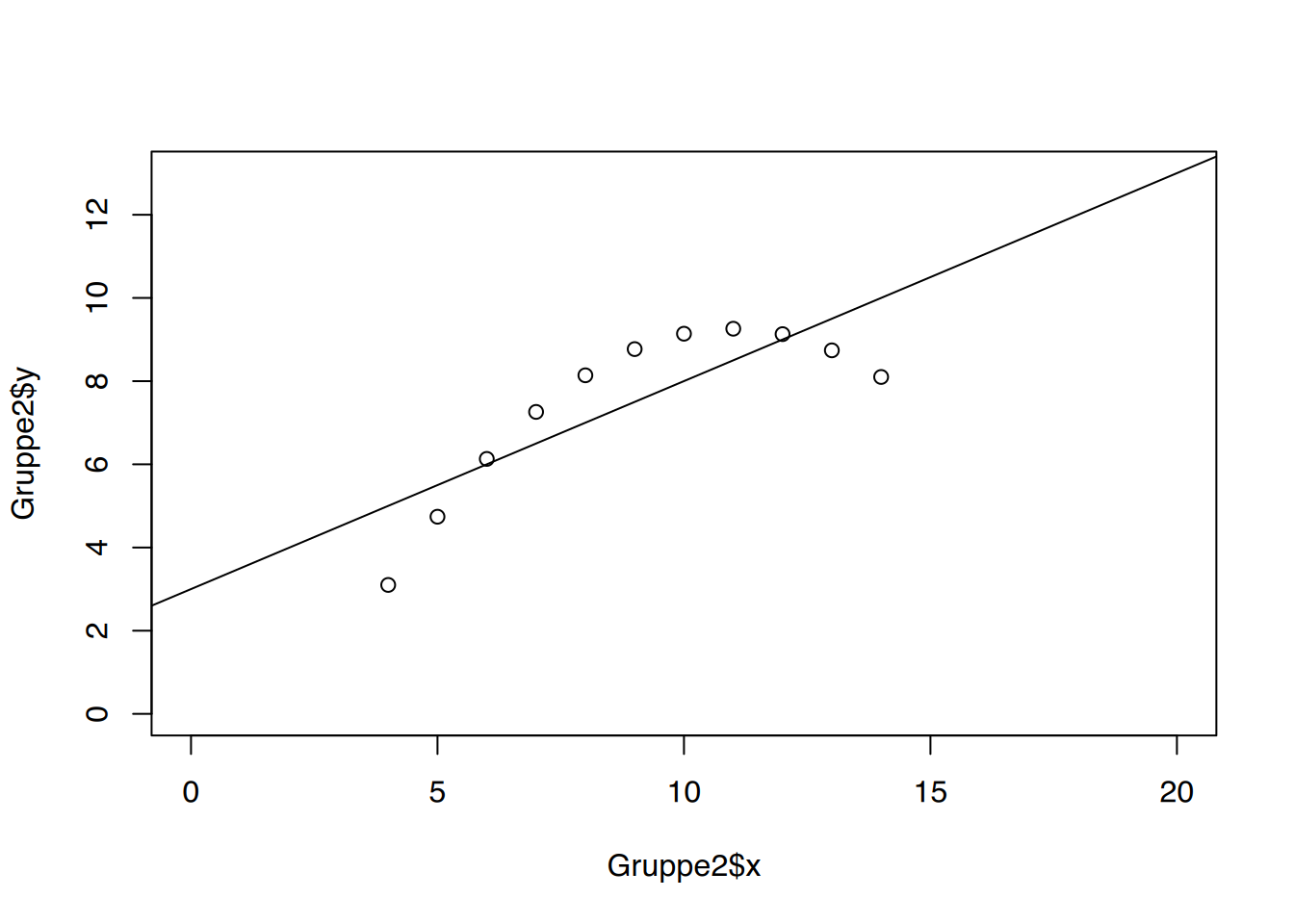
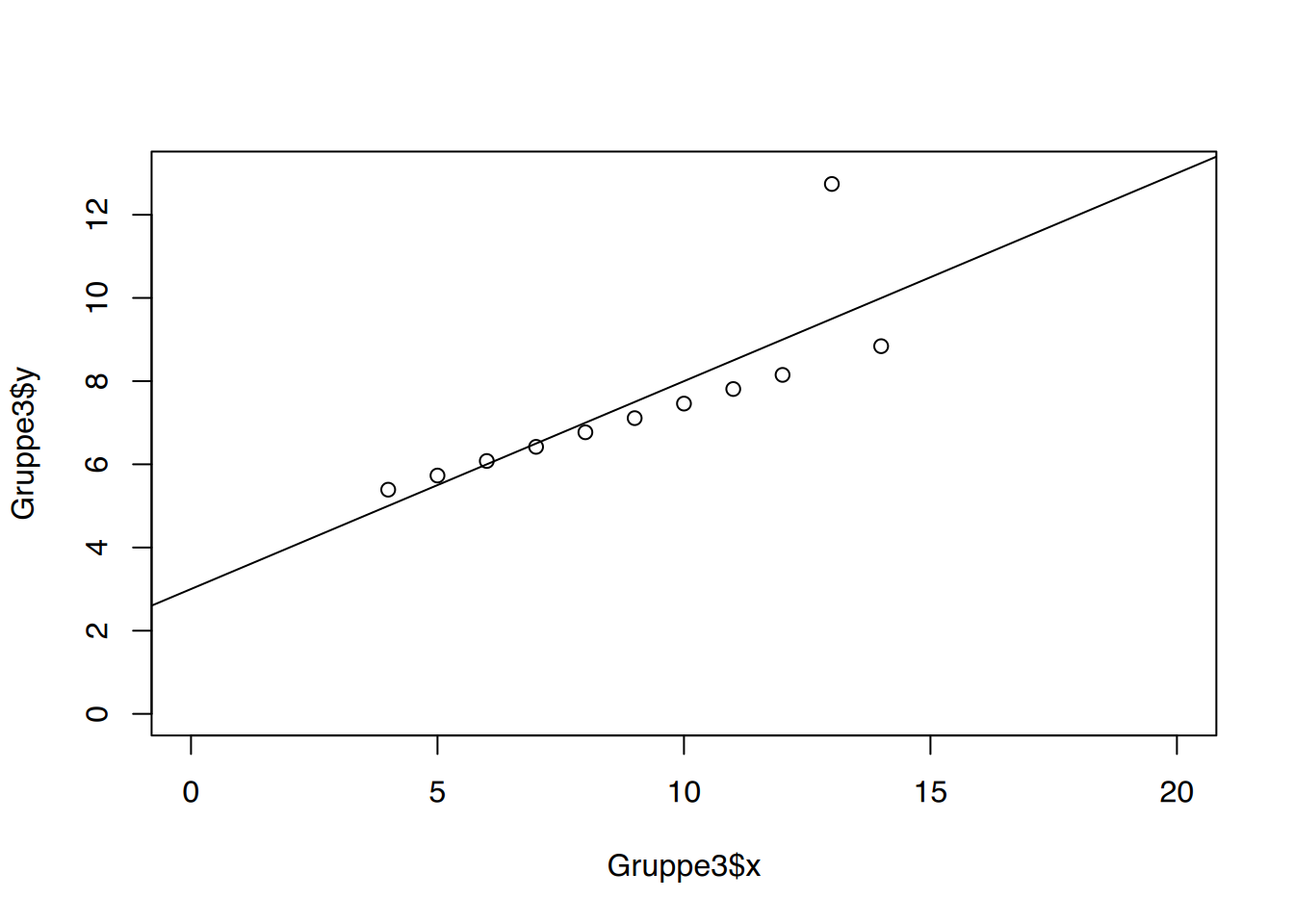
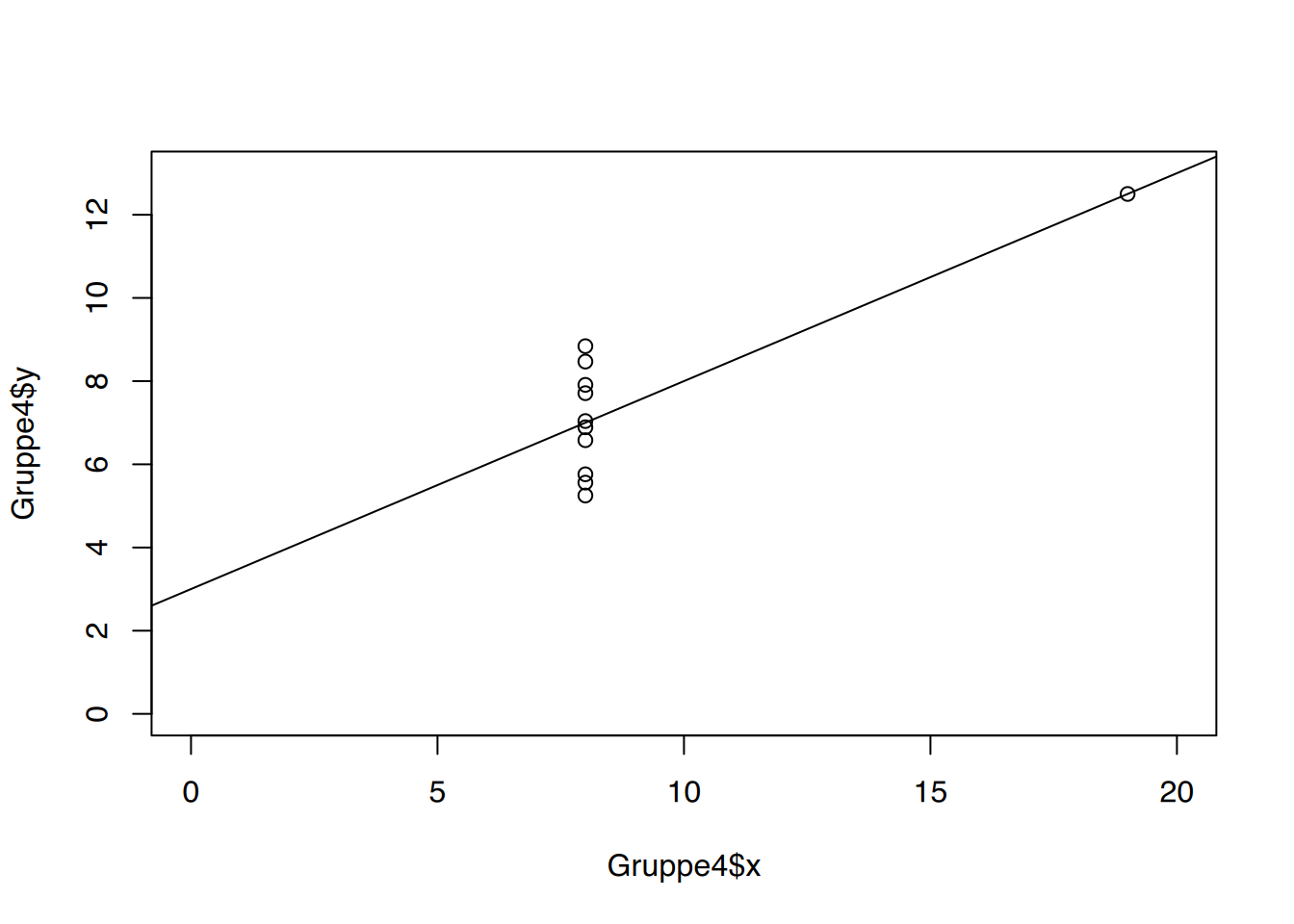
Spannend wird es dann nochmal, wenn die Punktwolken verglichen werden.
Alle Diagramme sehen unterschiedlich aus, und ihre Darstellung regt weitere Diskussionen an:
Diagramm 1 sieht aus wie ein klassisches Streudiagramm. Die lineare Regressionsgerade sieht passend aus, die Variablen scheinen zu korrelieren. Hier ist alles in Ordnung.
Diagramm 2 lässt erkennen, dass der Zusammenhang zwischen x und y nicht linear ist. Somit lassen sich keine Korrelationen oder lineare Regressionen auf die Daten anwenden.
Diagramm 3 zeigt einen deutlichen Ausreisser, der die Ergebnisse von Korrelation und Regression verzerrt.
Diagramm 4 zeigt ebenfalls einen deutlichen Ausreisser, während alle anderen y-Werte im selben x übereinander liegen. Ohne den Ausreisser wäre keine Korrelation oder Regression rechenbar.
Diskussion
Mit dieser kleinen Übung gelingt es häufig, Studierenden die Wichtigkeit der graphischen Datenanalyse nahezulegen, die vor der eigentlichen statistischen Auswertung erfolgen sollte. Statistische Kennzahlen reichen nicht aus, um die Daten ausreichend zu beschreiben.
heutzutage
Heutzutage ist es mit Hilfe von evolutionären Algorithmen möglich, weit komplexere Datensätze zu erzeugen, die in ihren Kennwerten übereinstimmen, deren Streudiagramme aber beliebige Formen annehmen können.
F. J. Anscombe: Graphs in Statistical Analysis. In: American Statistician. 27. Jahrgang, Nr. 1, 1973, S. 17–21↩︎
Matejka, J., & Fitzmaurice, G. (2017). Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing. Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, 1290–1294. https://doi.org/10.1145/3025453.3025912↩︎